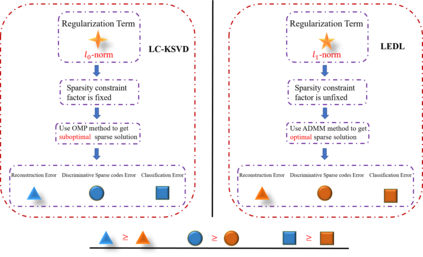
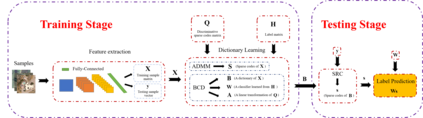
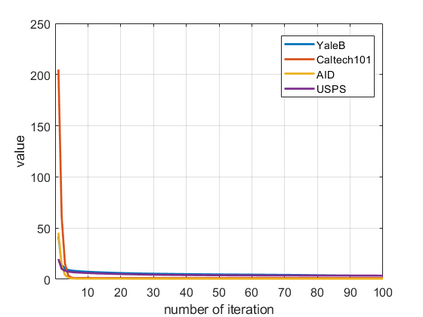
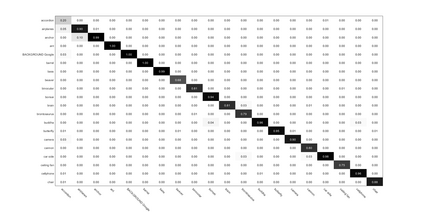
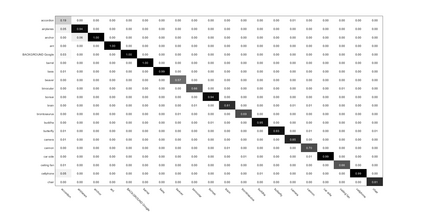
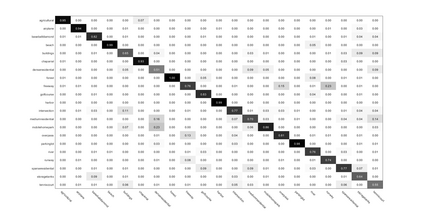
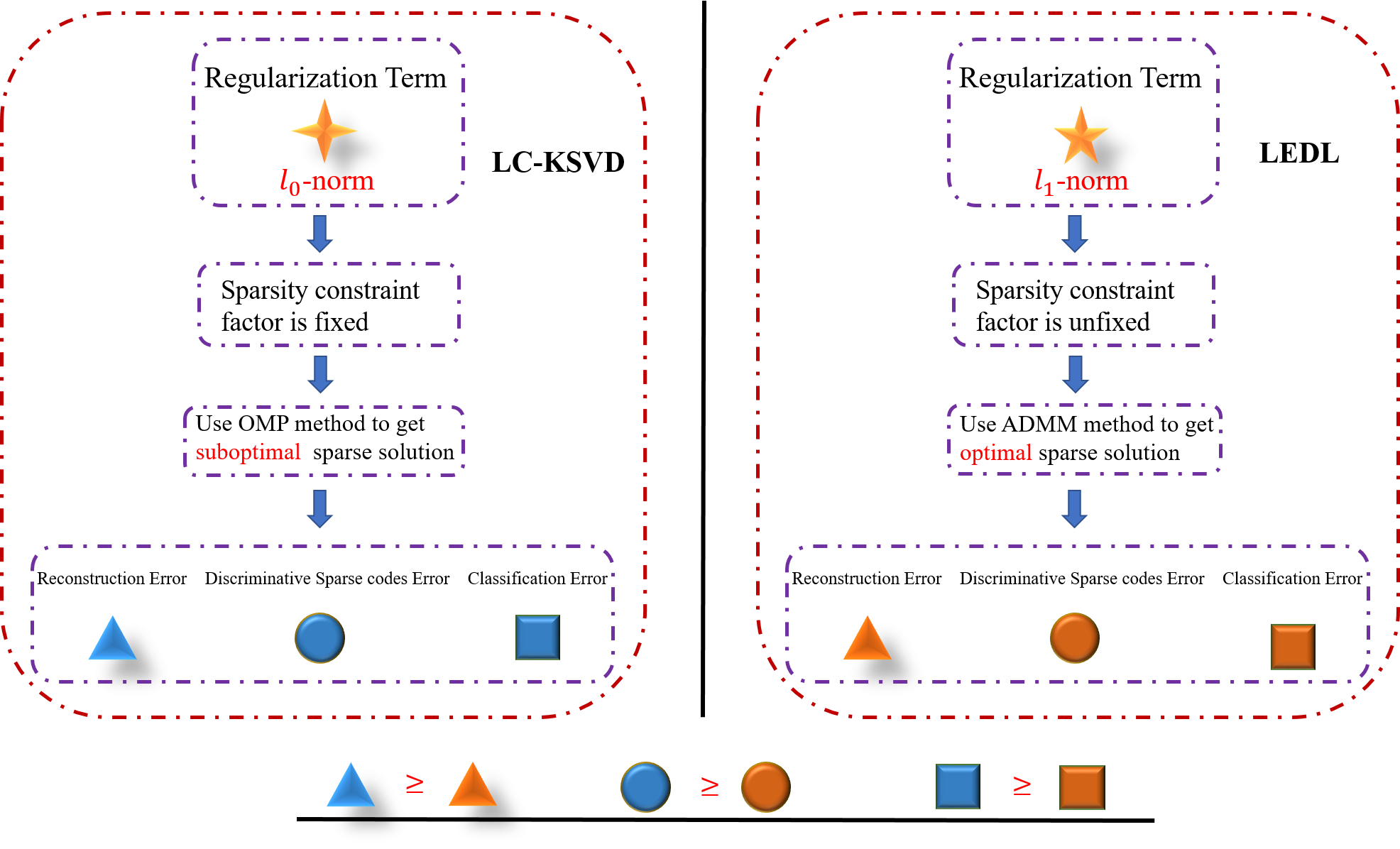
Recently, label consistent k-svd(LC-KSVD) algorithm has been successfully applied in image classification. The objective function of LC-KSVD is consisted of reconstruction error, classification error and discriminative sparse codes error with l0-norm sparse regularization term. The l0-norm, however, leads to NP-hard issue. Despite some methods such as orthogonal matching pursuit can help solve this problem to some extent, it is quite difficult to find the optimum sparse solution. To overcome this limitation, we propose a label embedded dictionary learning(LEDL) method to utilise the $\ell_1$-norm as the sparse regularization term so that we can avoid the hard-to-optimize problem by solving the convex optimization problem. Alternating direction method of multipliers and blockwise coordinate descent algorithm are then used to optimize the corresponding objective function. Extensive experimental results on six benchmark datasets illustrate that the proposed algorithm has achieved superior performance compared to some conventional classification algorithms.
翻译:最近, K- svd( LC- KSVD) 标签一致的 k- svd( LC- KSVD) 算法在图像分类中成功应用。 LC- KSVD 的客观功能包括重建错误、 分类错误和以 l0- norm 稀释身份规范化术语的歧视性稀释代码错误。 但是, l0- norm 导致NP 硬问题。 尽管有些方法, 如正方形匹配追踪可以在某种程度上帮助解决这个问题, 但很难找到最佳的稀释解决方案。 要克服这一限制, 我们建议使用一个标签嵌入字典学习( LEDL) 方法, 将 $\ ell_ 1$- norm 用作稀释身份规范化术语, 这样我们就可以通过解决 convex 优化问题避免难以优化的问题。 然后, 将乘数和阻断式协调下位算法的定向方法用于优化相应的目标函数。 六个基准数据集的广泛实验结果显示, 与一些常规分类算法相比, 已经实现了更高的性 。