【论文】Awesome Relation Classification Paper(关系分类)(PART I)
作者:高开远
学校:上海交通大学
研究方向:自然语言处理
0. 写在前面
"正确的判断来自经验,而经验来自于错误的判断"
之前做过的百度今年的语言与智能技术竞赛,其中有一个子赛道就是关于信息抽取。信息抽取(Information Extraction)是指从非结构化的自然语言文本中抽取出实体、属性、关系等三元组信息,是构建知识图谱的基础技术之一。IE的子任务大概有以下几种:
实体识别与抽取
实体消歧
关系抽取
事件抽取
之前有介绍过关于实体识别的一些内容,今天这系列文章就主要来看看关系抽取是怎么做的。
1. 什么是关系抽取(Relation Extraction)?
同样,在进入具体RE论文之前,先对这个任务有个大概的了解吧。关系抽取的目的是从文本中抽取两个或多个实体之间的语义关系,举个栗子:

关系抽取的解决方案主要有以下几类:
基于模板的方法(rule-based)
监督学习
ML
DL
半监督/无监督学习
Bootstrapping
Distant supervision
Unsupervised learning from the web
篇幅限制,这里就不具体展开,关系抽取的更具体介绍可以参考斯坦福的Introduction to NLP,不是cs224n!
2. Relation Classification via Convolutional Deep Neural Network(Zeng/Coling2014)
挺久远的一篇文章,可以算是CNN用于文本处理比较早的一批了。在这之前,大多数模型使用的都是feature-based或者kernel-based方法,不仅处理过程复杂而且算法最终的效果很大程度上依赖于特征设计的有效性。基于此,作者提出了一种基于CNN的深度学习框架,可以自动提取输入中多层次的特征(词层面和句子层面)如下所示:

模型可以分成以下几个部分,接下来一一介绍:
Word Representation Layer
Feature Extraction Layer
Output Layer
Word Representation Layer
标准操作word embedding,不过用的不是现在主流的word2vec、glove等等,而是预训练的来自Word representations: A simple and general method for semi-supervised learning的词向量。
Feature Extraction Layer
特征抽取模块设计了两种features:词法特征(Lexical-Feature)和句法特征(sentence-level feature)
Lexical-Feature
在确定实体关系任务中,词法特征是非常重要的。传统的词法特征提取主要包括实体本身、名词性实体对以及实体之间的距离等等,这些特征很大程度上依赖于现有的NLP工具,对RE任务最重效果容易引起误差放大。但是在有了word embedding之后就可以对词法特征设计更恰当的特征,一共有五部分:

举个栗子,对于句子

L1: People
L2: downtown
L3: x_s,have
L4: into,x_e
L5: 在wordnet中找到people和downtown的上位词。
注意:以上都是word embedding形式
Sentence Level Features
句法特征提取方案如下:

在第一步
Window Processing设计了两个特征输入,一个是单词特征(Word Features), 一个是位置特征(Position Features)
Word Features就是word embedding,不过加入了n-gram的信息;
Position Features就是位置信息,每个context单词与实体对词语之间的相对距离。这样设计的目的是为了突出两个entity的作用
在这里插入图片描述

最后对每一个单词将Word Features和Position Features拼接起来,得到features维度为: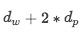
得到句子的抽象表达之后,送入卷积层进行特征提取。不过这里的卷积核设计有点奇怪只有一层将Window Processing层的输出进行线性映射:
接着为了每一维度提取最重要的特征,设计了max-pooling层:
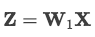
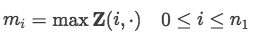
最后通过非线性激活层得到句子特征表示:
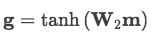
Output Layer
output层的输入是将上一层词法和句法层面提取出来的特征进行拼接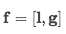
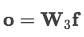
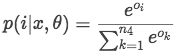
模型表现
数据集使用的是SemEval 2010 Task 8,共有19种关系类别(双向的9类 + 一类Other)。

小结
以上就是基于CNN进行关系抽取的整体思路。总结一下:
整个模型需要学习的参数:word embedding(X) - position embedding (P)- 卷积核权重矩阵(W_1) - sentence-level 最后的全连接层参数矩阵 (W_2)- 用于softmax的全连接层参数矩阵(W_3)
引入位置信息,CNN相对RNN较弱的是对长距离位置的建模,这里加上PE后可以很有效缓解这个问题,之后的很多研究(CNN,attention等)都有PE的身影;
卷积层那块感觉有点单一,因为只有一个线性的映射特征提取不够充分
虽然整个框架在现在来看是非常简单的设计,但是经典呀
Talk is cheap, show me the code
CODE HERE
3. Relation Extraction: Perspective from Convolutional Neural Networks(Nguyen/ACL2015)
15年的文章,在之前Zeng的模型基础上加入了多尺寸卷积核,并且更"偷懒地"丢弃了人工的词法特征,完全依靠word embedding和CNN来做特征。完整的框架和文本分类领域非常经典的Text-CNN很像,之前在文本分类模块我们也有详细介绍过(【论文复现】使用CNN进行文本分类)

试验分析
relation classification

relation extraction

小结
在Zeng的基础上使用了多尺寸卷积核,更全面提取特征
丢弃人工词法特征,端到端训练更方面
进一步研究关系抽取问题,考虑了该问题中数据集分布不平衡
CNN框架比较简单,因此效果提升不是很明显
Talk is cheap, show me the code
CODE HERE
4. Classifying Relations by Ranking with Convolutional Neural Networks(Santos/ACL2015)
直接看模型,也是非常传统的文本CNN框架,但是作为顶会文章肯定是有一些亮点的。

创新点
模型的框架这里就不多啰嗦了,直接看重点,想比与之前的CNN论文,本文的创新主要有以下几点:
1. 损失函数
不同于一般多分类使用的softmax+cross-entropy损失函数,这里独特地设计了一种margin-based ranking loss: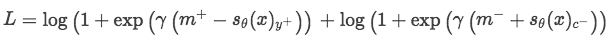
:输入句子sent, sent对应的正确标签,sent对应的错误标签
m^{+}:正标签对应的大于0的margin
m^{-}:错误标签对应的大于0的margin:正样本对应的得分
:负样本对应的得分
$\gamma$:缩放系数
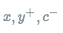
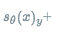
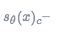
理解了参数的意思之后,就可以明白这个损失函数是在干什么了。首先右边第一项计算的是正样本的得分只有大于margin的时候才不会有损失,否则就需要计算损失,即得分越高越好;右边第二项计算的是负样本的得分只有小于 -margin才不计算损失,即负样本得分越小越好;是不是跟SVR的感觉有点像?这样整体的损失函数的目的就是更加清晰地区分正负样本。
实验结果显示,自定义损失函数相较于CE损失效果提高2%左右。

那么具体实现中,怎么去确定负样本采样呢?
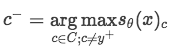
2. 对Other类别的处理
Other类别表示两个标定的entity没有任何关系或者是属于不存在与给定关系集合中的关系,对于模型来说都是噪音数据。经过之前是实践(参考github),发现确实模型在对Other类型的处理部分并不是很理想,拉低了最终的得分。因此作者提出在训练阶段,直接不考虑Other这一类别,即对于Other的训练数据,令上一节中损失函数第一项为0。那么在预测阶段,如果其他类别的score都为负数,那么就分类为Other。从实验结果看,这个点的提高有2%左右。

原文链接:
本文由作者原创授权AINLP首发于公众号平台,点击'阅读原文'直达原文链接,欢迎投稿,AI、NLP均可。





