
报告主题:预训练语言模型的研究与应用
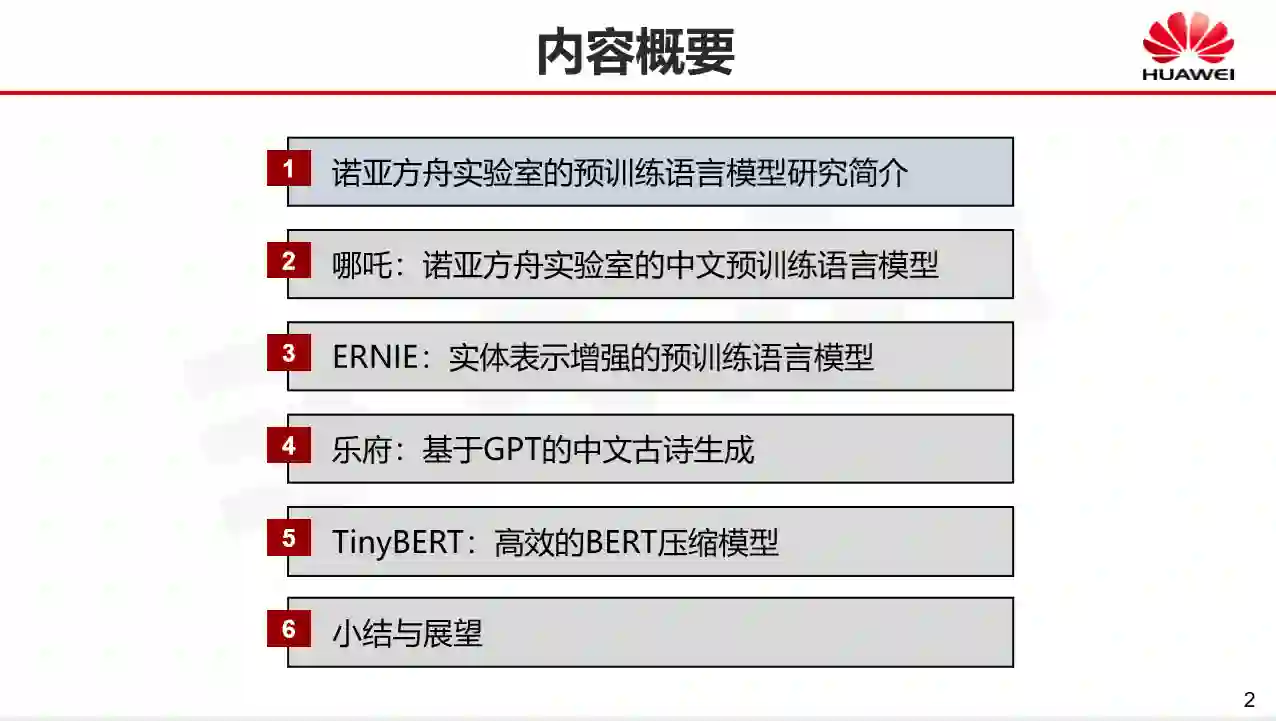
报告摘要:预训练语言模型对自然语言处理领域产生了非常大的影响,华为诺亚方舟实验首席科学家刘群分享了华为诺亚方舟实验室在预训练语言模型研究与应用。他从以下四个方面介绍了他们的工作:一是中文预训练语言模型——哪吒;二是实体增强预训练语言模型——ERINE;三是预训练语言模型——乐府;四是TinyBERT:高效的BERT压缩模型。最后,刘群对预训练语言模型研究与应用做了展望。下一步他们希望研究更好、更强大的预训练语言模型,融入更多的知识,同时跟语音和图像也能够有所结合;此外,也希望将这些预训练模型能应用到更多领域。
邀请嘉宾:刘群,男,华为诺亚方舟实验室,任语音语义首席科学家,主导语音和自然语言处理领域的前沿研究和技术创新。 1989 年毕业于中国科学技术大学计算机系,1992 年于中国科学院计算技术研究所获得硕士学位。刘群博士是自然语言处理和机器翻译领域的国际著名专家,他的研究方向包括多语言信息处理、机器翻译模型、方法与评价等。
成为VIP会员查看完整内容


相关内容

UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
5+阅读 · 2019年8月27日




相关VIP内容
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
5+阅读 · 2019年8月27日