
课程题目
在线变分推断:A Regret Bound for Online Variational Inference
课程介绍
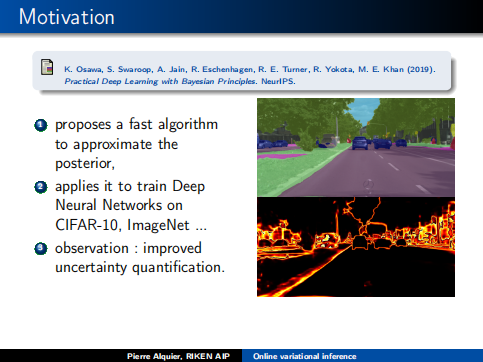
本课程重点讲述了在线变分推理在机器学习的强大之处,提出了一种近似后验的快速算法,将应用它在CIFAR-10、ImageNet上训练深层神经网络,改进不确定度量化。
课程作者
Badr-EddineChérief-Abdellatif,
Pierre Alquier,RIKEN高级情报中心项目贝叶斯近似推理小组研究员。
Emtiyaz Khan,东京RIKEN 高级智能项目(AIP)中心的团队负责人,东京农业科技大学(TUAT)电子工程系的客座教授。
成为VIP会员查看完整内容

相关内容

专知会员服务
54+阅读 · 2020年3月5日
专知会员服务
28+阅读 · 2020年2月18日
专知会员服务
57+阅读 · 2019年12月4日
专知会员服务
16+阅读 · 2019年11月30日
【变分推断课件】Lectures on Variational Inference: Approximate Bayesian Inference in Machine Learning(附带pdf)
专知会员服务
35+阅读 · 2019年11月30日
Arxiv
6+阅读 · 2018年7月16日
Arxiv
10+阅读 · 2018年1月29日
Arxiv
6+阅读 · 2017年12月27日




相关VIP内容
专知会员服务
54+阅读 · 2020年3月5日
专知会员服务
28+阅读 · 2020年2月18日
专知会员服务
57+阅读 · 2019年12月4日
专知会员服务
16+阅读 · 2019年11月30日
【变分推断课件】Lectures on Variational Inference: Approximate Bayesian Inference in Machine Learning(附带pdf)
专知会员服务
35+阅读 · 2019年11月30日
相关资讯
相关论文
Arxiv
6+阅读 · 2018年7月16日
Arxiv
10+阅读 · 2018年1月29日
Arxiv
6+阅读 · 2017年12月27日