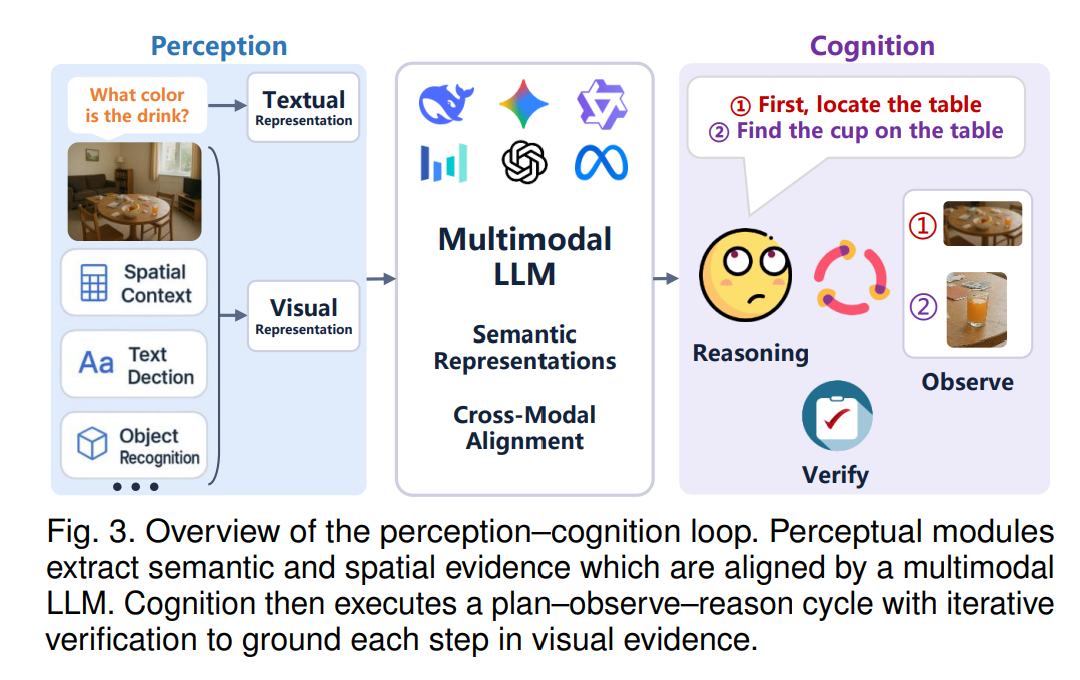
摘要—— 多模态大语言模型(Multimodal Large Language Models, MLLMs)旨在实现对物理世界深刻且类人般的理解与交互,但在信息获取(感知,Perception)与推理(认知,Cognition)之间往往表现出浅层且不连贯的整合。这种脱节导致了一系列推理失败,其中最突出的就是幻觉(hallucination)。总体而言,这些问题揭示了一个根本性挑战:处理像素的能力尚不足以赋予模型构建连贯且可信的内部世界模型的能力。为系统剖析并应对这一挑战,本综述提出了一个新颖且统一的分析框架——“从感知到认知”。我们将视觉-语言交互理解的复杂过程分解为两个相互依赖的层次:感知,即准确提取视觉信息并与文本指令实现细粒度对齐的基础能力;认知,即建立在感知基础之上的高阶能力,能够进行主动的、多步的、目标导向的推理,其核心是形成一个动态的“观察-思考-验证”推理循环。在该框架的指导下,本文系统分析了当前 MLLMs 在两个层次上的关键瓶颈,并综述了旨在应对这些挑战的前沿方法,涵盖从增强低层视觉表征到改进高层推理范式的技术。此外,我们还回顾了关键基准数据集并勾勒了未来研究方向。本综述旨在为研究社区提供一个清晰且结构化的视角,以理解当前 MLLMs 的内在局限,并为构建具备深度推理和真正理解世界的下一代模型指明道路。 关键词—— 多模态大语言模型(MLLMs),交互式视觉-语言推理,感知与认知
1 引言
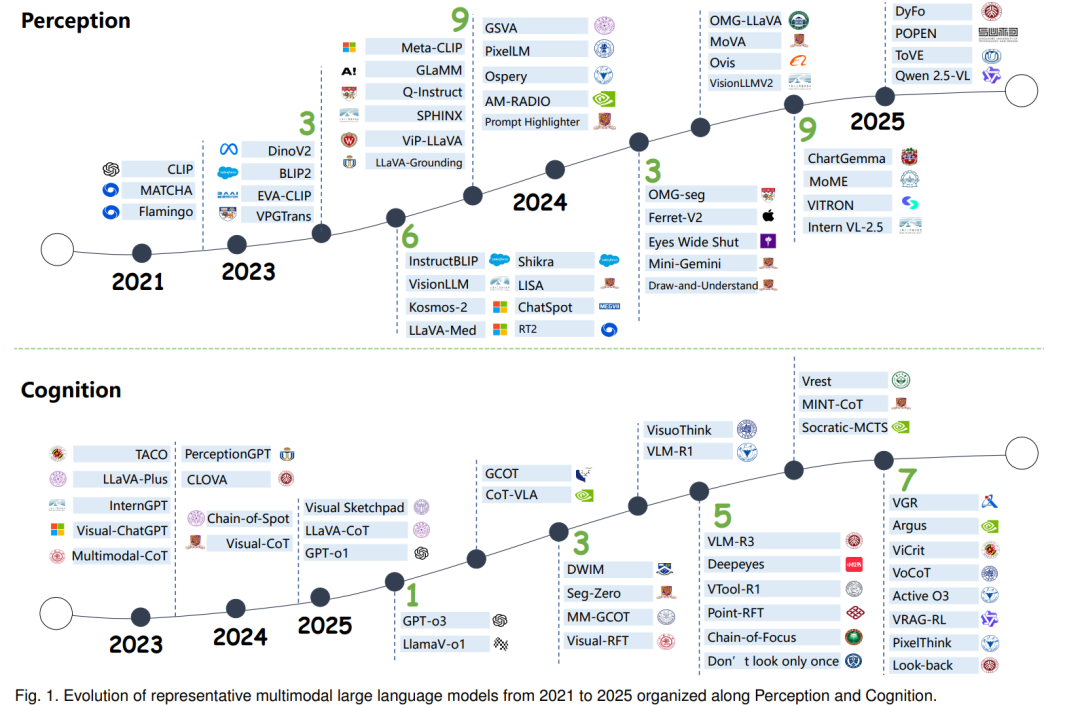
多模态大语言模型(Multimodal Large Language Models, MLLMs)的快速发展,正推动人工智能迈向其长期目标——通用人工智能(Artificial General Intelligence, AGI)[1], [2], [3], [4]:即创造能够以类人方式感知、推理并与物理世界交互的智能体 [5], [6], [7], [8]。这一进展的核心在于将大语言模型(LLMs)[9], [10] 的复杂符号推理能力与计算机视觉(CV)基础模型 [11], [12] 的强大感知能力深度融合。一方面,LLMs(如 GPT 系列 [13])通过在大规模文本语料上的预训练,习得了广博的世界知识与强大的逻辑推理能力。然而,它们本质上局限于纯粹的符号空间,作为“盲目”的推理器,脱离了物理世界的感官丰富性。另一方面,视觉基础模型如 CLIP [11] 已成功将视觉与语言模态映射到统一的嵌入空间 [14], [15],实现了前所未有的感知泛化能力。然而,它们通常缺乏复杂多步推理所需的深层认知能力。 多模态大语言模型(MLLMs)的出现,标志着将这两类能力整合的初步探索。在早期的“探索阶段”(Exploration Phase, How to Connect?)中,以 Flamingo [16] 和 LLaVA [17] 等开创性工作为代表,核心挑战是技术性的:如何高效地将视觉编码器与 LLM 连接起来。当时研究社区主要集中于解决架构设计与特征对齐等基础性工程问题,目标是确保这种连接可行。然而,即便在众多基准任务上取得进展,这些模型在面对需要细粒度感知与复杂推理的场景时,其脆弱性也暴露无遗。这具体体现在最新模型 [18], [19], [20], [21], [22](如 Qwen2.5-VL [23]、InternVL 2.5 [24]、GPT-4o [25])中普遍存在的问题:它们经常误解视觉细节(感知缺陷),且无法维持连贯的逻辑链条(认知缺陷)[15], [26]。因此,研究重心逐渐转向一条系统化的发展路径——从“感知”到“认知”。尤其是,先建立精确的感知层作为构建高级认知的前提,已逐渐成为提升 MLLMs 能力的共识 [15], [27]。 为系统性地描绘这一演进轨迹,本综述提出“从感知到认知”框架作为统一的分析视角。该框架将视觉-语言交互推理的复杂过程拆解为两个既独立又互相关联的层次。第一层是感知,即准确提取视觉信息并与文本指令实现细粒度对齐的基础能力。这不仅需要识别对象、属性与关系,还要求将文本概念精准地落地到具体视觉细节。第二层是认知,即建立在感知之上的高阶能力,能够执行主动的、目标导向的、多步推理。这涉及将复杂问题分解为逻辑步骤,并且关键地,能够动态地重新检视视觉证据,以验证或修正推理路径,从而形成一个“观察–思考–验证”的反馈循环。如图 1 所示,我们基于感知与认知这两大核心支柱,梳理了 2021–2025 年 MLLMs 的发展脉络。 借助这一框架,本综述对交互式视觉-语言推理中的关键问题、方法学、基准任务及未来方向进行了结构化和系统性的回顾。我们的综述首先分析了推动该领域进展的感知层与认知层核心挑战。随后,回顾了旨在增强感知的前沿方法(如先进的视觉编码器)以及旨在强化认知的技术(如复杂的 Chain-of-Thought 范式与动态推理机制)。通过采用“从感知到认知”的视角,我们旨在揭示现有模型的局限,并描绘技术演进的路径。
1.1 本文综述结构
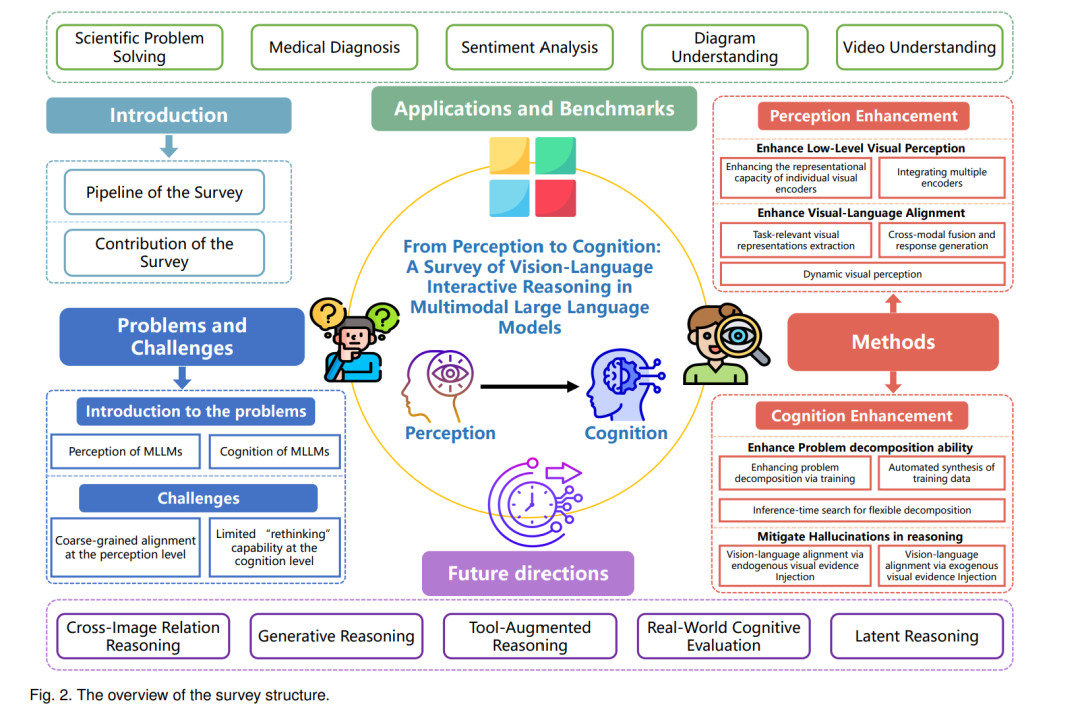
本综述对多模态大语言模型中交互式视觉-语言推理的关键问题、方法学、基准与未来方向进行了全面梳理。如图 2 所示,全文结构如下: * 第 2 节 概述视觉-语言交互中的基本问题。我们首先定义“感知”(第 2.1 节)与“认知”(第 2.2 节),然后基于这一框架分析 MLLMs 在这两个维度面临的主要挑战(第 2.3 节)。 * 第 3 节 回顾相关方法的演进,依照其所解决的挑战在“感知–认知”框架下进行组织。感知层面,我们探讨增强细粒度视觉能力(第 3.1 节)与改进视觉-语言对齐(第 3.2 节)的技术;认知层面,我们分析提升问题分解能力(第 3.3 节)及通过动态推理机制缓解幻觉(第 3.4 节)的研究。 * 第 4 节 重点分析关键基准与应用,涵盖科学问题求解、医学诊断、图表理解与视频推理等多领域任务,并评估当前模型在感知与认知能力平衡上的表现。 * 第 5 节 总结全文并探讨未来研究方向,包括潜在空间推理、生成式推理与工具增强推理等新兴范式,指出其可能如何进一步弥合感知与认知之间的鸿沟。
1.2 本文贡献
近年来,多模态大语言模型的综述论文激增,各自提供了对这一快速发展领域的独特视角。其中,Yin 等 [28] 最早在 2024 年初对 MLLMs 的发展进行了基础性综述。后续的研究逐渐专门化:一些综述聚焦于推理,分析增强逐步“慢思考”的方法 [29], [30];另一些近期的综述 [31], [32], [33] 则集中于“带图像的思考”主题,系统分析了细粒度视觉推理的进展。 尽管这些工作提供了宝贵见解,但大多要么聚焦于 MLLM 的通用架构,要么聚焦于高层推理的特定方面。相比之下,本文综述的独特之处在于采用了一种更基础的视角,将交互式推理分解为两个核心且相互依赖的组成部分:感知与认知。基于此,我们的主要贡献如下: * 新颖的分析框架:提出“感知–认知”框架,提供结构化的视角以理解视觉-语言交互中的根本挑战。该框架超越了任务或模型的表层分类,能够将幻觉等模型失败的根本原因映射到感知或认知层面的特定缺陷。 * 结构化的方法学分类:基于该框架,我们提出了系统且一致的方法学分类,展示了看似离散的研究方向(如增强视觉编码器与发展高级 Chain-of-Thought)实则是为解决“感知–认知连续体”上不同问题的针对性努力,从而澄清不同研究脉络间的关系。 * 统一的 MLLM 发展视角:通过沿“感知–认知”轴展开分析,本文明确揭示了高层推理对低层视觉表征质量的根本依赖性。我们将两者重新定位为 MLLMs 演进过程中的两个连续阶段,而非孤立的研究领域。这一统一视角提供了整体性的研究路线图,表明感知方面的突破是认知突破的必要前提。