5种数据同分布的检测方法!
![]()
来源:datawhale
本文约2061字,建议阅读4分钟
本文介绍了几种数据同分布检验方法。

一、KS检验
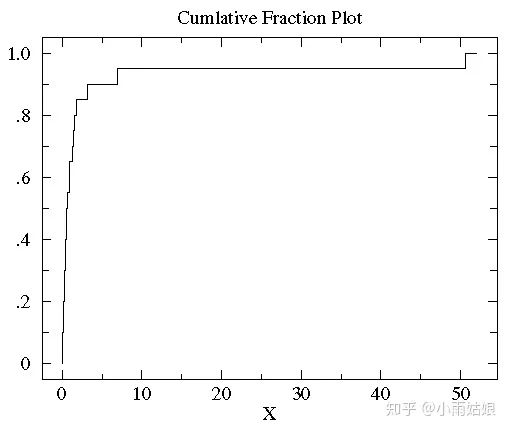
1. 画出数据的累积分段图
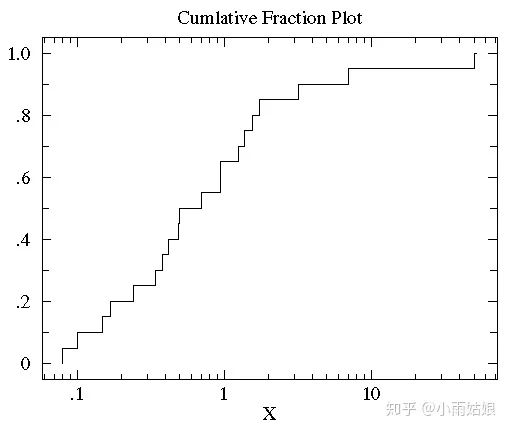
2. 对于累积分布图取Log变换
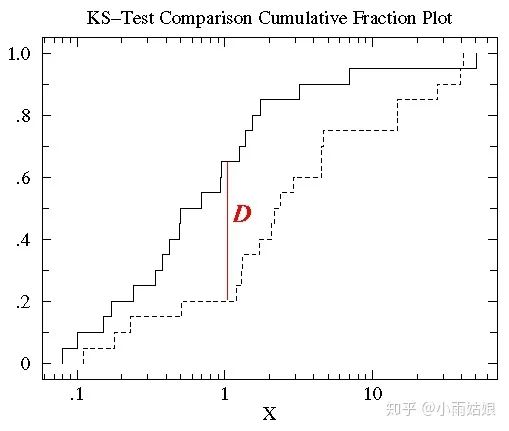
3. 通过两个数据的累积分布图直接最大垂直距离描述两数据的差异
from scipy.stats import ks_2samp
ks_2samp(train[col],test[col]).pvalue
二、Overlap Rate
训练集特征:[猫,狗,狗,猫,狗,狗,狗,猫]
测试集特征:[猫,猫,鱼,猪,鱼,鱼,猪,猪]
三、KL散度
训练集特征:[猫,猫,鱼,猪,鱼,鱼,猪,猪]
测试集特征:[猫,狗,狗,狗,狗,狗,狗,狗]


KL 散度是一种衡量两个概率分布的匹配程度的指标,两个分布差异越大,KL散度越大。注意如果要查看测试集特征是否与训练集相同,P代表训练集,Q代表测试集,这个公式对于P和Q并不是对称的。
四、KDE 核密度估计
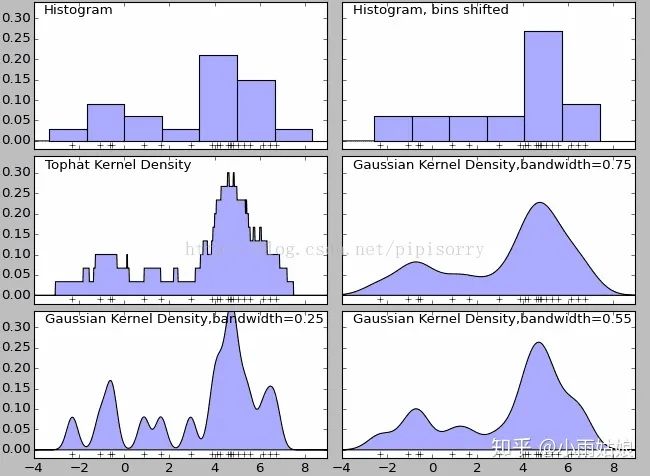
>>> import numpy as np; np.random.seed(10)
>>> import seaborn as sns; sns.set(color_codes=True)
>>> mean, cov = [0, 2], [(1, .5), (.5, 1)]
>>> x, y = np.random.multivariate_normal(mean, cov, size=50).T
>>> ax = sns.kdeplot(x)
五、机器学习模型检测
六、参考



登录查看更多
相关内容

Arxiv
11+阅读 · 2021年2月18日
Arxiv
5+阅读 · 2018年12月15日
Arxiv
6+阅读 · 2018年1月20日




相关VIP内容
相关资讯
相关论文
Arxiv
11+阅读 · 2021年2月18日
Arxiv
5+阅读 · 2018年12月15日
Arxiv
6+阅读 · 2018年1月20日