
本文提供了针对视觉识别的单类别分类OCC的经典统计和基于深度学习的最新方法的全面调研。详细并讨论了现有OCC方法的优缺点,还介绍了OCC的常用数据集和评估指标。
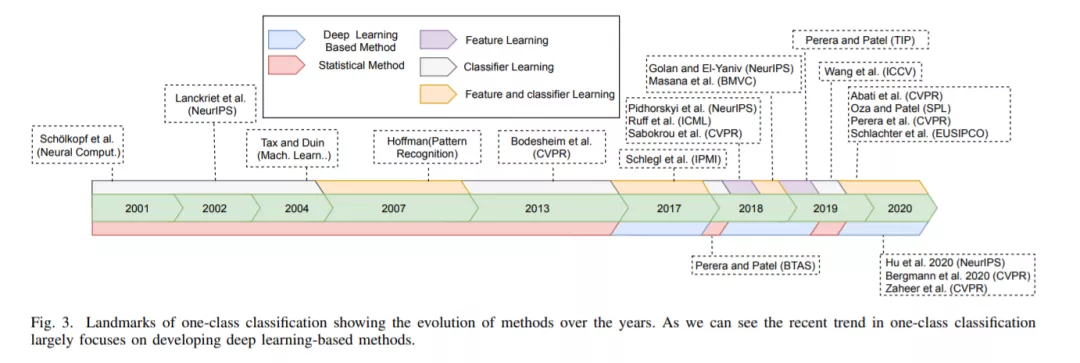
单类别分类(One-Class Classification,OCC)是多类别分类的一种特殊情况,其中训练期间观察到的数据来自单个阳性类。OCC的目标是学习一种表示法和/或一个分类器,该分类器和/或分类器可以在推理过程中识别正标记的查询。近年来,这个主题在计算机视觉,机器学习和生物特征学领域引起了相当大的兴趣。在本文中,我们提供了针对视觉识别的经典统计和基于深度学习的最新OCC方法的调查。我们讨论了现有OCC方法的优缺点,并确定了该领域研究的有希望的途径。此外,我们还讨论了OCC的常用数据集和评估指标。
https://www.zhuanzhi.ai/paper/65b2f00c35574ec550abefa501485937
成为VIP会员查看完整内容
相关内容
相关VIP内容
相关资讯
相关论文