【SIGIR2018】五篇对抗训练文章
【导读】与大家分享五篇SIGIR2018上对抗(Adverarial)相关的文章。


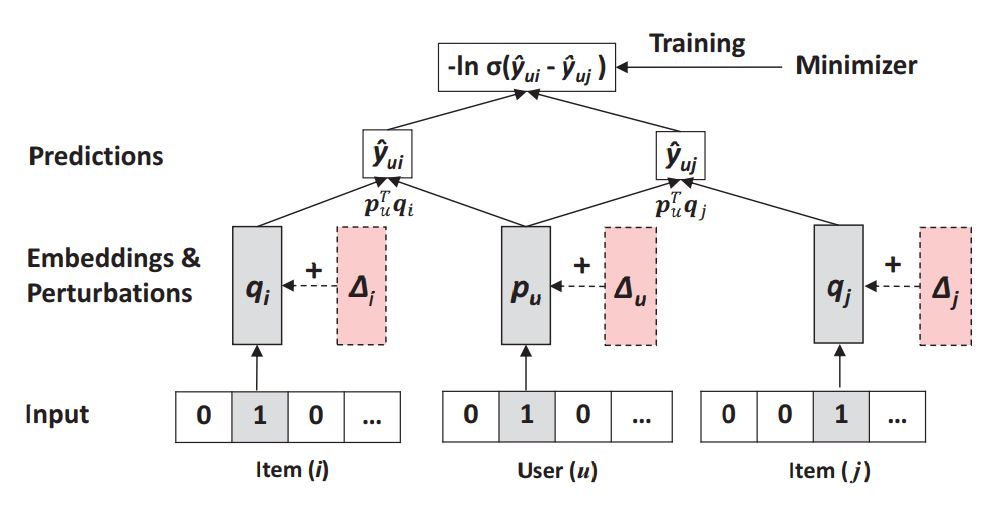
Adversarial Personalized Ranking for Recommendation
Xiangnan He; Zhankui He; Xiaoyu Du; Tat-Seng Chua
Item recommendation is a personalized ranking task. To this end, many recommender systems optimize models with pairwise ranking objectives, such as the Bayesian Personalized Ranking (BPR). Using matrix Factorization (MF) — the most widely used model in recommendation — as a demonstration, we show that optimizing it with BPR leads to a recommender model that is not robust. In particular, we find that the resultant model is highly vulnerable to adversarial perturbations on its model parameters, which implies the possibly large error in generalization.
To enhance the robustness of a recommender model and thus improve its generalization performance, we propose a new optimization framework, namely Adversarial Personalized Ranking (APR). In short, our APR enhances the pairwise ranking method BPR by performing adversarial training. It can be interpreted as playing a minimax game, where the minimization of the BPR objective function meanwhile defends an adversary, which adds adversarial perturbations on model parameters to maximize the BPR objective function. To illustrate how it works, we implement APR on MF by adding adversarial perturbations on the embedding vectors of users and items. Extensive experiments on three public real-world datasets demonstrate the effectiveness of APR — by optimizing MF with APR, it outperforms BPR with a relative improvement of 11.2% on average and achieves state-of-the-art performance for item recommendation. Our implementation is available at: https://github.com/hexiangnan/adversarial_personalized_ranking

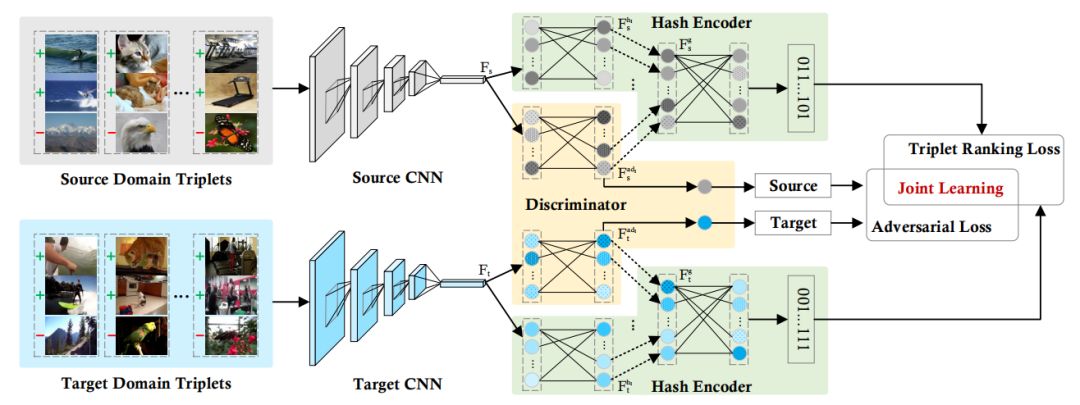
Deep Domain Adaptation Hashing with Adversarial Learning
Fuchen Long; Ting Yao; Qi Dai; Xinmei Tian; Jiebo Luo; Tao Mei
The recent advances in deep neural networks have demonstrated high capability in a wide variety of scenarios. Nevertheless, finetuning deep models in a new domain still requires a significant amount of labeled data despite expensive labeling efforts. A valid question is how to leverage the source knowledge plus unlabeled or only sparsely labeled target data for learning a new model in target domain. The core problem is to bring the source and target distributions closer in the feature space. In the paper, we facilitate this issue in an adversarial learning framework, in which a domain discriminator is devised to handle domain shift. Particularly, we explore the learning in the context of hashing problem, which has been studied extensively due to its great efficiency in gigantic data. Specifically, a novel Deep Domain Adaptation Hashing with Adversarial learning (DeDAHA) architecture is presented, which mainly consists of three components: a deep convolutional neural networks (CNN) for learning basic image/frame representation followed by an adversary stream on one hand to optimize the domain discriminator, and on the other, to interact with each domain-specific hashing stream for encoding image representation to hash codes. The whole architecture is trained end-to-end by jointly optimizing two types of losses, i.e., triplet ranking loss to preserve the relative similarity ordering in the input triplets and adversarial loss to maximally fool the domain discriminator with the learnt source and target feature distributions. Extensive experiments are conducted on three domain transfer tasks, including cross-domain digits retrieval, image to image and image to video transfers, on several benchmarks. Our DeDAHA framework achieves superior results when compared to the state-of-the-art techniques.

Ranking Robustness under Adversarial Document Manipulations
Gregory Goren; Fiana Raiber; Moshe Tennenholtz ; Oren Kurland
For many queries in the Web retrieval setting there is an on-going ranking competition: authors manipulate their documents so as to promote them in rankings. Such competitions can have unwarranted effects not only in terms of retrieval effectiveness, but also in terms of ranking robustness. A case in point, rankings can (rapidly) change due to small indiscernible perturbations of documents. While there has been a recent growing interest in analyzing the robustness of classifiers to adversarial manipulations, there has not yet been a study of the robustness of relevance-ranking functions. We address this challenge by formally analyzing different definitions and aspects of the robustness of learning-to-rank-based ranking functions. For example, we formally show that increased regularization of linear ranking functions increases ranking robustness. This finding leads us to conjecture that decreased variance of any ranking function results in increased robustness. We propose several measures for quantifying ranking robustness and use them to analyze ranking competitions between documents’ authors. The empirical findings support our formal analysis and conjecture for both RankSVM and LambdaMART.

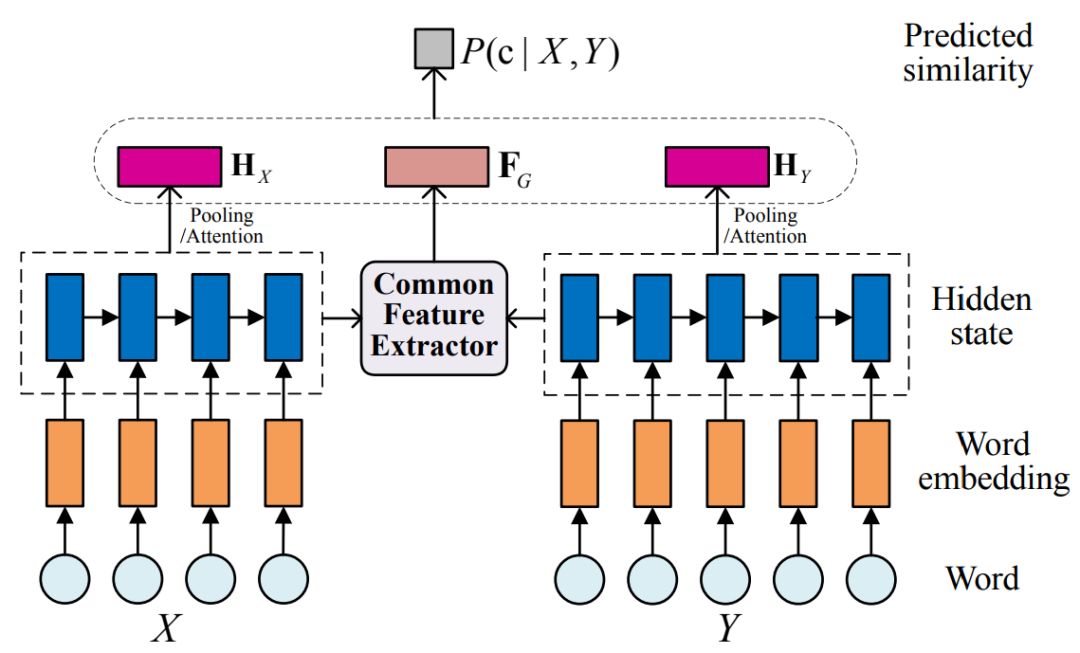
CAN: Enhancing Sentence Similarity Modeling with Collaborative and Adversarial Network
Qin Chen; Qinmin Hu; Jimmy Huang ; Liang He
The neural networks have attracted great attention for sentence similarity modeling in recent years. Most neural networks focus on the representation of each sentence, while the common features of a sentence pair are not well studied. In this paper, we propose a Collaborative and Adversarial Network (CAN), which explicitly models the common features between two sentences for enhancing sentence similarity modeling. To be specific, a common feature extractor is presented and embedded into our CAN model, which includes a generator and a discriminator playing a collaborative and adversarial game for common feature extraction. Experiments on three benchmark datasets, namely TREC-QA and WikiQA for answer selection and MSRP for paraphrase identification, show that our proposed model is effective to boost the performance of sentence similarity modeling. In particular, our proposed model outperforms the state-of-the-art approaches on TREC-QA without using any external resources or pre-training. For the other two datasets, our model is also comparable to if not better than the recent neural network approaches.

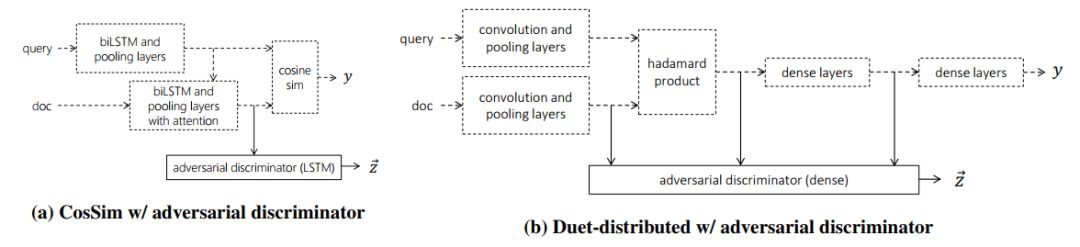
Cross Domain Regularization for Neural Ranking Models using Adversarial Learning
Daniel Cohen; Bhaskar Mitra; Katja Hofmann; Bruce Croft
Unlike traditional learning to rank models that depend on handcrafted features, neural representation learning models learn higher level features for the ranking task by training on large datasets. Their ability to learn new features directly from the data, however, may come at a price. Without any special supervision, these models learn relationships that may hold only in the domain from which the training data is sampled, and generalize poorly to domains not observed during training. We study the effectiveness of adversarial learning as a cross domain regularizer in the context of the ranking task. We use an adversarial discriminator and train our neural ranking model on a small set of domains. The discriminator provides a negative feedback signal to discourage the model from learning domain specific representations. Our experiments show consistently better performance on held out domains in the presence of the adversarial discriminator—sometimes up to 30% on precision@1.
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!
请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知




