TensorFlow技术概览-从建模到部署

分享嘉宾:金海峰 谷歌 软件工程师
编辑整理:查清智
出品平台:DataFunTalk
导读:很多人对TensorFlow的理解就是一个类似于PyTorch,MXnet的用来建立神经网络模型的深度学习建模工具,但实际上,TensorFlow是一个非常完整且灵活的深度学习工具链,它可以覆盖到构建模型,模型部署和运营管理。在构建模型方面,它可以覆盖到模型的调参,模型选择以及数据的预处理;在模型部署方面,它可以支持很多的场景,比如说在服务器端,通过REST API来部署,或者是在网页上,在用户的Browser里运行一些神经网络的模型,或者是在一些Android device,比如说你的手机,或者是一些更小的单片机上来部署这些神经网络的模型;在运营管理方面,对于每个模型的部署,需要随着数据的更新而更新模型,这样重复的把新的模型用新的数据训练,并且部署到一个新的环境的过程就需要运营管理,因此TensorFlow为模型构建,模型部署以及运营管理的整个过程提供了一套完整的工具链。今天会和大家分享并总结在TensorFlow生态系统里的每一个环节中,哪些工具是最好用的,能帮你高效完成需要的功能,介绍会围绕下面三点展开:
构建模型
模型部署
运营管理
1. Keras深度学习建模生产力工具
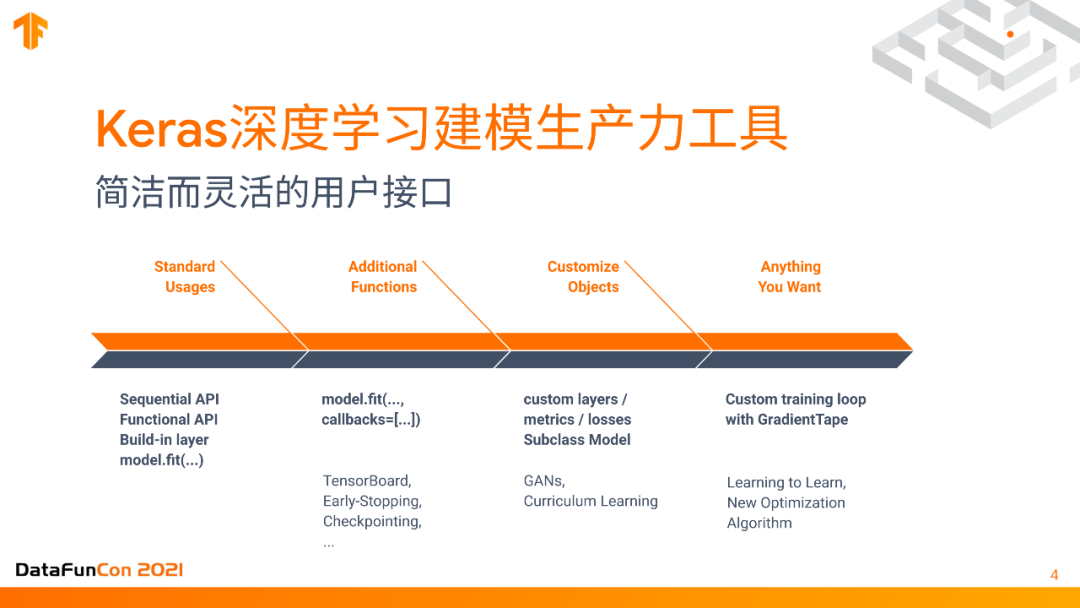
TensorFlow中有哪些建模工具?大家最熟悉的可能是keras,我把它称为深度学习建模生产力工具,它有非常简洁而灵活的用户接口,keras的API非常简洁,基本上包含在最左边的Standard usages,你可以非常简单的define一个神经网络,只需要说里面有什么层,比如convolutional layers或是fully connect layers就可以了。它除了这些最简洁的接口之外也可以定制化的来构建很多复杂的模型,比如可以利用callback function对模型进行定期的存储,对训练进行提前的终止。而且如果你想训练generator model生成 GANs, 或curriculum learning等,可以define自己单独的层,还有自己的model,而且里面所有的代码都是可以定制化的,不一定只有事先规定好的那些layer model。更进一步来讲,如果你想设置一些更复杂的,你甚至可以自己定制整个training的循环,以及记录所有的gradient,然后设置自己的gradient function来控制整个Backpropagation的过程。这种过程就可以支持learning tolearn, New Optimization之类的例子。
(1) Keras中简洁又灵活的接口
这里来看一个非常简单的keras例子,给大家一个直观的感受:

我们在define一个model的时候,实际上只需要把这些层和它们对应的参数放进去就行了。在这里放了四个层,可以直接设置好需要的损失函数和优化器,把数据放进去就可以开始训练了,就是这样一个非常简洁的接口。
(2) 100+经典模型示例代码(keras.io)

我们在keras的官网kera.io上面发布了100+模型示例代码,几乎覆盖了大部分的你能想到的,深度学习的问题,包含了conservation,NLP structure,timeseries,audio等等,这些主要是来自于社区的贡献,我们的团队会仔细审核每一个社区贡献的代码例子,以确保他们follow了keras的最佳实践,所以这些代码质量都是有保证的。大家如果想要建立自己应用,不妨就到keras.io上来找这些代码的例子,然后通过简单的修改就能实现你想要的功能。
(3) 高效率的调参工具--KerasTuner

建模不是一个能一次性把代码写对,并且选对正确模型的过程,我们需要反复的调整个别参数,确保所有参数都达到最优,这样训练出来的模型和效果才是最好的。所以我们设置了一个专门调参的工具,你不用自己手动运行程序,可以自动化的一下跑很多个实验,每个实验设置的参数和超参数都是不一样的,我们会自动帮你选出一个在你规定的衡量指标里最好的模型。这个工具叫kerasTuner,是专门针对keras定制的一个调参工具,它支持了很多主流的挑战算法,比如Hyperband和贝叶斯优化,它对于用户几乎是没有学习成本的,只要你知道怎样进行调参。下图是一个简单的例子:
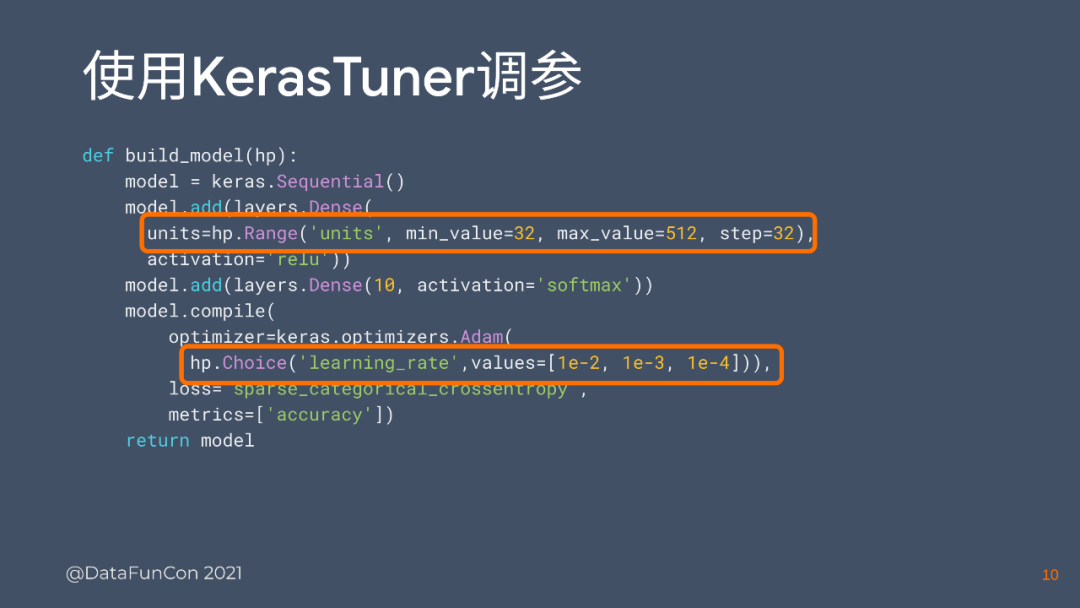
这里有个函数叫build_model,它的目的就是建立一个keras model,然后把Dense层放进去,最后返回这个model。如果有两个想要调的参数,比如说number units和dance layer里面总共有多少个单元,还有adam优化器,它的learning rate是多少?学习率是多少?那么只需要把这两个参数换成对应的参数范围就可以了。只需要define它的最小值和最大值,在这个间隔内,以多大的力度去搜索这个空间里面的取值,以及如果只想在三个值中选一个最优的值,只需要去define一个list放进去就可以了。只需要最简单的代码修改就可以保证解决整个调参问题。可以直接导出一个最优的模型。KerasTuner可以定制化的调整所有的参数,不一定要这样的形式包装成一个Kerasmodel才可以调。但KerasTuner有一个特点,它仍需要用户完全理解整个模型的每一个层和模块里面所有的超参数。
(4) 全自动建模工具--AutoKeras

为了让用户能更多的提高建模的效率。针对几个常见的应用场景,我们提前设置好了很多模型,用户不需要自己去定义它的超参数,只是把任务和数据输入到AutoKeras的接口里面,然后在另一端等着收割结果和训练好的模型就可以了。利用这个工具,可以把很多任务的代码缩减成三行,下面通过一个简单的代码例子来感受一下它的用法:

这里我们load一下mnist的图片和数据集。只需要ak.Imageclassfier(),就已经把神经网络建模的搜索空间设置好了,然后把数据放进去,它就会根据数据切分成训练集和验证集,反复training多遍,最后选出一个best model return给你。在这个过程中你甚至不需要知道用的什么模型,当然你也可以通过看通话了解整个过程。最终的模型是一个keras model,只需要export model,把它塞到硬盘上就可以了,它的格式就是一个标准的keras的模型。
2. 预制模型和预训练模型合集
(1) TF Model Garden: 各种模型的大集合

很多用户更喜欢纯定制化的模型,不用自己去训练,TensorFlow在这个生态系统里提供了一个非常好用的大的模型的集合,叫Tensorflow model garden,里面包含了各种各样的代码。和刚才提到的Keras.io网站上的代码有点像。它们的区别在于你可以直接通过安装Tensorflow model garden这个包(在Github上叫Tensorflow models),import进来这个model直接用就可以了,不需要自己手动复制粘贴那些示例代码再修改。
(2) TF Hub: 各种预训练权重的大集合

这些只是predefined的模型,有些用户可能更喜欢一些预训练权重,比如BERT model,这个模型对于NLP用了大量的语料库来训练,而这样的训练非常消耗财力和计算资源。因此很多人更喜欢用这些预训练好的权重,而且BERT model还有多语言模型和单语言模型,有很多不同的权重,这些权重不需要自己训练,只要到TF Hub上面去找就可以了,它作为一个各种预训练权重的大合集,可以非常容易地把这个预训练权重下载,并安装到你的模型里,下面用一个使用TF hub和keras建模的例子来说明:
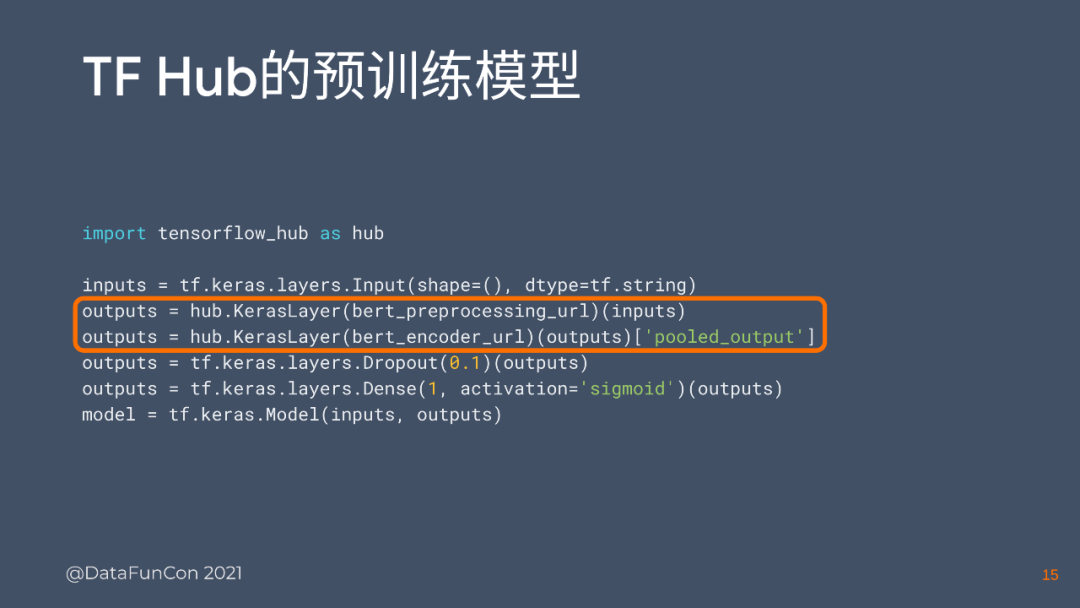
整个代码使用和keras建模的过程没有什么区别,实际上它就是一个keras model,只不过中间塞进去两个从TF hub上搞来的带着预训练的weights一起来的hub.KerasLayer,整个模型已经训练好了,同时也可以设置是否要把这个层的weights固定住,然后来训练其他层。
3. 构建数据预处理的流程
(1) 使用tf.data读取和归纳数据
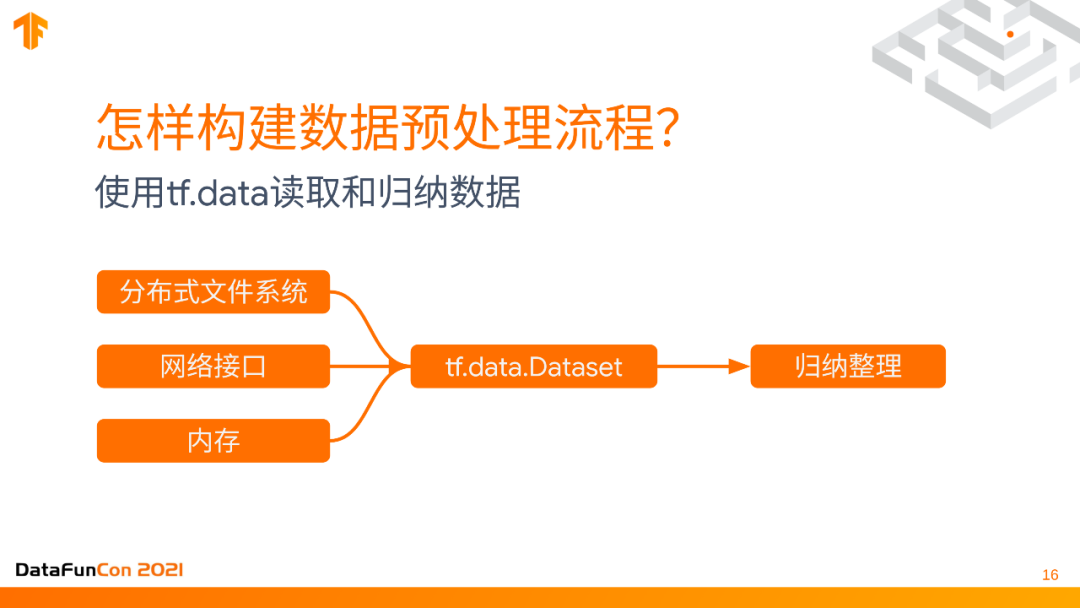
预处理是一个非常复杂非常重要的过程。首先第一步就是要读取数据,你的数据可能存在不同的地方,如果你的数据非常大的话,可能存在分布式文件系统里,或者你的数据是实时生成的,那么就是实时采集的。数据可能来自于一些网络接口,比如说REST API从一个get操作中才能从API里取到数据,或者它就是一个比较小的数据集,就像一些快速的实验,它就以一个Numpy array或者一个list的形式存在内存里。所有这些存储形式都可以把它包装成一个tf.data.dataset,它可以把所有数据统一的读取出来,有各种读取方式,可以是实时的,也可以是预读取的,可以调整到performance最快的速度。它还可以对数据进行一些归纳整理,这里的归纳整理是一个比较笼统的说法,实际上它可以进行几乎所有的数据的预处理。比如要做一个time series forecast时序数据的预测,那么可能要有做一个sliding window,把一段时间内的数据打包成一个training instance,然后输入到模型里面,把多条数据归纳成一条。
(2) 使用Preprocessing Layers把预处理包进模型

我们更倡导用户把其他不会改变instance数量的预处理交给keras本身,直接把它包进模型里。因为如果用tf.data,不是很好把这部分代码转移出去,但是把任何代码包进keras模型里,keras模型是可以存储到硬盘,并且可以被任何一个下游的,比如说部署端的,或者是manage模型周期的软件直接读取的。所以如果能把这些预处理直接包进模型里的话,就是一个非常方便的做法。这里我们使用一些paper size layers,每个layer都可以进行神经网络的backpropagation计算weights,里面也有很多layer用来进行预处理的,比如说进行数据增强,进行NLP任务的分词,都可以通过paper size layers完全包进模型。

但这时候可能遇到一个问题,因为我们想让模型达到一个最快的速度,如果强行把这些预处理的操作都推到GPU上,GPU的处理速度不一定有CPU快,因为CPU有很多个核可以并行操作,它对很多预处理的操作要比GPU更快。那么这时候就可以直接把它包成两个模型,一个Keras模型专门只有这些预处理的操作,另一个Keras模型只有神经网络的层,然后把两个模型分别存起来,这样它的可转移性和probability都是非常好的。这能保证在CPU上把所有预处理的过程完成的又快又好,然后在GPU上把所有神经网络基本过程完成。
(3) 回顾构建数据预处理流程
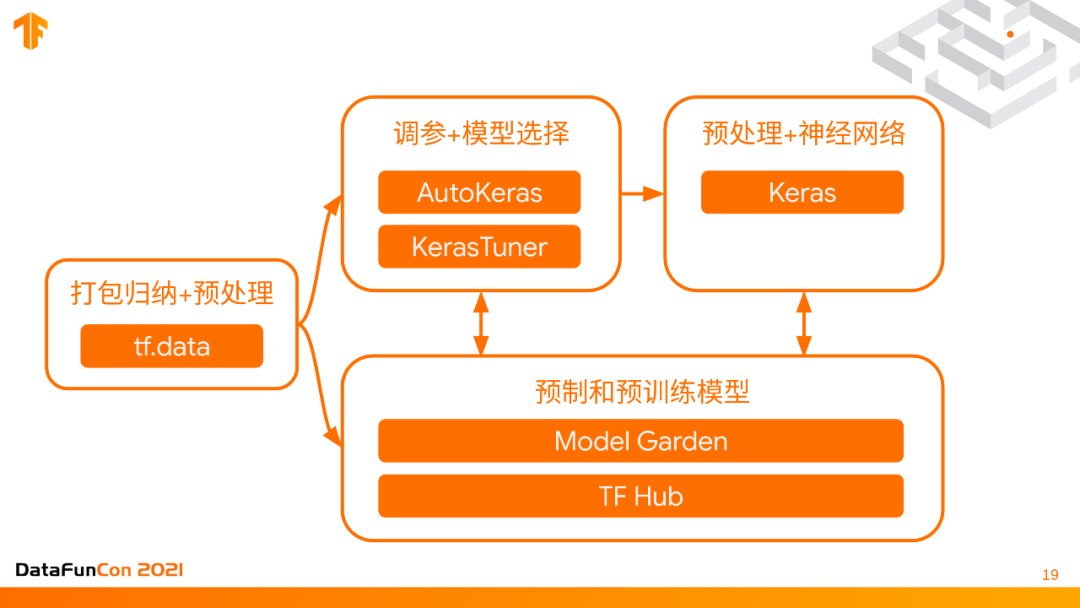
接下来进行一个简单的回顾。首先从数据来源来讲,我们用tf.data把所有的数据进行读取打包统一格式,然后它们可以输入到模型里面。同时如果你想用预训练模型,预定制的和预训练的模型可以从TF model garden直接import进来模型直接用,也可以从TF hub下载那些pretrained weight,这些pretrained weight打包成了keras layers,可以直接和keras一起使用,所以这是一个双向镜头。也可以使用AutoKeras或者KerasTuner进行调参和模型选择,最终导出一个模型。
1. 优化模型性能

首先在部署之前,需要模型优化,让模型到生产环境里能以最快的速度inference,一个数据进来通过模型,拿到结果再出去,中间过程是最短的。在这里推荐大家用TensorFlow Profiler,它可以可视化整个模型运行时间,把整个Tensorflow模型的运行时间非常清晰地展现在你的眼前,每一步用了什么,比如在上图中就非常明显看到reduce操作时间有点长了,那么我们就可以针对性的来优化操作,看是不是某一个数据读取,或者是模型的某一个分支inference time慢了,然后做更有针对性的优化。
2. 自动化模型压缩

不是所有的优化都是手工的,有很多优化是可以自动进行的,比如说把模型变小变快,里面所有的operation都是最简洁的,最适合部署到终端设备,你的终端设备可以是一台手机,是一些单片机,是一个embedding system,总之是一些低能耗,小内存,容量非常有限,电量非常有限,算力非常有限的设备。当我们想把模型压缩到比较小并部署出去的话,有一个Tensorflow model optimization toolkit自动化的进行模型压缩,下面还是用一个简单的代码例子来看一下它是怎么工作的:

比如设置了一个keras model,define的时候是没有经过压缩,如果你希望压缩它,只需要设置一些模型自动压缩的参数,比如sparsity总共有多少个step,要pruning多少,滤值都设置好了,再把数据扔进去进行一次训练就可以了。
3. 部署到终端设备
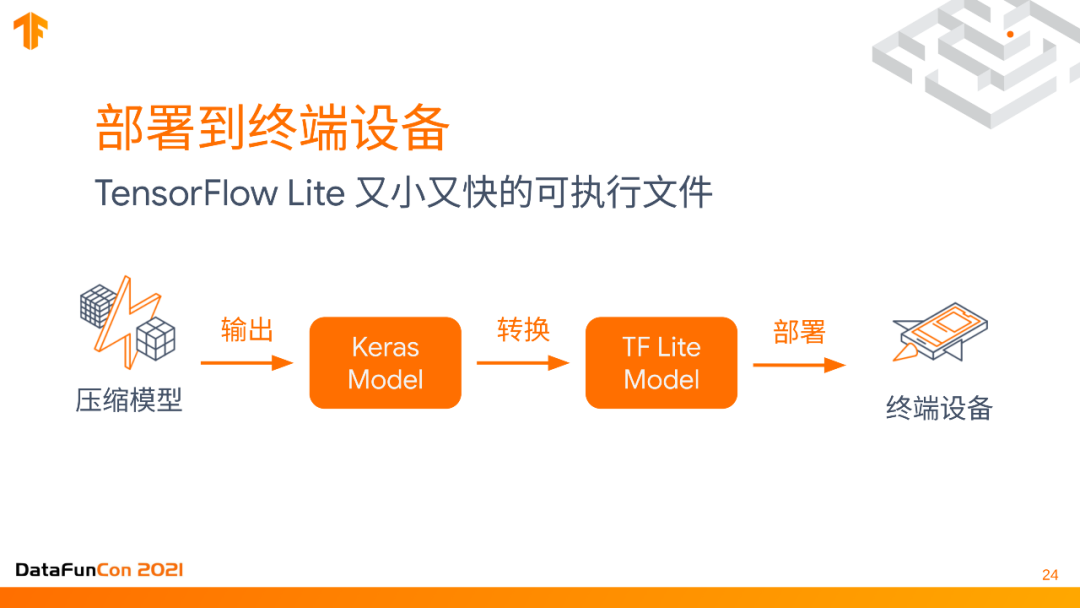
部署的终端设备大概流程如上图,先是压缩模型,输出一个keras model,然后我们把它转换成TensorFlow Lite。这个是tensorflow系统里的一个库,用来operation UPS,这些神经网络的UPS size都是非常小的,而且比较省电,比较快的编辑成一个二进制文件。虽然keras model压缩了之后size已经比较小了,但还有进一步优化的空间,因此我们可以把它转化成一个TF Lite model,再部署到终端设备上,这样它就可以生成一个又小又快的二进制可执行文件。

这个转化成TF Lite的model其实用几行代码就做到了。你只要把from_keras_model扔进去,用coverter转换一下,就可以直接把它存到一个二进制文件里,非常容易。
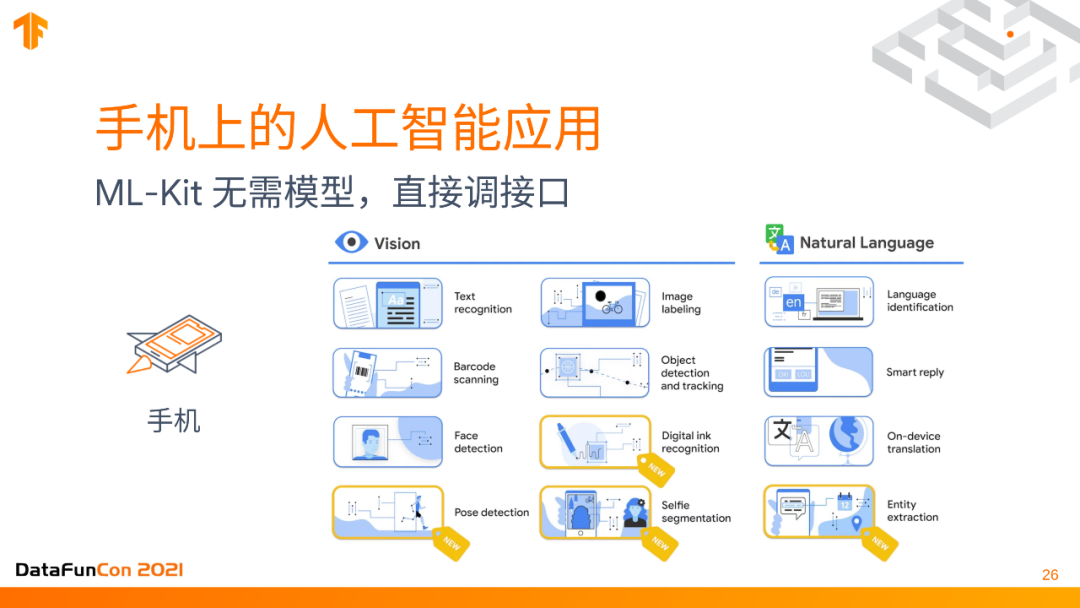
在终端上实现人工智能应用,其实不一定非要用TensorFlow。这里给一个不用TensorFlow的解决方案,就是ML-kit,这是google开发的一个完全免费的开源的包,它支持了很多主流的,在手机上可能用到的包,比如text recognition,object detection之类的,很多这些应用模型部分的代码不用写,直接从ios或者安卓的应用里调接口去部署就可以了。
4. 部署到网页
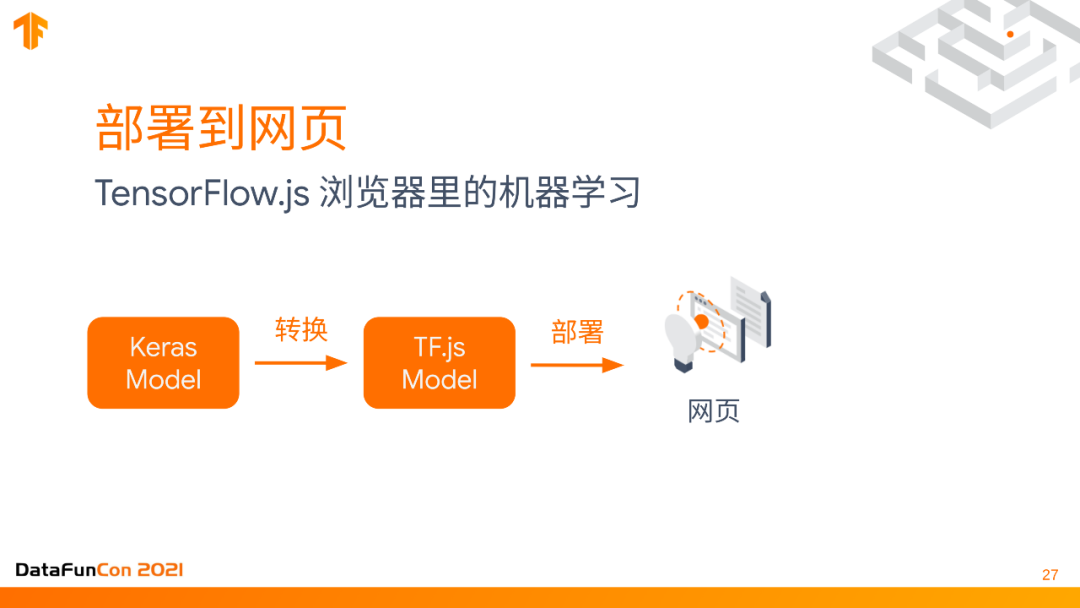
部署到网页上的时候,要用Tensorflow.js,因为我们不希望所有的东西都是远端计算把结果反馈给用户,而是希望有些东西在用户本地浏览的过程中进行计算的,也就是在用户的浏览器里发生这些计算,这样可以给用户更实时的反馈。在远端和近端有非常大的区别,用户不需要等到它把这个非常大的视频的信号传到远端,再等待那远端处理,然后再传回来。我们就希望整个model在浏览器里运行。用TensorFlow.js是一样的逻辑,把keras model转化TF.js model并部署到网页去。

例子的代码也是同样非常简单,用一个converter直接save keras model,把这个keras model放进去就整个转换好了。从一端用Python代码,但是从另一端可以直接用代码把模型读出来,直接用就可以了。
5. 部署到服务器

我们最主要的部署场景还是部署到服务器,这里推荐一种最主流的方法,就是TF serving,TF serving支持很多不同的场景,比如Docker, gPRC还有很多方式,但是一种比较简单直接的就是docker container,它怎么做呢?把keras model存到这台服务器上,然后用一个volume mount到docker container上,就直接可以用,就相当于部署完了,只要把docker container运行起来,把volume mount上去,就可以通过host的一个REST API形式来让model直接进行。
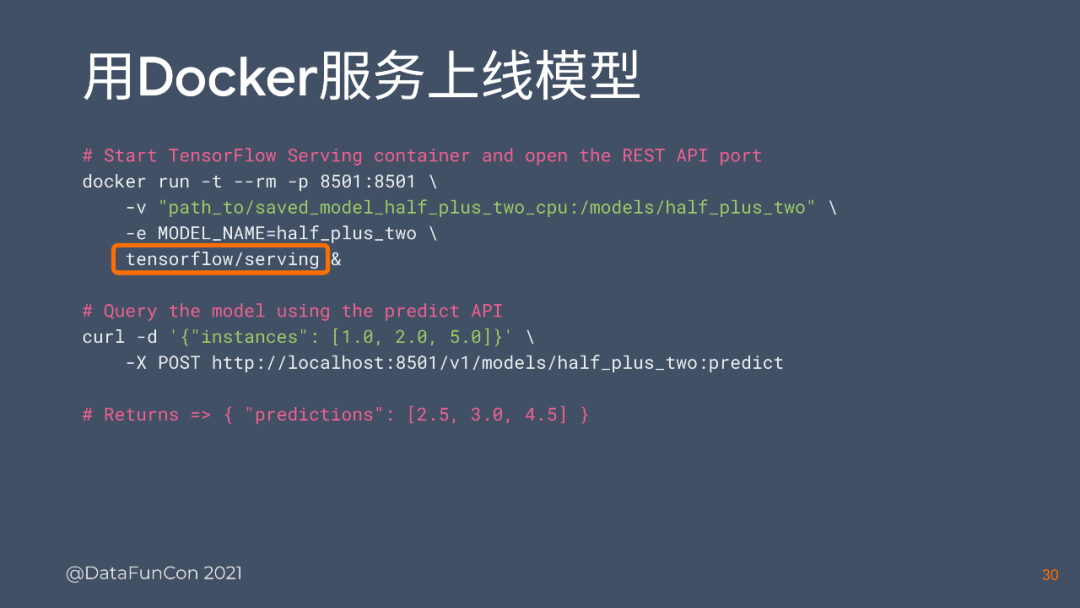
这里我们来看两个代码,首先,download下来TensorFlow / serving,把model mount上去,然后把docker run起来就可以了。其次,比如我们curl了一下要post的信息,也就是你要进行的inference的数据,这是你的feature要输入的,它会反馈给你一个predictions,然后整个REST API就完成了一个single的doctor container。
6. 模型部署的总结
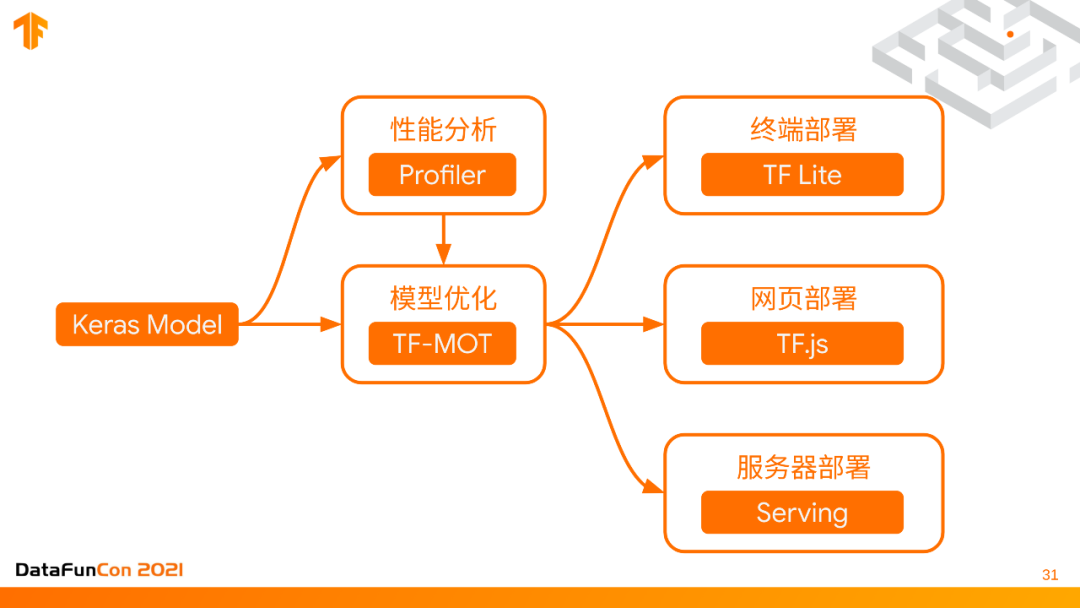
模型部署的部分就是从keras model开始,你可以用TensorFlow profiler进行系统分析,可视化的找到它的瓶颈。然后用自动化的模型优化方式model optimization toolkit,部署到不同的位置,比如说用TensorFlowLite,TensorFlow.js,TensorFlow serving来针对终端网页和服务器进行部署。
1. 从建模到部署需要运营管理

对于运营管理的部分,就像刚才说的,每个模型有它的生命周期,随着新的数据的输入,可能要用新的数据去更新模型,并且把新的模型重新部署一遍。所以部署模型的过程需要反复运行,从建模到部署需要运行管理,因为整个machine learning的代码就只有一小块儿,更主要的是要manage整个过程,其中包括setup,搜集数据,提取特征,数据验证以及一系列的过程,还要管理machine resource。
2. 搭建端到端的生产线
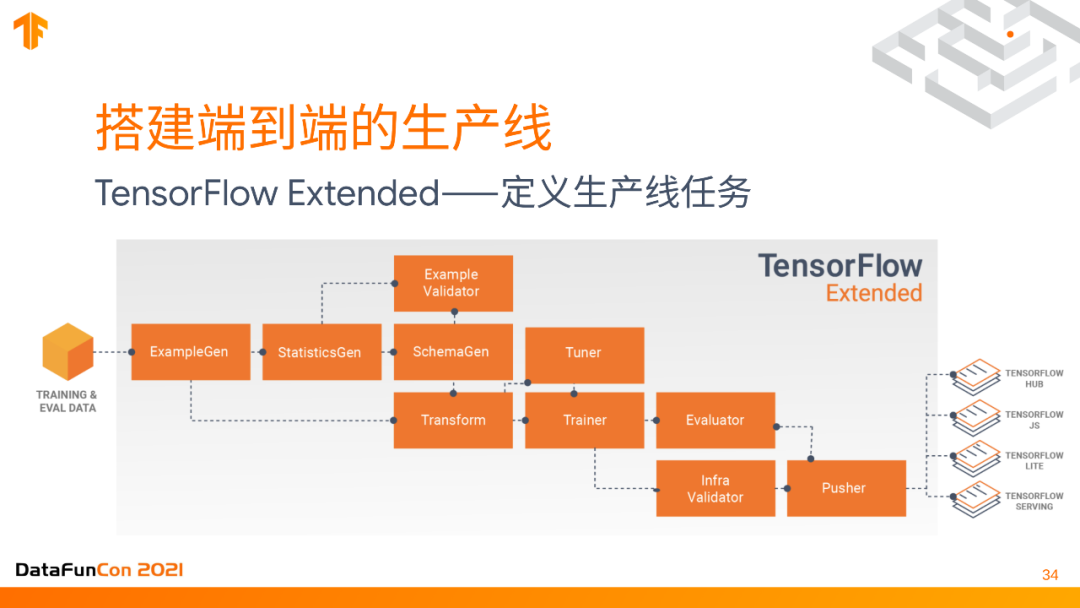
因此我们需要一个生产线,可以用TensorFlow Extended定义这样一个生产线,也叫TFX,比如可以设置如何生成training example,对它们进行一些统计,把这些数据的schema都做好,对数据进行一些预处理,然后输入给tuner对model进行training,最后把model push到它需要的部署环境里。这是一条生产流水线,需要反复运行,每次新的模型或数据,都要把流水线运行一遍。但是这是一个比较heavy的库,需要至少一到两个engineer来定期maintain这个service。
3. KubeFlow—K8s上的机器学习工具箱

如果要把这个流水线定义好,我们要把它跑起来,但用什么呢?TFX支持很多不同的运行工具,可以把它分布式地大规模地跑起来。这里我最推荐的还是Kubeflow,它是一套基于google cloud platform,kubernetes和docker的完整生态工具,它是在Kubernetes上的机器学习工具箱,可以把TensorFlow extended的每一个生产流水线上的每一个步骤都分布式地,在大规模机器上运行起来,非常容易,而且可以确保流水线的整个流程不会乱。
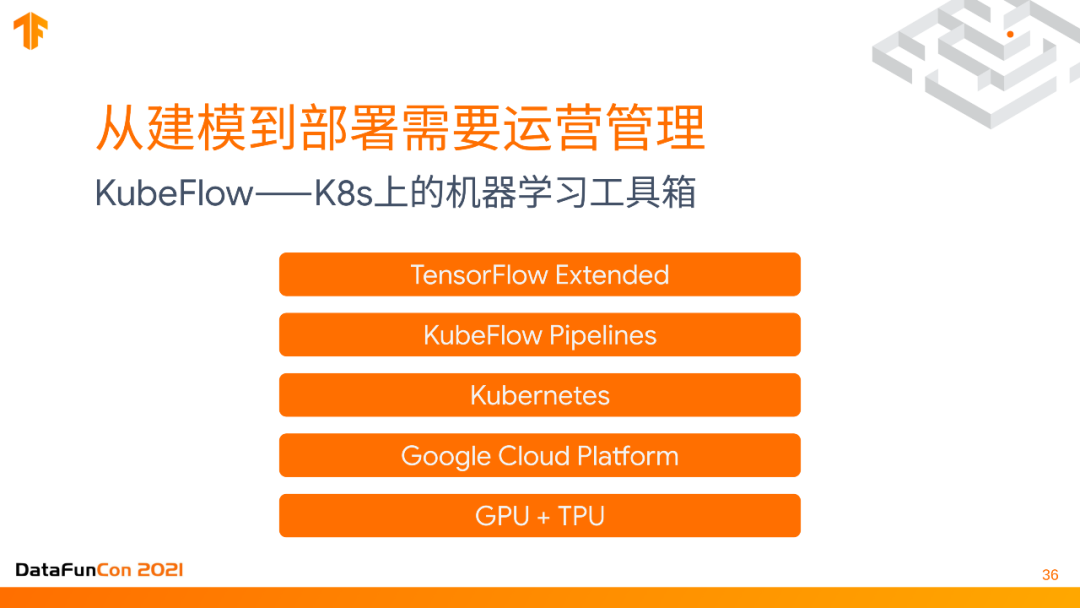
KubeFlow的stack最底层是GPU+TPU硬件,上面是cloud service,然后是kubernetes,里面跑的KubeFlow的pipeline就是其中的model,最上面是Tensorflow Extended定义的流水线,这就是一个从建模到部署的整个运营管理的stack。
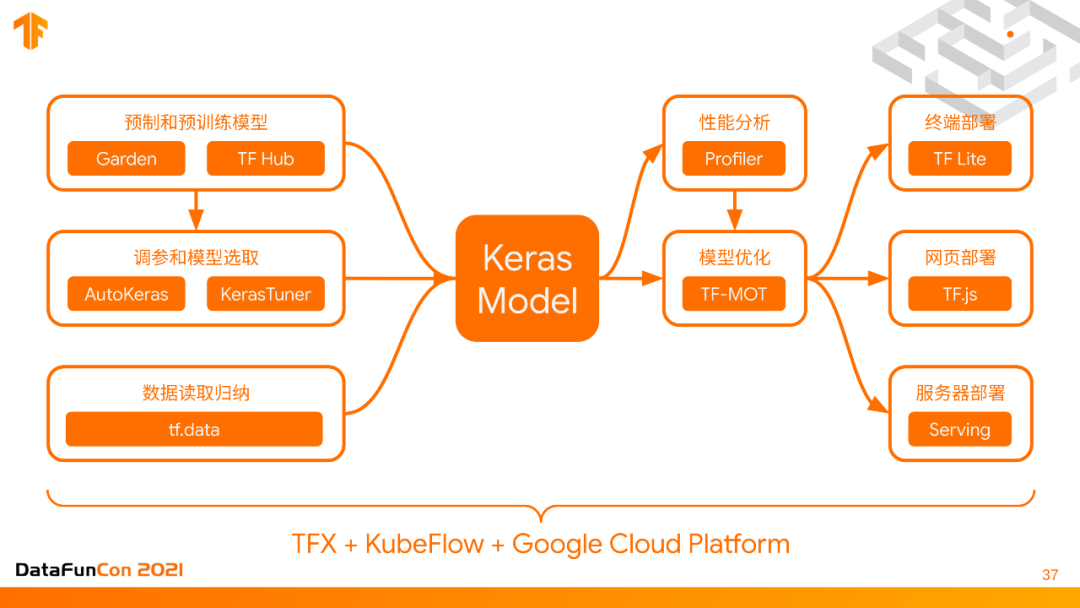
我们把从建模到部署的整个过程,每个步骤都概括性地再说一遍,首先最下面的是TFX + KubeFlow + Google Cloud Platform一起来host的一个service,来让所有这些在上面的东西运行起来。模型建模的部分是 Tensorflow garden和TF hub预制模型和预训练模型,对于模型调参和选取,有AutoKeras以及KerasTuner,然后数据预处理要读取tf.data并归纳,所有这些都可以export出来一个keras model,这个keras model会进一步的进行性能分析,性能优化,最终部署到不同的应用场景、终端网页和服务器,整个过程的核心就是keras model,在系统里,不同部分在同一个keras model模式下。
最后推荐两本书,第一本书是《Deep Learning with Python》,如果大家想要进入深度学习这个领域,推荐这本keras之父的最新力作的第二版,第一版在国内外都广受好评,它的特点就是没有任何数学公式,以工程师的语言讲解整个深度学习的各种原理,非常容易理解上手。

推荐的第二本书是《Automated Machine Learning in Action》,这本书讲解了自动化机器学习的一些最佳实践,怎么使用AutoKeras和KerasTuner来进行最高效率的模型选择和调参,这本书可以帮助提升整个团队算法工程师的工作效率。

Q1:AutoKeras的训练成本是不是很高,它本身有没有一些early stopping之类的机制,能够去优化我们的资源使用?
A:取决于你有多少资源,针对不同的情况,可以选择不同的策略。我们最少的计算资源minimum的要求一般是至少可以训练十个模型,如果低于十个模型,训练效果就没有保证。如果你做一个快速的实验,需要知道你的数据大概是什么样的模型,只要确定使用的模型然后再手动调就可以了。如果你有更多的资源,是一项大规模的训练的话,那就多大都可以了,因为AutoKeras规模越大效果就越好。AutoKeras内置了一个early stopping的机制,实际上它不只有early stopping,有很多机制可以让你快速的把整个资源优化配置起来,early stopping只是其中一个,而且它支持所有keras的callback回调函数,你也可以自己写一些来支持你的模型,比如你觉得什么时候要stop,可以自己写一个callback,自己控制资源项目。但它最主要的限制方法还是可以进一步的细化搜索空间,把一些你认为不合理的模型直接exclude掉,这样搜索空间小了就可以很好地提高效率。
Q2:Keras本身支不支持分布式的大模型的训练和推理优化,用比较底层的low-level API写是不是没有什么差别?
A:Keras本身是支持分布式的大模型的训练和推理优化的,主要是依赖于TensorFlow本身的distributed的这个大规模的训练,它支持很多不同的策略,都包含在TensorFlow.ditribute里,其中很多策略,比如最简单的mirror,以及对于大规模训练的perimeter sever都是支持的,而且不需要很多复杂的setting,整个训练过程代码几乎是一样的,只有initialize strategy那一行不一样,下面training的过程都是.fit形式,把数据扔进去就可以。实际上和这个low-level API没有太大区别。Predefined layers的效率稍微高一点,因为我们进行过优化,并且处理的场景多一些,但是如果你就喜欢自己写,也没有太大区别,只要保证运行就可以。
Q3:原来的Keras模型经过一次TF-MOT压缩,然后又经历一次TF Lite压缩,这两次压缩的区别是什么?
A:第一次模型压缩TF-MOT会把模型改掉,比如说模型里有一个矩阵,它可能就会把里面很多weights删掉,它的performance有可能有变化,classification的准确率也有可能有变化,但是TF Lite只是生成一个非常小的压缩好了的binary file,inference的时候消耗的资源也非常少,模型本身的准确率是不会有变化的。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“TensorFlow” 就可以获取《TensorFlow资料技术大全》专知下载链接








