AAAI 2021 | 幻灯片中文字的重要性预测赛亚军DeepBlueAI团队技术分享


赛题介绍


比赛任务
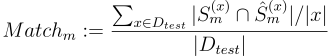

团队成绩


比赛难点

数据描述
|
|
Total Slides |
Total Sentences |
Total Tokens |
|
训练集 |
1241 |
8849 |
96934 |
|
验证集 |
180 |
1175 |
12822 |
|
测试集 |
355 |
2569 |
28108 |
▲ 表1:训练集、验证集、测试集描述
|
|
最小长度 |
最大长度 |
平均长度 |
|
训练集 |
1241 |
8849 |
96934 |
|
验证集 |
180 |
1175 |
12822 |
|
测试集 |
355 |
2569 |
28108 |
▲ 表2:数据集句子长度
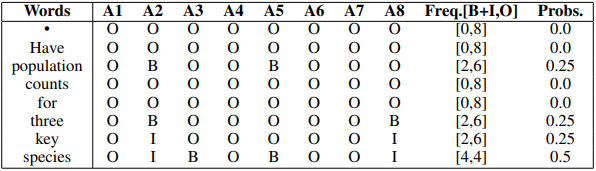
▲ 表3:数据集标注案例

数据处理和特征工程

模型概述
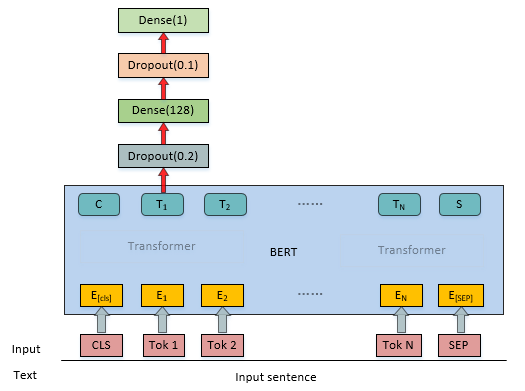

总结与讨论

参考文献
1. Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
2. Liu Y, Ott M, Goyal N, et al. Roberta: A robustly optimized bert pretraining approach[J]. arXiv preprint arXiv:1907.11692, 2019.
3. Miyato, T., Dai, A.M., & Goodfellow, I.J. (2016). Virtual Adversarial Training for Semi-Supervised Text Classification. ArXiv, abs/1605.07725.
4. Zhang, Z., Han, X., Liu, Z., Jiang, X., Sun, M., & Liu, Q. (2019). ERNIE: Enhanced Language Representation with Informative Entities. ACL.
5. Shirani, A.; Tran, G.; Trinh, H.; Dernoncourt, F.; Lipka, N.; Asente, P.; Echevarria, J.; and Solorio, T. 2021. Learning to Emphasize: Dataset and Shared Task Models for Selecting Emphasis in Presentation Slides. In Proceedings of CAD21 workshop at the Thirty-fifth AAAI Conference on Artificial Intelligence (AAAI-21).
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。






