
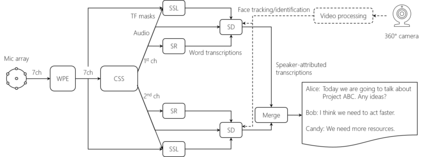
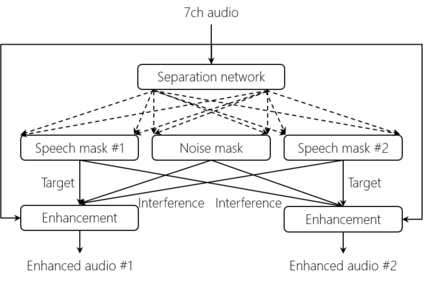
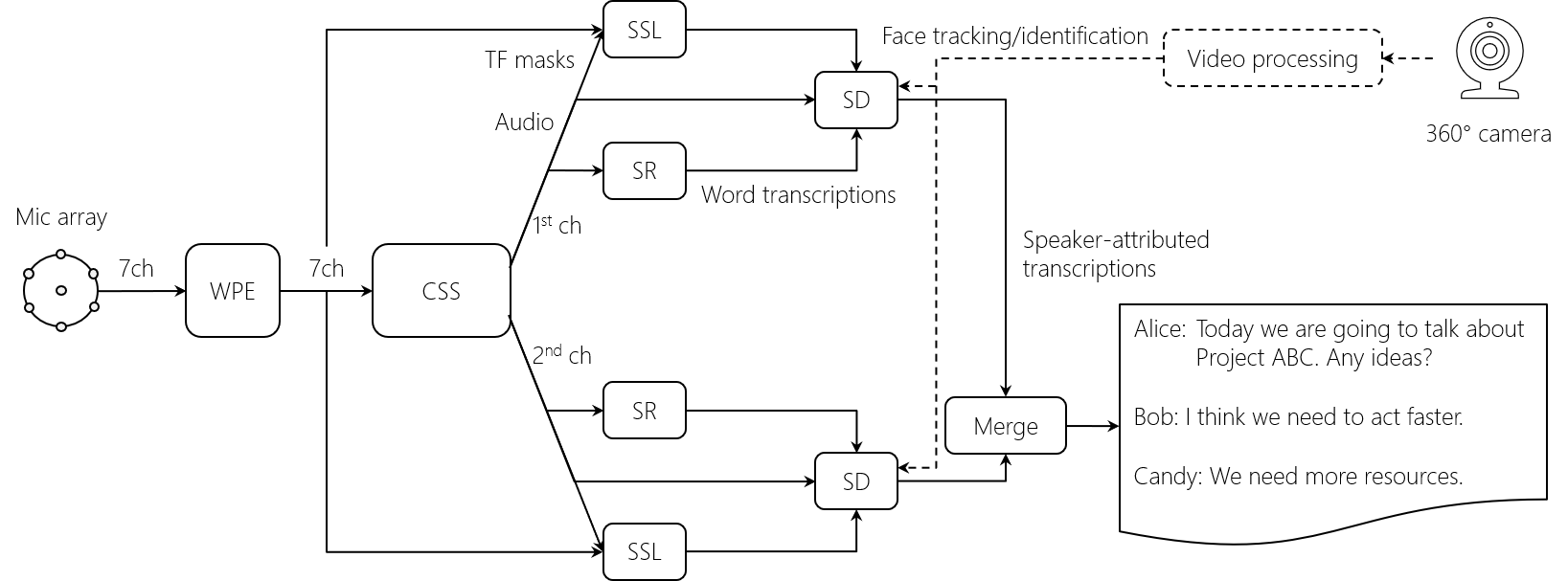
This paper describes a system that generates speaker-annotated transcripts of meetings by using a microphone array and a 360-degree camera. The hallmark of the system is its ability to handle overlapped speech, which has been an unsolved problem in realistic settings for over a decade. We show that this problem can be addressed by using a continuous speech separation approach. In addition, we describe an online audio-visual speaker diarization method that leverages face tracking and identification, sound source localization, speaker identification, and, if available, prior speaker information for robustness to various real world challenges. All components are integrated in a meeting transcription framework called SRD, which stands for "separate, recognize, and diarize". Experimental results using recordings of natural meetings involving up to 11 attendees are reported. The continuous speech separation improves a word error rate (WER) by 16.1% compared with a highly tuned beamformer. When a complete list of meeting attendees is available, the discrepancy between WER and speaker-attributed WER is only 1.0%, indicating accurate word-to-speaker association. This increases marginally to 1.6% when 50% of the attendees are unknown to the system.
翻译:本文描述一个使用麦克风阵列和360度照相机生成配有语音注释的会议记录誊本的系统,该系统的特点是能够处理重叠的演讲,这在现实环境中已经是十多年来一个尚未解决的问题。我们表明,这个问题可以通过连续的语音分离方法加以解决。此外,我们描述了一种在线视听演讲的分化方法,该方法可以借助于跟踪和识别、声源本地化、发言者身份识别,以及如果有的话,预先的发言者信息,以稳健应对各种现实世界挑战。所有组成部分都被纳入一个称为SRD的会议记录框架,即SRD,它代表“分离、识别和分化”。 使用涉及多达11名与会者的自然会议的记录,来进行实验结果。连续的语音分离使单词错误率提高了16.1%,而光线显示高度调。如果有完整的与会人员名单,WER与发言者所属WER之间的差异仅为1.0%,表明“单词对发言人”协会的准确度为1.6%。当50%的参加者为未知时,这个系统将略增至1.6%。
相关内容

Source: Apple - iOS 8



