
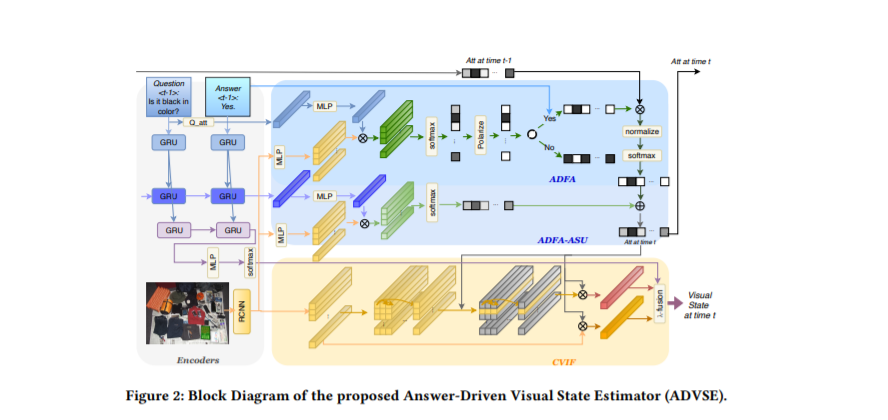
面向目标的视觉对话包括两个代理者,提问者和Oracle之间的多回合交互。在此期间,Oracle给出的答案是非常重要的,因为它为提问者所关心的问题提供了黄金回答。在回答的基础上,提问者更新了对目标视觉内容的信念,进而提出了另一个问题。值得注意的是,不同的答案会导致不同的视觉信念和未来问题。但是,现有的方法往往是在问题长得多的情况下对答案进行不加区分的编码,导致对答案的利用率较低。在本文中,我们提出了一个答案驱动的视觉状态估计器(ADVSE),以施加不同的答案对视觉状态的影响。首先,我们提出了一种基于回答驱动的聚焦注意力(ADFA),通过在每个回合强化与问题相关的注意力并通过基于回答的逻辑操作来调整注意力,来捕捉对视觉注意力的回答驱动效应。然后在聚焦注意力的基础上,通过条件视觉信息融合(CVIF)对问题-应答状态进行融合,得到整体信息和差异信息的视觉状态估计。
成为VIP会员查看完整内容
相关内容

专知会员服务
78+阅读 · 2020年2月25日
专知会员服务
48+阅读 · 2019年11月25日
Arxiv
5+阅读 · 2018年4月25日
相关主题
相关VIP内容
专知会员服务
78+阅读 · 2020年2月25日
专知会员服务
48+阅读 · 2019年11月25日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年4月25日