

此综述关注大型语言模型(LLMs)中的事实性关键问题。随着LLMs在各种领域的应用,它们输出的可靠性和准确性变得至关重要。我们将“事实性问题”定义为LLMs生成与既定事实不一致内容的概率。我们首先深入探讨这些不准确性的影响,强调LLM输出中事实性错误可能带来的潜在后果和挑战。随后,我们分析LLMs存储和处理事实的机制,寻找事实错误的主要原因。我们的讨论接着转向评估LLM事实性的方法,强调关键指标、基准和研究。我们进一步探索提高LLM事实性的策略,包括为特定领域量身定制的方法。我们关注两种主要的LLM配置—独立LLMs和利用外部数据的检索增强型LLMs—我们详细说明它们的独特挑战和潜在增强。我们的综述为旨在加强LLM事实可靠性的研究者提供了一个结构化指南。我们始终维护并更新相关的开源材料,地址为 https://github.com/wangcunxiang/LLM-Factuality-Survey。
https://www.zhuanzhi.ai/paper/13a31f8b059195351a1884fa473daa32
对知识掌握的追求一直是人工智能系统发展中的基础愿景。从历史上看,McCarthy等人(1955年)和Newell与Simon(1976年)的开创性工作都强调了知识表示和推理在AI系统中的重要性。例如,Cyc项目开始了一个雄心勃勃的旅程,旨在编码常识知识,希望为AI系统提供对世界的全面了解(Lenat, 1995年)。同时,像Miller等人(1990年)的WordNet项目致力于创建捕获单词之间语义关系的词汇数据库,从而帮助AI系统掌握人类语言的细微差别。 在这些开创性努力之中,Large Language Models(LLMs)的出现,如ChatGPT(OpenAI, 2022b),GPT-4(OpenAI, 2023)和LLaMA(Touvron等人,2023a,b),在学术界和工业界都被视为一个重大的飞跃,尤其是向着拥有大量事实知识的AI系统(OpenAI, 2022a, 2023)。使用LLMs作为知识库载体的优点是多种多样的。首先,它们减少了构建和维护专用知识库的开销和成本(AlKhamissi等人,2022;Petroni等人,2019c;Wang等人,2023b)。此外,LLMs提供了一种更灵活的知识处理和利用方法,允许进行上下文感知的推理,并具有适应新信息或提示的能力(Huang和Chang,2023;Sun等人,2023a)。然而,尽管它们具有无与伦比的能力,人们对LLMs生成的非事实性或误导性内容的可能性产生了担忧(Bender等人,2021;Bubeck等人,2023;OpenAI, 2023)。鉴于这些进展和挑战,本综述旨在深入探讨LLMs,探索它们的潜力以及围绕其事实准确性的关注。
了解大型语言模型的事实性不仅仅是一个技术挑战;对于我们在日常生活中负责任地使用这些工具来说,这是至关重要的。随着LLMs越来越多地融入到搜索引擎(Microsoft,2023)、聊天机器人(Google,2023; OpenAI,2022b)和内容生成器(Cui等人,2023b)等服务中,它们提供的信息直接影响着数百万人的决策、信仰和行动。如果一个LLM提供了不正确或误导性的信息,它可能导致误解、传播错误的信仰,甚至造成伤害,尤其是对于那些要求高事实准确性的领域(Ling等人,2023b),如健康(Tang等人,2023;Thirunavukarasu等人,2023)、法律(Huang等人,2023a)和金融(Wu等人,2023)。例如,一个依赖LLM进行医学指导的医生可能无意中危及患者健康,一个利用LLM洞察力的公司可能做出错误的市场决策,或一个被LLM误导的律师可能在法律程序中失误(Curran等人,2023)。此外,随着基于LLM的代理人的发展,LLMs的事实性变得更加强大。驾驶员或自动驾驶汽车可能依赖基于LLM的代理进行规划或驾驶,其中LLMs犯的严重事实错误可能造成不可逆转的损害。通过研究LLMs的事实性,我们的目标是确保这些模型既强大又值得信赖。
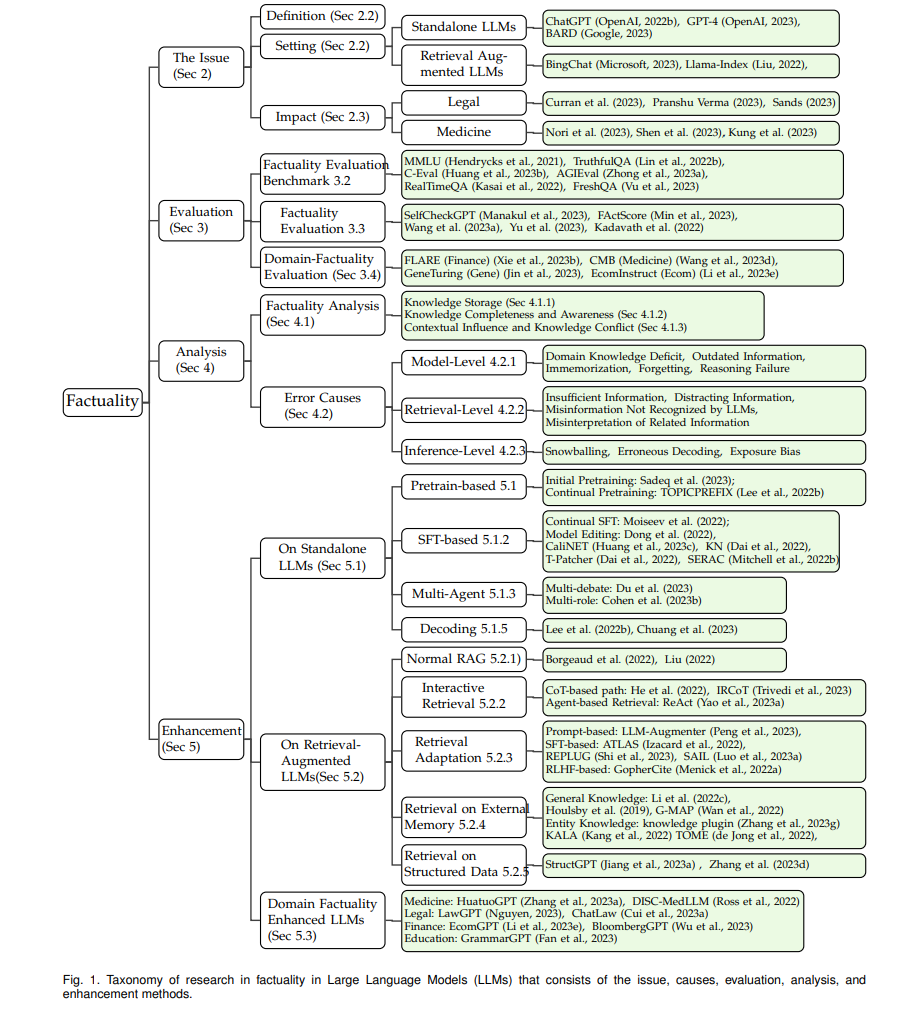
近年来,有大量的研究致力于评估LLMs的事实性,这包括像事实性问题回答和事实核查等多种任务。除了评估,努力提高LLMs的事实知识也很显著。策略的范围从从外部知识库检索信息到持续的预训练和有监督的微调。然而,尽管有这些日益增长的努力,对LLMs中的事实性进行全面概述仍然是个难题。虽然该领域存在一些调查,如Chang等人(2023年)和Wang等人(2023g年)深入研究了LLMs及其事实性的评估,但它们只触及了更广泛的领域的表面。还有一些最近的研究专注于LLMs中的错觉问题(Rawte等人,2023年; Ye等人,2023年; Zhang等人,2023f年)。但我们在第2.2节中区分了错觉问题和事实性问题。此外,这些调查经常忽视了我们强调的关键领域,如特定领域的事实性或过时信息的挑战。尽管Ling等人(2023a年)探讨了LLMs的领域专长,但我们的调查更加广泛地关注事实性的更广泛问题。
据我们了解,我们的工作是对大型语言模型事实性的首次全面研究。 这份综述旨在为LLMs中的事实性研究提供一个详尽的概览,深入探讨四个关键维度:第2节)事实性问题的定义和影响(Nori等人,2023;Pranshu Verma,2023);第3节)评估事实性的技术及其定量评估(Huang等人,2023b;Min等人,2023);第4节)分析LLMs中事实性的基本机制并确定事实错误的根本原因(Kotha等人,2023;Liu等人,2023b);以及第5节)提高LLMs事实性的方法(Du等人,2023;He等人,2022)。值得注意的是,我们将LLMs的使用分类为两种主要的设置:没有外部知识的LLMs,如ChatGPT(OpenAI,2022b)和检索增强型LLMs,如BingChat(Microsoft,2023)。这次调查的完整结构在图1中说明。通过对现有研究的详细检查,我们希望阐明LLMs的这一关键方面,帮助研究者、开发者和用户负责任和有效地利用这些模型的力量。 **增强 **
本节讨论在不同阶段增强LLMs事实性的方法,包括LLM生成、检索增强生成、推断阶段的增强以及特定领域的事实性改进,如图2所示。表7提供了增强方法的概要以及它们相对于基线LLM的改进情况。必须认识到,不同的研究论文可能采用不同的实验设置,如零射击、少数射击或完全设置。因此,在检查这个表格时,重要的是要注意,即使在评估同一数据集上的同一指标,不同方法的性能指标也可能不是直接可比的。
单独LLM生成 当关注单独的LLM生成时,增强策略可以大致分为三大类: (1) 从无监督语料库中提高事实知识(第5.1.1节):这涉及到在预训练期间优化训练数据,如通过去重和强调有信息性的词语(Lee等人,2022a)。还探讨了像TOPICPREFIX(Lee等人,2022b)和句子完成损失这样的技术来增强这种方法。 (2) 从监督数据中增强事实知识(第5.1.2节):这一类的例子包括监督微调策略(Chung等人,2022;Zhou等人,2023a),这些策略关注于从知识图谱(KGs)中整合结构化知识或对模型参数进行精确调整(Li等人,2023d)。 (3) 最佳地从模型中提取事实知识(第5.1.3节, 5.1.4节, 5.1.5节):这一类包括像多代理协作(Du等人,2023)和创新提示(Yu等人,2023)这样的方法。此外,还引入了像事实核心抽样这样的新颖解码方法,以进一步提高事实性(Chuang等人,2023;Lee等人,2022b)。
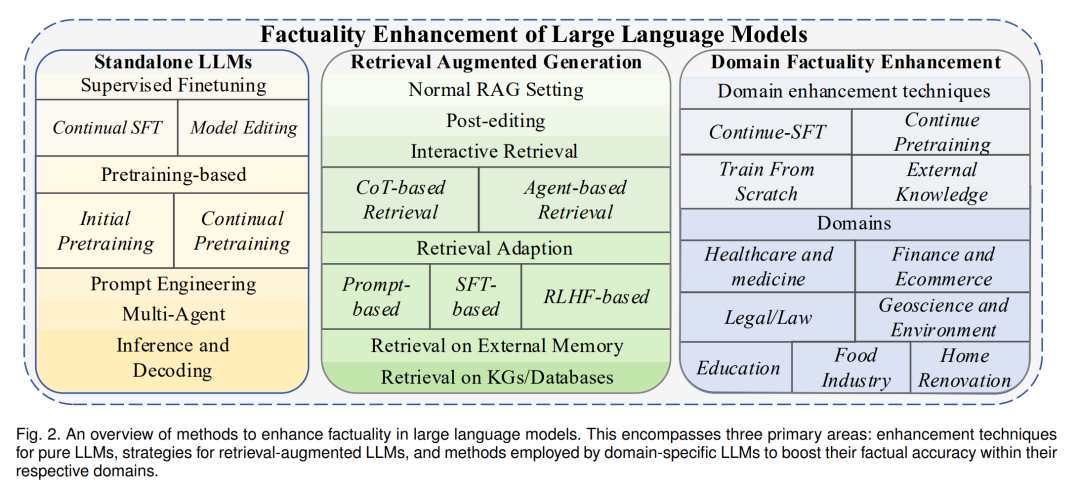
关于检索增强生成 检索增强生成(RAG)已经成为一种广泛采用的方法,用于解决独立LLMs固有的某些局限性,如过时的信息和无法记忆的问题(Chase,2022; Liu,2022)。这些挑战在第4.2.1节中详细讨论。然而,虽然RAG为某些问题提供了解决方案,但它也引入了自己的一系列挑战,包括信息不足的可能性和对相关数据的误解,如第4.2.2节中详细说明。本小节深入探讨了为缓解这些挑战而设计的各种策略。在检索增强生成的领域内,增强技术可以广泛地分为几个关键领域: (1) 利用检索文本进行生成的正常设置(第5.2.1节)。 (2) 交互式检索和生成(第5.2.2节):这里的例子包括将Chain-of-Thoughts步骤集成到查询检索中(He等人,2022),以及使用基于LLM的代理框架进入外部知识APIs(Yao等人,2023a)。 (3) 将LLMs适应到RAG设置(第5.2.3节):这涉及到像Peng等人提出的方法(2023),该方法结合了一个固定的LLM和一个即插即用的检索模块。另一个值得注意的方法是REPLUG(Shi等人,2023),一个检索增强框架,将LLM视为一个黑盒,并使用语言建模分数对检索模型进行微调。 (4) 从其他知识库中检索(第5.2.5节和第5.2.4节):这一类包括从外部参数记忆(Chen等人,2023a)或知识图(Zhang等人,2023d)检索的方法,以增强模型的知识库。 **领域事实增强的LLMs **
领域知识缺陷不仅是限制LLM在特定领域应用的重要原因,而且是学术界和工业界都非常关心的一个主题。在这个小节中,我们讨论了那些特定领域的LLMs是如何增强它们的领域事实性的。 表8列出了领域事实性增强的LLMs。在此,我们包括了几个领域,包括医疗健康(H)、金融(F)、法律/法规(L)、地球科学/环境(G)、教育(E)、食品检测(FT)和家居翻新(HR)。

结论
在这份综述中,我们系统地探讨了大型语言模型(LLMs)内部事实性问题的复杂景观。我们首先定义了事实性的概念(第2.2节),然后讨论了其更广泛的意义(第2.3节)。我们的旅程带领我们穿越了事实性评估的多面领域,包括基准(第3.2节)、指标(第3.1节)、特定评估研究(第3.3节)和特定领域的评估(第3.4节)。接着,我们深入探索,探讨了支撑LLMs中事实性的内在机制(第4节)。我们的探索在增强技术的讨论中达到高潮,既有纯LLMs(第5.1节)也有检索增强型LLMs(第5.2节),特别关注特定领域的LLM增强(第5.3节)。 尽管本综述中详细描述了许多进展,但仍有许多挑战。事实性的评估仍然是一个复杂的难题,由自然语言的固有变异性和细微差别使其变得复杂。关于LLMs如何存储、更新和产生事实的核心过程尚未完全揭示。尽管某些技术,如持续培训和检索,显示出了前景,但它们也不是没有局限性。展望未来,寻求完全基于事实的LLMs既带来挑战,也带来机会。未来的研究可能会深入了解LLMs的神经结构,开发更为强大的评估指标,并在增强技术上进行创新。随着LLMs日益融入我们的数字生态系统,确保其事实可靠性将始终是最重要的,这对AI社区及其更广泛的领域都有影响。