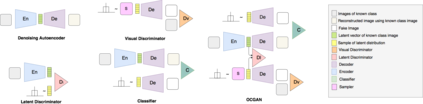
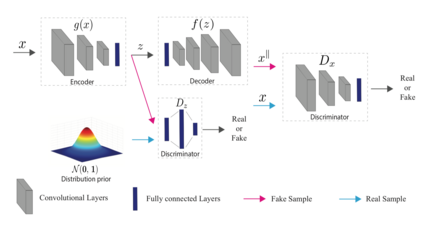
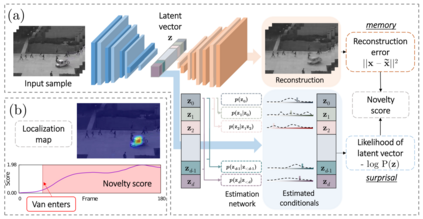
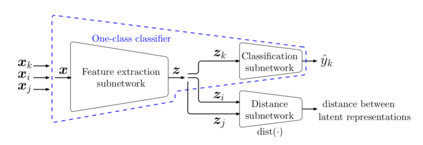
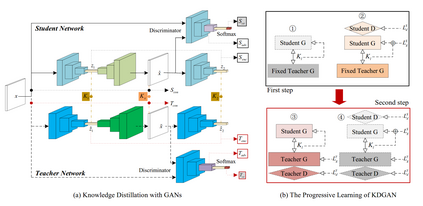
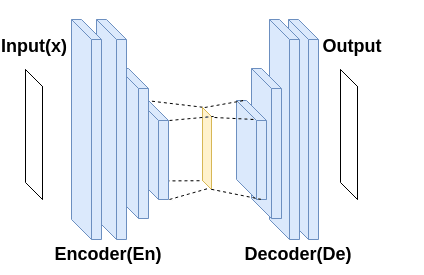
One-Class Classification (OCC) is a special case of multi-class classification, where data observed during training is from a single positive class. The goal of OCC is to learn a representation and/or a classifier that enables recognition of positively labeled queries during inference. This topic has received considerable amount of interest in the computer vision, machine learning and biometrics communities in recent years. In this article, we provide a survey of classical statistical and recent deep learning-based OCC methods for visual recognition. We discuss the merits and drawbacks of existing OCC approaches and identify promising avenues for research in this field. In addition, we present a discussion of commonly used datasets and evaluation metrics for OCC.
翻译:单类分类(OCC)是多级分类的一个特例,培训期间观察到的数据来自一个单一的正类,OCC的目的是学习一种代表性和/或分类方法,以便能够在推论期间确认贴有正面标签的查询;近年来,这一专题在计算机视觉、机器学习和生物鉴别学社区中引起了相当大的兴趣;在本篇文章中,我们对古典统计和最近的深层次学习的OCC视觉识别方法进行了调查;我们讨论了现有的OCC方法的优缺点,并确定了在这一领域开展研究的有希望的途径;此外,我们介绍了对OCC常用数据集和评价指标的讨论。