机器之心 & ArXiv Weekly Radiostation
本周论文包括尤洋团队FastFold上线,训练时间从11天压缩至67小时;微软亚洲研究院直接把 Transformer 深度提升到 1000 层等研究。
FastFold: Reducing AlphaFold Training Time from 11 Days to 67 Hours
Transformer Memory as a Differentiable Search Index
DeepNet: Scaling Transformers to 1,000 Layers
The Quest for a Common Model of the Intelligent Decision Maker
GenéLive! Generating Rhythm Actions in Love Live!
Transformer Quality in Linear Time
FOURCASTNET: A GLOBAL DATA-DRIVEN HIGH-RESOLUTION WEATHER MODEL USING ADAPTIVE FOURIER NEURAL OPERATORS
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:FastFold: Reducing AlphaFold Training Time from 11 Days to 67 Hours
作者:Shenggan Cheng, Ruidong Wu, Zhongming Yu, Binrui Li, Xiwen Zhang, Jian Peng, Yang You
论文链接:https://arxiv.org/abs/2203.00854
摘要:
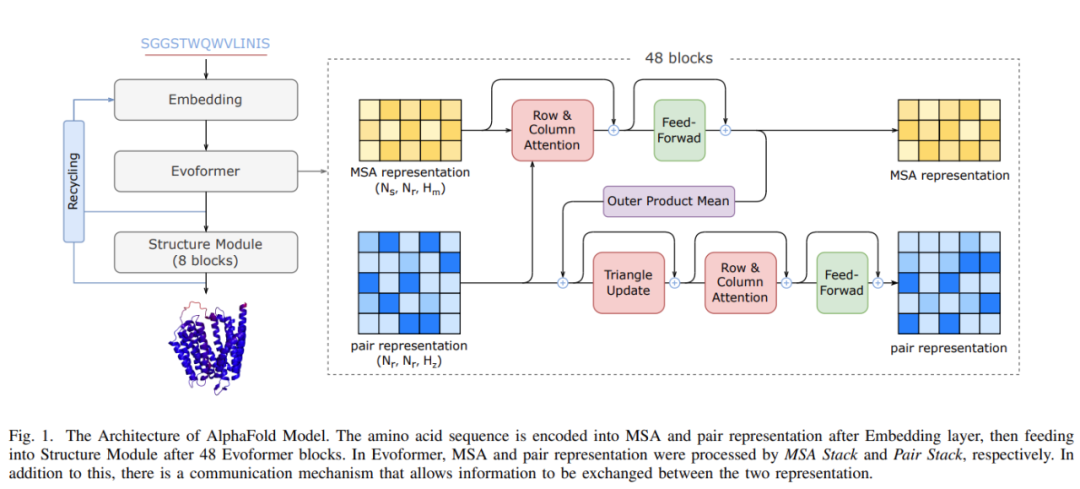
来自潞晨科技和上海交大的研究者提出了一种蛋白质结构预测模型的高效实现 FastFold。FastFold 包括一系列基于对 AlphaFold 性能全面分析的 GPU 优化。同时,通过动态轴并行和对偶异步算子,FastFold 提高了模型并行扩展的效率,超越了现有的模型并行方法。
实验结果表明,FastFold 将整体训练时间从 11 天减少到 67 小时,并实现了 7.5 ∼ 9.5 倍的长序列推理加速。此外,研究者还将 FastFold 扩展到 512 个 A100 GPU 的超算集群上,聚合峰值性能达到了 6.02PetaFLOPs,扩展效率达到 90.1%。
不同于一般的 Transformer 模型,AlphaFold 在 GPU 平台上的计算效率较低,主要面临两个挑战:1) 有限的全局批大小限制了使用数据并行性将训练扩展到更多节点,更大的批大小会导致准确率更低。即使使用 128 个谷歌 TPUv3 训练 AlphaFold 也需要约 11 天;2) 巨大的内存消耗超出了当前 GPU 的处理能力。在推理过程中,较长的序列对 GPU 内存的需求要大得多,对于 AlphaFold 模型,一个长序列的推理时间甚至可以达到几个小时。
![]()
作为首个用于蛋白质结构预测模型训练和推理的性能优化工作,FastFold 成功引入了大型模型训练技术,显著降低了 AlphaFold 模型训练和推理的时间和经济成本。FastFold 由 Evoformer 的高性能实现、AlphaFold 的主干结构和一种称为动态轴并行(Dynamic Axial Parallelism,DAP)的模型并行新策略组成。
![]()
推荐:
512 块 A100,AlphaFold 训练时间从 11 天压缩至 67 小时:尤洋团队 FastFold 上线。
论文 2:Transformer Memory as a Differentiable Search Index
摘要:
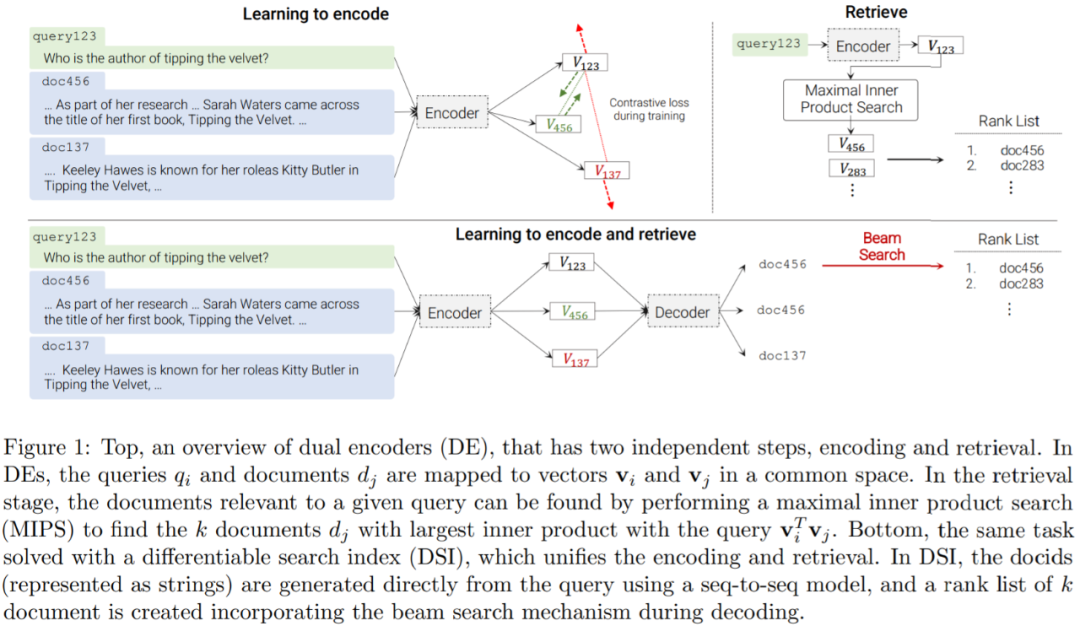
近日,谷歌研究院在论文《Transformer Memory as a Differentiable Search Index》中提出了一种替代架构,研究者采用序列到序列 (seq2seq) 学习系统。
该研究证明使用单个 Transformer 即可完成信息检索,其中有关语料库的所有信息都编码在模型的参数中。该研究引入了可微搜索索引(Differentiable Search Index,DSI),这是一种学习文本到文本新范式。DSI 模型将字符串查询直接映射到相关文档;换句话说,DSI 模型只使用自身参数直接回答查询,极大地简化了整个检索过程。
此外,本文还研究了如何表示文档及其标识符的变化、训练过程的变化以及模型和语料库大小之间的相互作用。实验表明,在适当的设计选择下,DSI 明显优于双编码器模型等强大基线,并且 DSI 还具有强大的泛化能力,在零样本设置中优于 BM25 基线。
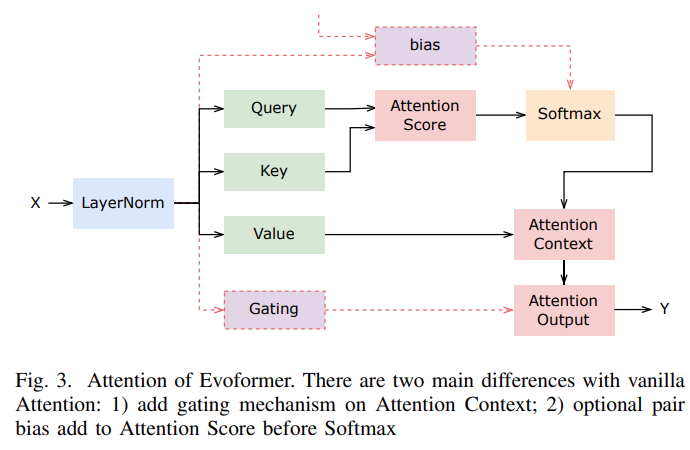
DSI 背后的核心思想是在单个神经模型中完全参数化传统的多阶段先检索后排序 pipeline。为此,DSI 模型必须支持两种基本操作模式:
在这两个操作之后,DSI 模型可以用来索引文档语料库,并对可用的带标记数据集(查询和标记文档)进行微调,然后用于检索相关文档 —— 所有这些都在单个、统一的模型中完成。与先检索后排序方法相反,DSI 模型允许简单的端到端训练,并且可以很容易地用作更大、更复杂的神经模型的可微组件。
![]()
![]()
推荐:
单个 Transformer 完成信息检索,谷歌用可微搜索索引打败双编码器模型。
论文 3:DeepNet: Scaling Transformers to 1,000 Layers
摘要
:微软亚洲研究院直接把 Transformer 深度提升到 1000 层!
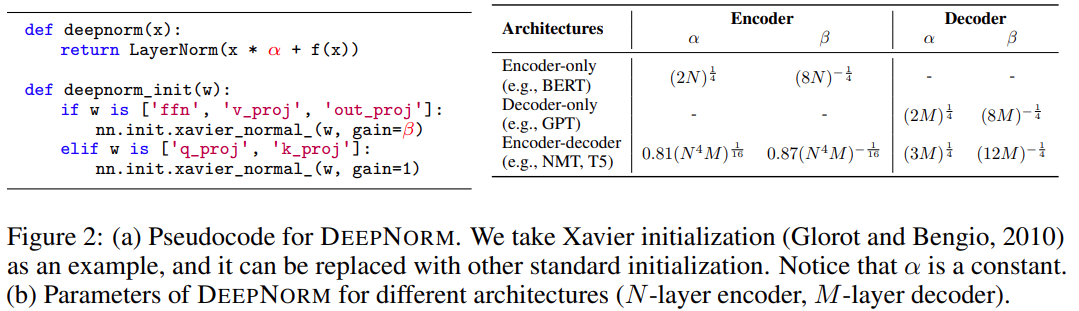
研究者的目标是提升 Transformer 模型的训练稳定性,并将模型深度进行数量级的扩展。为此,他们研究了不稳定优化的原因,并且发现爆炸式模型更新是造成不稳定的罪魁祸首。基于这些观察,研究者在残差连接处引入了一个新的归一化函数 —— DEEPNORM,它在将模型更新限制为常数时具有理论上的合理性。
这一方法简单但高效,只需要改变几行代码即可。最终,该方法提升了 Transformer 模型的稳定性,并实现了将模型深度扩展到了 1000 多层。
此外,实验结果表明,DEEPNORM 能够将 Post-LN 的良好性能和 Pre-LN 的稳定训练高效结合起来。研究者提出的方法可以成为 Transformers 的首选替代方案,不仅适用于极其深(多于 1000 层)的模型,也适用于现有大规模模型。值得指出的是,在大规模多语言机器翻译基准上,文中 32 亿参数量的 200 层模型(DeepNet)比 120 亿参数量的 48 层 SOTA 模型(即 Facebook AI 的 M2M 模型)实现了 5 BLEU 值提升。
如下图 2 所示,使用 PostLN 实现基于 Transformer 的方法很简单。与 Post-LN 相比,DEEPNORM 在执行层归一化之前 up-scale 了残差连接。
![]()
此外,该研究还在初始化期间 down-scale 了参数。值得注意的是,该研究只扩展了前馈网络的权重,以及注意力层的值投影和输出投影。此外,残差连接和初始化的规模取决于图 2 中不同的架构。
DeepNet 基于 Transformer 架构。与原版 Transformer 相比,DeepNet 在每个子层使用了新方法 DEEPNORM,而不是以往的 Post-LN。
推荐:
解决训练难题,1000 层的 Transformer 来了,训练代码很快公开。
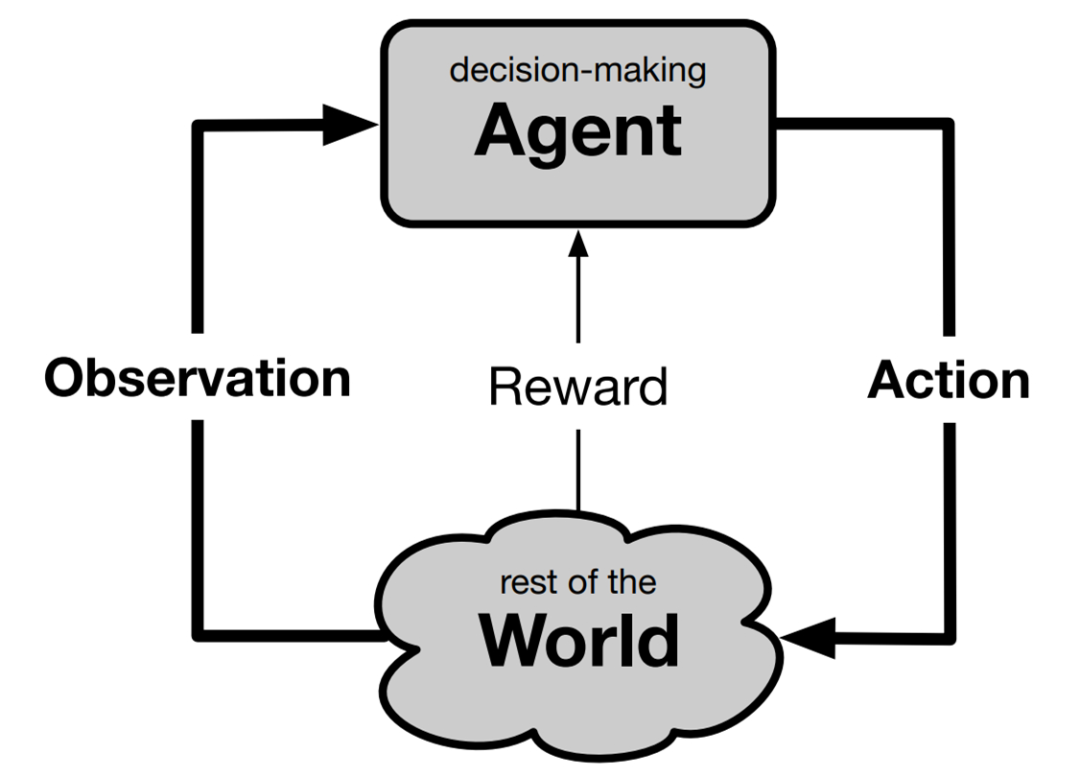
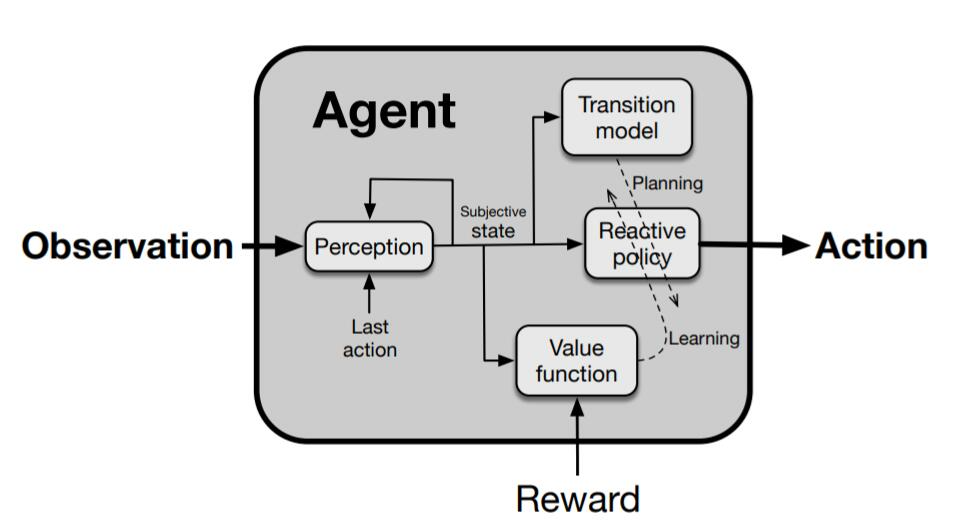
论文 4:The Quest for a Common Model of the Intelligent Decision Maker
摘要:
强化学习和决策多学科会议(Multi-Disciplinary Conference on Reinforcement Learning and Decision Making, RLDM)的重要前提是,随着时间的推移,多个学科对目标导向的决策有着共同的兴趣。
近日,阿尔伯塔大学计算机科学系教授、强化学习先驱 Richard S. Sutton 在其最新论文《The Quest for a Common Model of the Intelligent Decision Maker》中通过提出决策者的观点来加强和深化这一前提,该观点在心理学、人工智能、经济学、控制理论和神经科学等领域得到实质和广泛的应用,他称之为「智慧智能体的通用模型」。通常模型不包含任何特定于任何有机体、世界或应用域的东西,而涵盖了决策者与其世界交互的各个方面(必须有输入、输出和目标)以及决策者的内部组件(用于感知、决策、内部评估和世界模型)。
Sutton 确定了这些方面和组件,指出它们在不同学科中被赋予不同的名称,但本质上指向相同的思路。他探讨了设计一个可跨学科应用的中性术语面临的挑战和带来的益处,并表示是时候认可并在智慧智能体的实质性通用模型上构建多样化学科的融合了。
RLDM 的前提是所有对「随时间推移学习和决策以实现目标」感兴趣的学科融合在一起并共享观点是有价值的。心理学、神经科学等自然科学学科、人工智能、优化控制理论等工程科学学科以及经济学和人类学等社会科学学科都只部分关注智能决策者。各个学科的观点不同,但有相通的元素。跨学科的一个目标是确定共同核心,即决策者对所有或许多学科共有的那些方面。只要能够建立这样一个决策者的通用模型,就可以促进思想和成果的交流,进展可能会更快,获得的理解也可能会更加基础和持久。
探索决策者的通用模型并不新鲜。衡量其当前活力的一个重要指标是 RLDM 和 NeurIPS 等跨学科会议以及《神经计算》、《生物控制论》和《适应行为》等期刊的成功。很多科学洞见可以从跨学科互动中获得,例如贝叶斯方法在心理学中的广泛应用、多巴胺在神经科学中的奖励预测误差解释以及在机器学习中长期使用的神经网络隐喻。尽管很多这些学科之间的重要关系与学科本身一样古老,但远远未解决。为了找到学科之间、甚至一个学科内部之间的共性,人们必须忽略很多分歧。我们必须要有选择性,从大局出发,不要期望没有例外发生。
因此,在这篇论文中,Sutton 希望推进对智能决策者模型的探索。首先明确地将探索与富有成效的跨学科互动区分开来;其次强调目标是作为高度跨学科的累积数值信号的最大化;接着又强调了决策者的特定内部结构,即以特定方式交互的四个主要组件,它们为多个学科所共有;最后突出了掩盖领域之间共性的术语差异,并提供了鼓励多学科思维的术语。
![]()
![]()
推荐:
强化学习教父 Richard Sutton 新论文探索决策智能体的通用模型:寻找跨学科共性。
论文 5:GenéLive! Generating Rhythm Actions in Love Live!
摘要:
最近,预印版论文平台 arXiv 上的一篇论文引起了人们的注意,其作者来自游戏开发商 KLab 和九州大学。他们提出了一种给偶像歌曲自动写谱的模型,更重要的是,作者表示这种方法其实已经应用过很长一段时间了。
KLab 等机构提交的论文介绍了自己的节奏动作游戏生成模型。KLab Inc 是一家智能手机游戏开发商。该公司在线运营的节奏动作游戏包括《Love Live!学院偶像季:群星闪耀》(简称 LLAS)已以 6 种语言在全球发行,获得了上千万用户。已经有一系列具有类似影响的类似游戏,这使得该工作与大量玩家密切相关。
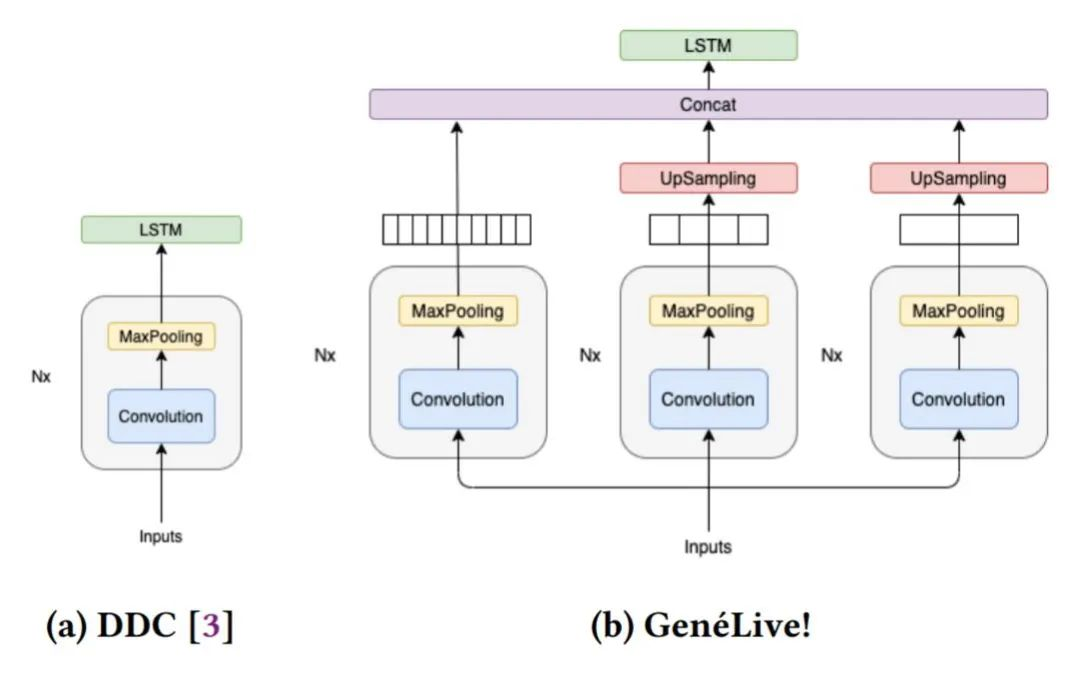
在研究过程中,开发者们首先提出了 Dance Dance Convolution (DDC) ,生成了具有人类高水平的,较高难度游戏模式的乐谱,但低难度反而效果不好。随后研究者们通过改进数据集和多尺度 conv-stack 架构,成功捕捉了乐谱中四分音符之间的时间依赖性以及八分音符和提示节拍的位置,它们是音游中放置按键的较好时机。
DDC 由两个子模型组成:onset(生成音符的时机)和 sym(决定音符类型,如轻按或滑动)目前正在使用的 AI 模型在所有难度的曲谱上都获得了很好的效果,研究人员还展望了该技术扩展到其他领域的可能性。
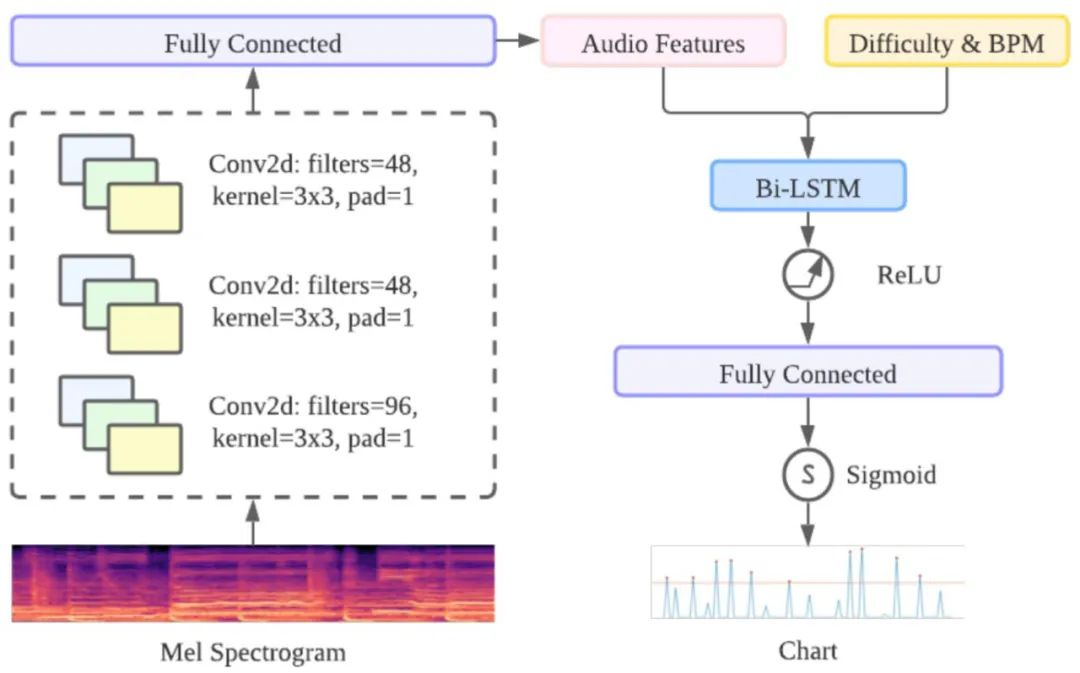
GenéLive! 的基础模型由卷积神经网络 CNN 层和长短期记忆网络 LSTM 层组成。对于频域中的信号,作者利用 CNN 层来捕获频率特征,对于时域利用 LSTM 层来完成任务。
![]()
时域方面采用了 BiLSTM,提供前一个 conv-stack 的输出作为输入。为了实现不同的难度模式,作者将难度编码为一个标量(初级是 10,中级是 20,以此类推)并将这个值作为新特征附加到 convstack 的输出中。
![]()
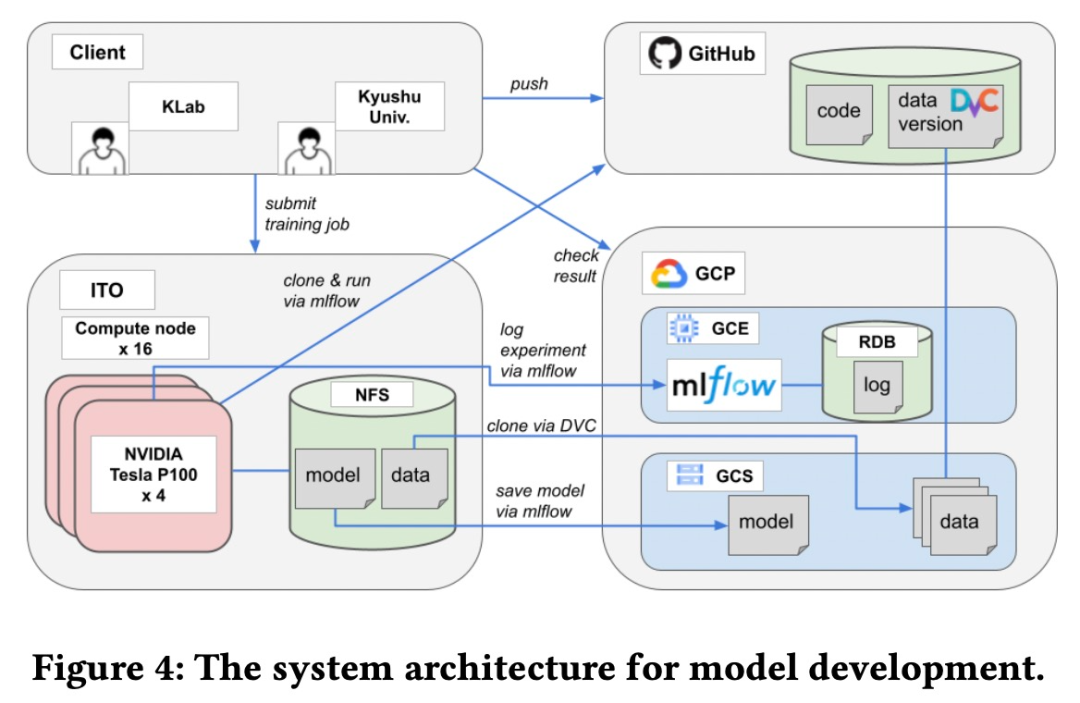
该模型是由 KLab 和九州大学合作完成的。两个团队之间需要一个基于 Web 的协作平台来共享源代码、数据集、模型和实验等。具体来说,该研究用于模型开发的系统架构如下图所示。
![]()
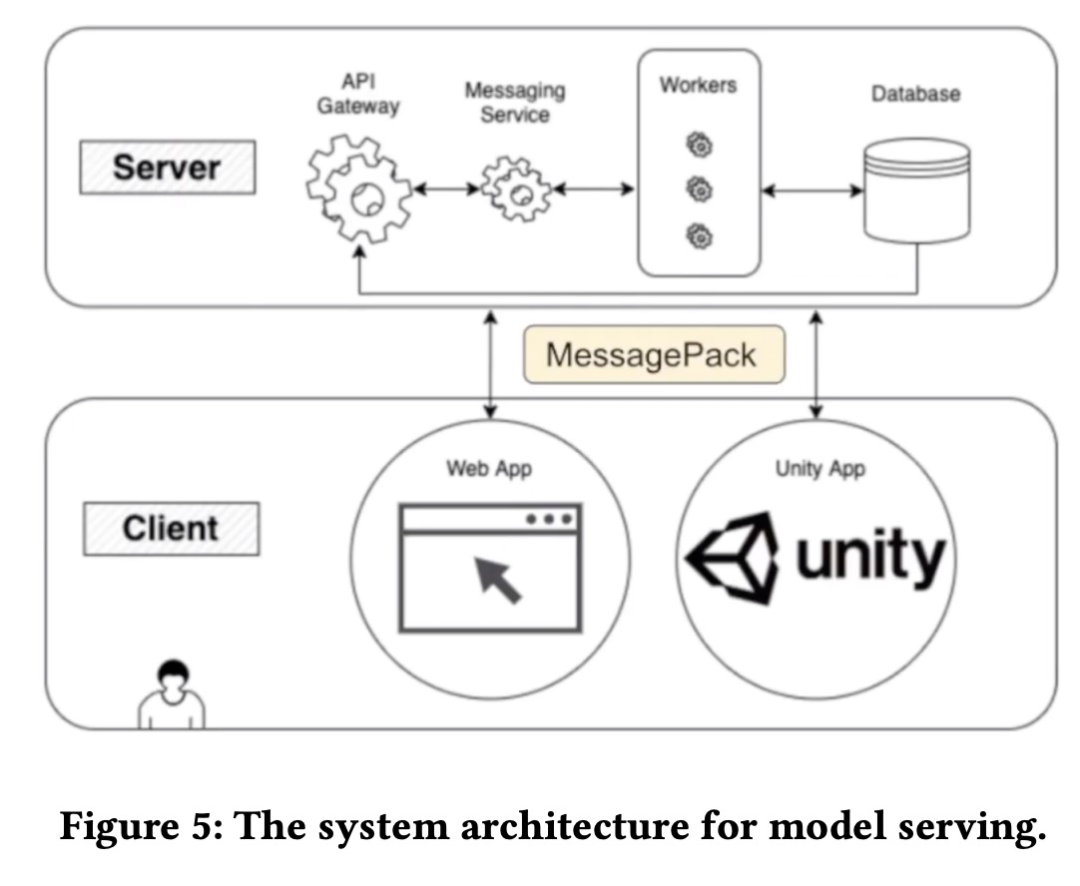
为了使乐谱生成程序可供艺术家按需使用,它应该方便艺术家自行使用而无需 AI 工程师的帮助。并且由于该程序需要高端 GPU,将其安装在艺术家的本地计算机上并不是一个合适的选择。该模型服务系统架构如下图所示。
![]()
推荐:
LoveLive! 出了一篇 AI 论文:生成模型自动写曲谱。
论文 6:Transformer Quality in Linear Time
摘要:
来自康奈尔大学、谷歌大脑的研究人员近日提出了一个新模型 FLASH(Fast Linear Attention with a Single Head),首次不仅在质量上与完全增强的 Transformer 相当,而且在现代加速器的上下文大小上真正享有线性可扩展性。与旨在逼近 Transformers 中的多头自注意力 (MHSA) 的现有高效注意力方法不同,谷歌从一个新层设计开始,自然地实现更高质量的逼近。FLASH 分两步开发:
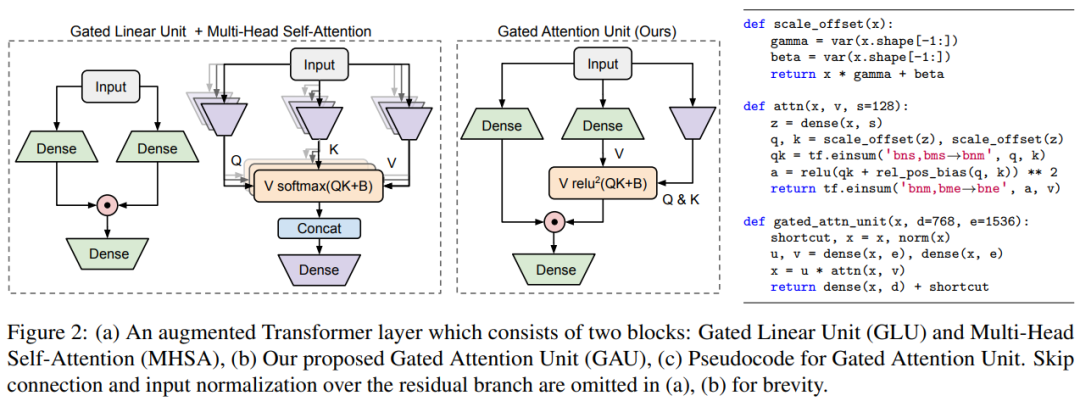
首先设置一个更适合有效近似的新层,引入门控机制来减轻自注意力的负担,产生了下图 2 中的门控注意力单元 (Gated Attention Unit, GAU)。与 Transformer 层相比,每个 GAU 层更便宜。更重要的是,它的质量更少依赖于注意力精度。事实上,小单头、无 softmax 注意力的 GAU 与 Transformers 性能相近。
随后作者提出了一种有效的方法来逼近 GAU 中的二次注意力,从而导致在上下文大小上具有线性复杂度的层变体。其思路是首先将标记分组为块,然后在一个块内使用精确的二次注意力和跨块的快速线性注意力(如下图 4 所示)。在论文中,研究者进一步描述了如何利用此方法自然地推导出一个高效的加速器实现,在实践中做到只需更改几行代码的线性可扩展能力。
在大量实验中,FLASH 在各种任务、数据集和模型尺度上均效果很好。FLASH 在质量上与完全增强的 Transformer (Transformer++) 相比具有竞争力,涵盖了各种实践场景的上下文大小 (512-8K),同时在现代硬件加速器上实现了线性可扩展。
例如,在质量相当的情况下,FLASH 在 Wiki-40B 上的语言建模实现了 1.2 倍至 4.9 倍的加速,在 Transformer++ 上 C4 上的掩码语言建模实现了 1.0 倍至 4.8 倍的加速。在进一步扩展到 PG-19 (Rae et al., 2019) 之后,FLASH 将 Transformer++ 的训练成本降低了 12.1 倍,并实现了质量的显着提升。
研究者首先提出了门控注意力单元(Gated Attention Unit, GAU),这是一个比 Transformers 更简单但更强的层。
![]()
研究者在下图 3 中展示了 GAU 与 Transformers 的比较情况,结果显示对于不同模型大小,GAU 在 TPUs 上的性能可与 Transformers 竞争。需要注意,这些实验是在相对较短的上下文大小(512)上进行的。
![]()
推荐:
谷歌 Quoc Le 团队新 transformer:线性可扩展,训练成本仅有原版 1/12。
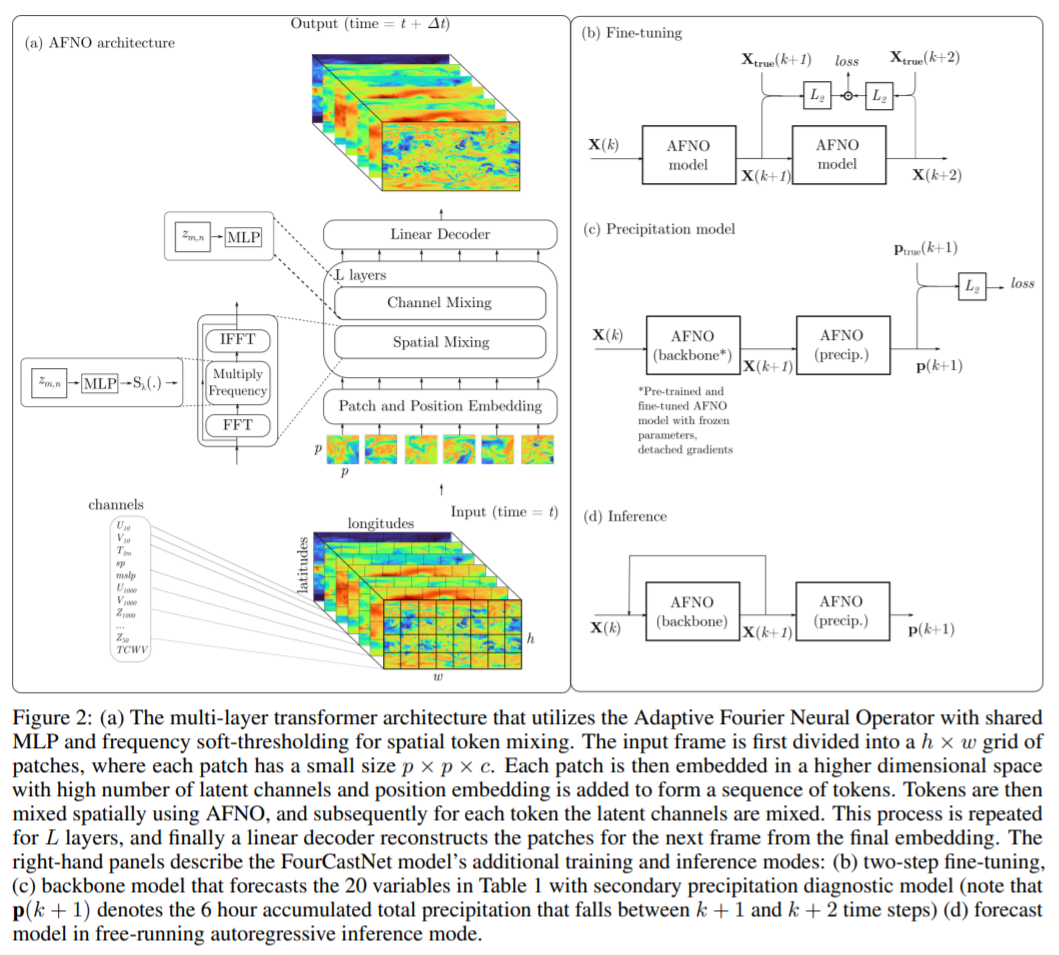
论文 7:FOURCASTNET: A GLOBAL DATA-DRIVEN HIGH-RESOLUTION WEATHER MODEL USING ADAPTIVE FOURIER NEURAL OPERATORS
摘要:
在近日的一篇论文中,英伟达、劳伦斯伯克利国家实验室、密歇根大学安娜堡分校、莱斯大学等机构的研究者开发了一种基于傅里叶的神经网络预测模型 FourCastNet,它能以 0.25° 的分辨率生成关键天气变量的全球数据驱动预测,相当于赤道附近大约 30×30 km 的空间分辨率和 720×1440 像素的全球网格大小。这使得我们首次能够与欧洲中期天气预报中心(ECMWF)的高分辨率综合预测系统(IFS)模型进行直接比较。
FourCastNet 在节点小时(node-hour)基础上比传统 NWP 模型快约 45,000 倍。FourCastNet 这种数量级的加速以及在高分辨率下前所未有的准确性,使得它能够以很低的成本生成超大规模集合预测。FourCastNet 极大地改善了概率天气预报的效果,使用它可以在几秒钟内生成对飓风、大气层河流和极端降水等事件的大规模集合预报,从而可以实现更及时、更明智的灾难响应。
此外,FourCastNet 对近地表风速的可靠、快速和低廉预测可以改善陆海风电场的风能资源规划。训练 FourCastNet 所需的能量大约等于使用 IFS 模型生成 10 天预测所需的能量(50 个成员)。然而,一旦经过训练,FourCastNet 生成预测所需的能量比 IFS 模型少 12,000 倍。研究者希望 FourCastNet 只训练一次,并且后续微调的能耗可以忽略不计。
在实现技术上,FourCastNet 使用基于傅里叶变换的 token 混合方法 [Guibas et al., 2022] 和 ViT 骨干 [Dosovitskiy et al., 2021]。这一方法基于最近的的傅里叶神经算子,该算子以分辨率不变的方式学习,并在建模流体动力学等具有挑战性的偏微分方程中取得了成功。此外,他们选择 ViT 骨干的原因是它能够很好地建模长程依赖。ViT 和基于傅里叶的 token 方法混合生成了 SOTA 高分辨率模型,它可以解析细粒度的特征,并能够很好地随分辨率和数据集大小扩展。研究者表示,这一方法能够以真正前所未有的高分辨率训练高保真数据驱动的模型。
欧洲中期天气预报中心(ECMWF)提供了一个公开可用的综合数据集 ERA5,该研究使用 ERA5 来训练 FourCastNet。他们专注于两个大气变量,即(1)距离地球表面 10m 处的风速和(2)6 小时总降水量,除此以外,该研究还预测了其他几个变量,包括几个不同垂直高度的位势高度、温度、风速和相对湿度,一些近地表变量,如地面气压和平均海平面气压以等。
整个训练过程是在 64 个 Nvidia A100 GPU 的集群上完成,端到端训练大约需要 16 小时。
![]()
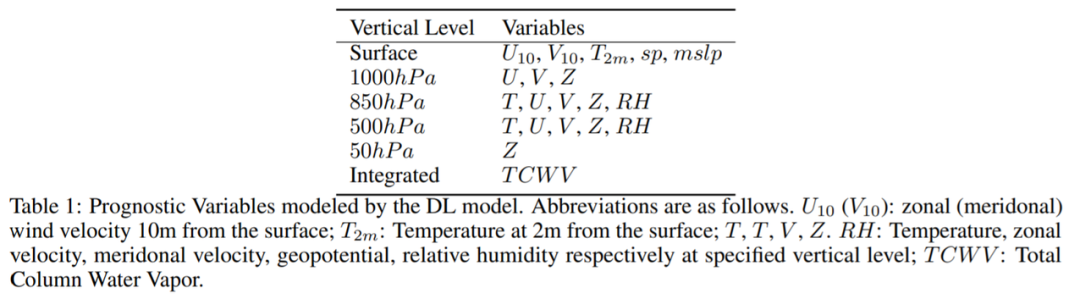
该研究选择了一些变量(表 1)来表示大气的瞬时状态:
![]()
推荐:
速度提升 45000 倍,英伟达用傅里叶模型实现前所未有天气预报准确率。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Attend, Memorize and Generate: Towards Faithful Table-to-Text Generation in Few Shots. (from Philip S. Yu)
2. Improving Candidate Retrieval with Entity Profile Generation for Wikidata Entity Linking. (from ChengXiang Zhai)
3. Exploring the Impact of Negative Samples of Contrastive Learning: A Case Study of Sentence Embeddin. (from Zheng Wang)
4. AugESC: Large-scale Data Augmentation for Emotional Support Conversation with Pre-trained Language Models. (from Minlie Huang)
5. Transformer Grammars: Augmenting Transformer Language Models with Syntactic Inductive Biases at Scale. (from Phil Blunsom, Chris Dyer)
6. Multi-Sentence Knowledge Selection in Open-Domain Dialogue. (from Yang Liu, Dilek Hakkani-Tur)
7. Integrating Text Inputs For Training and Adapting RNN Transducer ASR Models. (from Brian Kingsbury)
8. Towards Reducing the Need for Speech Training Data To Build Spoken Language Understanding Systems. (from Brian Kingsbury)
9. Parameter-Efficient Mixture-of-Experts Architecture for Pre-trained Language Models. (from Ji-Rong Wen)
10. DAMO-NLP at SemEval-2022 Task 11: A Knowledge-based System for Multilingual Named Entity Recognition. (from Yueting Zhuang)
1. The Right Spin: Learning Object Motion from Rotation-Compensated Flow Fields. (from Erik Learned-Miller, Cordelia Schmid)
2. A Unified Query-based Paradigm for Point Cloud Understanding. (from Bernt Schiele, Jiaya Jia)
3. Vision-Language Intelligence: Tasks, Representation Learning, and Large Models. (from Lei Zhang)
4. DN-DETR: Accelerate DETR Training by Introducing Query DeNoising. (from Lei Zhang)
5. BatchFormer: Learning to Explore Sample Relationships for Robust Representation Learning. (from Dacheng Tao)
6. Robust Self-Supervised LiDAR Odometry via Representative Structure Discovery and 3D Inherent Error Modeling. (from Xiaogang Wang)
7. Local and Global GANs with Semantic-Aware Upsampling for Image Generation. (from Ling Shao, Philip H.S. Torr, Nicu Sebe)
8. Concept Graph Neural Networks for Surgical Video Understanding. (from Daniela Rus)
9. Generalizable Person Re-Identification via Self-Supervised Batch Norm Test-Time Adaption. (from Liang Wang, Tieniu Tan)
10. A Multi-scale Transformer for Medical Image Segmentation: Architectures, Model Efficiency, and Benchmarks. (from Dimitris Metaxas)
1. Learning Dynamic Mechanisms in Unknown Environments: A Reinforcement Learning Approach. (from Michael I. Jordan)
2. Off-Policy Evaluation with Policy-Dependent Optimization Response. (from Michael I. Jordan)
3. Biological error correction codes generate fault-tolerant neural networks. (from Max Tegmark)
4. HighMMT: Towards Modality and Task Generalization for High-Modality Representation Learning. (from Louis-Philippe Morency, Ruslan Salakhutdinov)
5. Structure from Voltage. (from Yoav Freund)
6. Providing Insights for Open-Response Surveys via End-to-End Context-Aware Clustering. (from Brian Williams)
7. Integrated multimodal artificial intelligence framework for healthcare applications. (from Dimitris Bertsimas)
8. Faster One-Sample Stochastic Conditional Gradient Method for Composite Convex Minimization. (from Gunnar Rätsch)
9. Keeping Minimal Experience to Achieve Efficient Interpretable Policy Distillation. (from Yang Gao)
10. A Quantitative Geometric Approach to Neural Network Smoothness. (from Somesh Jha)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com