

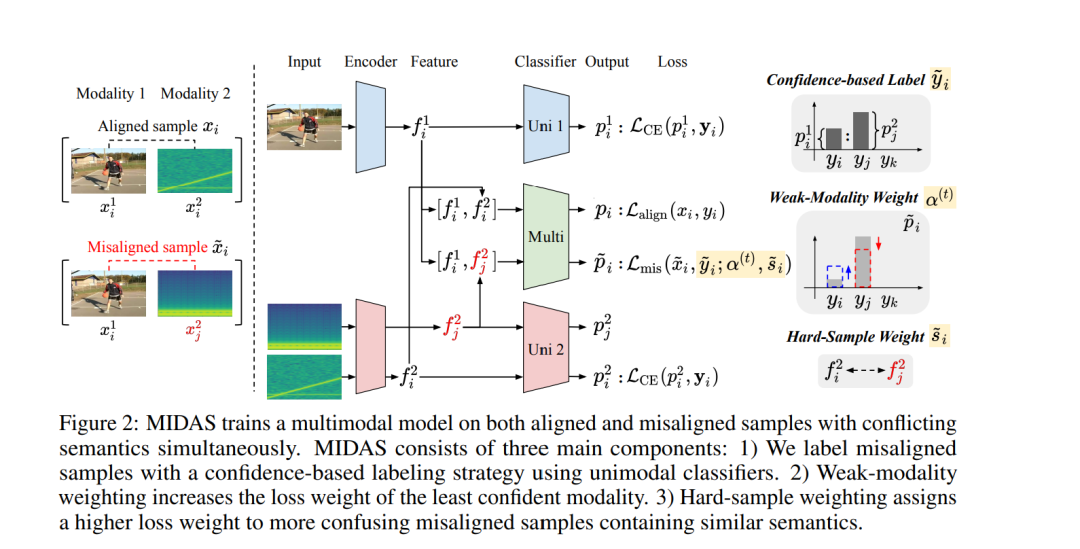
多模态模型往往过度依赖优势模态,因而无法实现最佳性能。以往的研究主要集中在修改训练目标或优化过程,而基于数据的解决方案仍然探索不足。为此,我们提出 MIDAS,一种新颖的数据增强策略,其核心思想是生成跨模态语义不一致的错配样本,并利用单模态置信度分数进行标注,从而迫使模型在矛盾信号中学习。然而,这种基于置信度的标注仍可能偏向于更自信的模态。为了解决这一问题,我们在错配样本中引入了弱模态加权机制,该机制动态地增加最不自信模态的损失权重,从而帮助模型充分利用较弱的模态。 此外,当错配特征与对齐特征表现出更高相似度时,这些错配样本往往构成更大的挑战,从而促使模型更好地区分类别。为了利用这一特性,我们提出了难样本加权方法,该方法优先考虑此类语义上更模糊的错配样本。 在多个多模态分类基准上的实验表明,MIDAS 在解决模态失衡问题上显著优于相关基线方法。
成为VIP会员查看完整内容
相关内容

神经信息处理系统年会(Annual Conference on Neural Information Processing Systems)的目的是促进有关神经信息处理系统生物学,技术,数学和理论方面的研究交流。核心重点是在同行会议上介绍和讨论的同行评审新颖研究,以及各自领域的领导人邀请的演讲。在周日的世博会上,我们的顶级行业赞助商将就具有学术意义的主题进行讲座,小组讨论,演示和研讨会。星期一是教程,涵盖了当前的问询,亲和力小组会议以及开幕式演讲和招待会的广泛背景。一般会议在星期二至星期四举行,包括演讲,海报和示范。
官网地址:http://dblp.uni-trier.de/db/conf/nips/
