点击蓝字 关注我们
论文:https://arxiv.org/pdf/2502.14354 作者:Moxin Li, Yuantao Zhang, Wenjie Wang, Wentao Shi, Zhuo Liu, Fuli Feng, Tat-Seng Chua 代码:https://github.com/zyttt-coder/SIPO
一、摘要
将大型语言模型(LLMs)对齐至人类偏好的研究,已从单一目标拓展为多目标,旨在更全面地反映人类偏好的多样性与复杂性。多目标对齐(Multi-Objective Alignment, MOA)同时考虑多个偏好维度,如无害性(harmlessness)、有用性(helpfulness)、事实性(factuality)和多样性(diversity),以提升模型的整体表现。其中,直接偏好优化(Direct Preference Optimization, DPO)作为一种有效方法,已被广泛应用于多目标对齐任务中。 然而,我们发现现有基于DPO的多目标对齐方法普遍面临**”偏好冲突”问题,即不同偏好目标往往对应不同的最优回答**,导致模型在多目标优化过程中出现优化方向冲突,从而妨碍在帕累托前沿(Pareto Front)上的有效优化。 为了解决这一问题,我们提出通过构造帕累托最优回答来消解偏好冲突。为高效生成并利用这类回答,我们进一步提出一种自我改进的DPO框架(SIPO),使LLM能够在无需外部标注的情况下,自主生成并筛选帕累托最优的回答,从而实现自监督的多目标偏好对齐。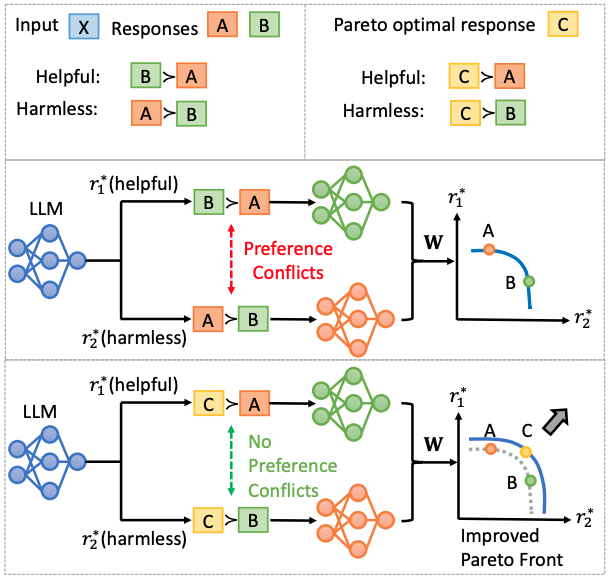
二、背景
对齐的目标用N个奖励函数来表示: 多目标对齐旨在基于用户提供的偏好权重: 最大化加权的奖励函数: 在不同用户偏好权重下,对齐后的多个模型在评测指标上(近似)构成帕累托前沿。 对齐使用多目标偏好数据集,由问题x,回答对y_1,y_-1,和N个目标上的偏好p_i组成,即 p_i代表每个目标上被偏好的回答。对于每个回答对,如果N个目标的偏好不完全相同,则这个回答对在不同目标上是偏好冲突的。
三、冲突数据对于帕勒托前沿的影响
为验证偏好冲突对帕累托前沿优化的影响,我们在多个数据集、对齐目标和对齐方法上,系统性地调整训练集中偏好冲突样本的比例,并观察所得帕累托前沿的变化。具体而言,我们将冲突样本的比例调整为 0%、30%、60% 和 90%。实验结果显示,随着冲突比例的增加,最终模型的帕累托前沿逐渐向未对齐模型的性能靠近,在 90% 冲突比例下几乎与对齐前完全重合,表明高比例的偏好冲突会严重削弱对齐效果。同时,我们还观察到,多项指标的平均表现也随着冲突比例上升而持续下降,进一步证明了偏好冲突对多目标优化的负面影响。
三、方法
3.1 帕勒托最优回答
为解决偏好冲突问题,我们引入帕累托最优回答作为应对方案。帕勒托最优回答y_c被定义为在所有目标上比y_1,y_-1更好的回答,即 y_c与y_1,y_-1都不存在偏好冲突,而且在所有偏好目标上也表现出更高的质量,有利于推动得到更好的帕勒托前沿。
3.2 SIPO框架
鉴于对帕累托最优回答进行人工标注在大规模数据集上成本极高且难以实现,我们提出的SIPO框架能够自主生成并利用帕累托最优回答,包含以下三阶段。 * 采样阶段:通过使用DPO将多个模型对齐至不同目标,生成多样且高质量的回答。根据不同的偏好权重对回答进行采样,以捕捉多种权衡方案。 * 改进阶段:通过自我评价改写策略提升采样回答的质量。评估者模型从多个目标角度审查回答,指导原模型对回答进行修订和优化。 * 过滤阶段:通过对齐的DPO模型及额外组合的模型估算隐式奖励,筛选出帕累托最优回答。保留在所有目标上表现优于原始回答的候选,并根据平均奖励选出最佳回答。 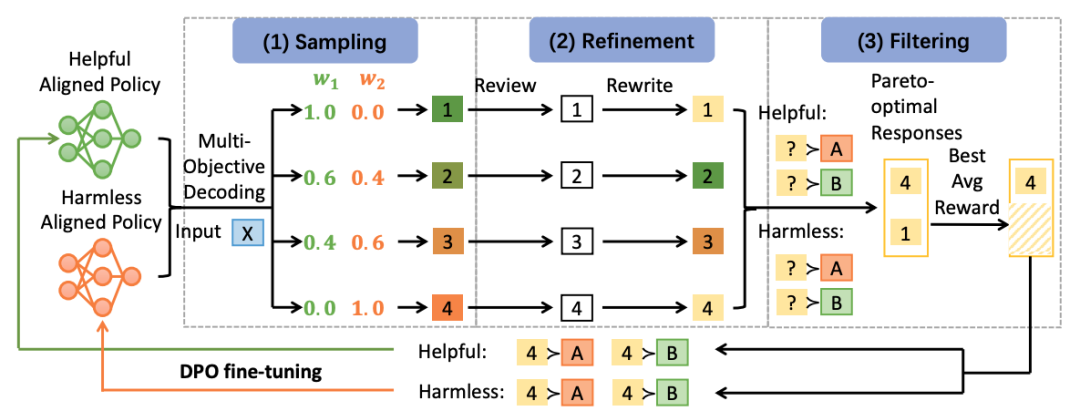
四、实验结论
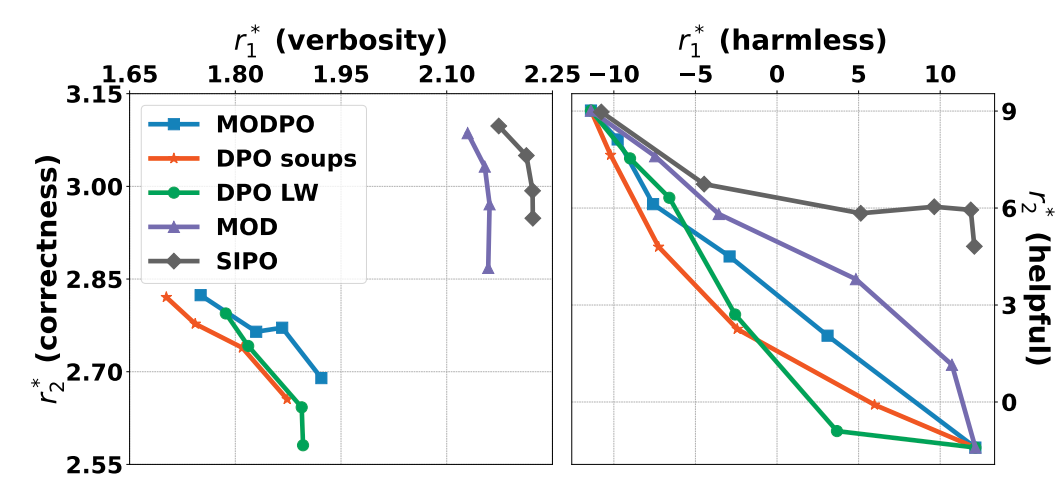
我们在两种模型(Alpaca-7B, Llama-2-7B-sft, Qwen2.5-3B-Instrutct)和两组目标(安全性和有用性,正确性和冗长程度)上分别测试了我们的方法,并与现有基于DPO的多目标对齐方法进行了比较。实验结果显示: * SOTA表现:相比于现有方法(如DPO Soups,MODPO等),SIPO在两种模型和两组指标上都能产生更好的帕勒托前沿 (Figure 3),并能与现有方法灵活结合。 * 自我提升框架的有效性:利用官方的奖励模型进行验证,SIPO框架采样的回答相对于原始回答在各目标上有所提升。当对非冲突数据使用SIPO框架,回答效果不能明显提升。 * 多轮,多指标,多模型的泛化性:多轮SIPO显著提升了帕累托前沿表现。即使在包含三个指标的更复杂场景下,方法依然有效。同时,该方法在不同模型家族和不同规模的基础模型上均表现出良好的适用性。