点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文转载自机器之心。
近日,在 ICCV 2019 Workshop 举办的 Vision Meets Drone: A Challenge(简称:VisDrone2019) 挑战赛公布了最终结果,来自深兰科技北京 AI 研发中心的 DeepBlueAI 团队斩获了「视频目标检测」和「多目标追踪」两项冠军。我们可以通过这篇文章来了解一下 DeepBlueAI 团队的解决方案。
![]()
如今,配备摄像头的无人机或通用无人机已经广泛地应用在农业、航空摄影、快速交付、监视等多个领域。
挑战赛官网地址:http://aiskyeye.com/
VisDrone2019 数据集由天津大学机器学习与数据挖掘实验室 AISKYEYE 队伍负责收集,全部基准数据集由无人机捕获,包括 288 个视频片段,总共包括 261908 帧和 10209 个静态图像。
这些帧由 260 多万个常用目标(如行人、汽车、自行车和三轮车)的手动标注框组成。为了让参赛队伍能够更有效地利用数据,数据集还提供了场景可见性、对象类别和遮挡等重要属性。
任务 1:图像中的目标检测。任务旨在从无人机拍摄的单个图像中检测预定义类别的对象(例如,汽车和行人);
任务 2:视频中的目标检测。该任务与任务 1 相似,不同之处在于需要从视频中检测对象;
任务 3:单目标跟踪挑战。任务旨在估计后续视频帧中第一个帧中指示的目标状态;
任务 4:多目标跟踪挑战。该任务旨在恢复每个视频帧中对象的轨迹。
数据集下载链接:https://github.com/VisDrone/VisDrone-Dataset
与常规检测数据集不同的是,每张图片包含上百个待检测物体,数据集总共含有 260 万个标注框,如果使用占用显存较大的模型,可能会出现资源不够的情况。同时面对一些重叠的结果时,我们需要选择合适的阈值去过滤出最好的结果。
因为数据集是由无人机拍摄而来,行人和远景的物体的标注框就非常小,这对模型产生 anchor 的能力形成了一定的挑战,高分辨率的空间信息和高质量的 proposal 在本次赛题中就显得尤为重要。
常用的数据集如:COCO 数据集、OBJ365 都是广泛应用的数据集,所以大家经常用它们的预训练来 fine-tune 其他数据集。而这一次的数据集由于拍摄角度问题,预训练所带来的效果不如预期。
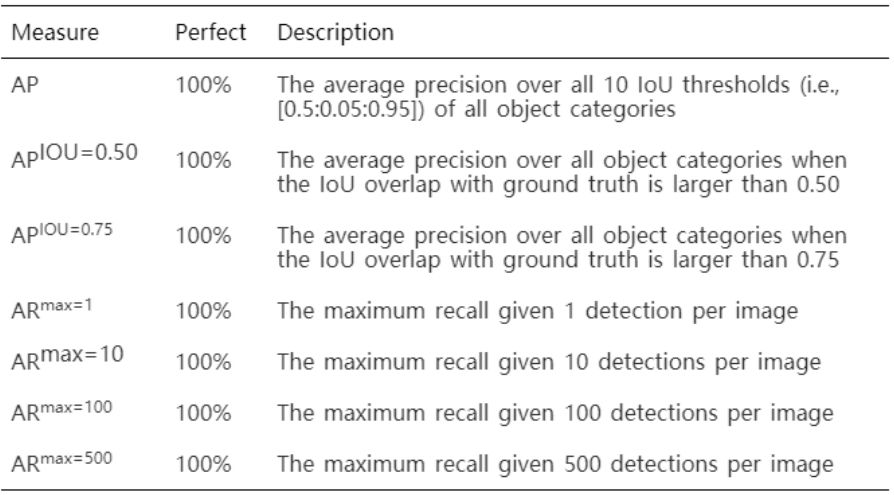
为了进行综合评估并反映每个对象类别的性能,本次测评采用类似于 MS COCO 数据集的评估方案,使用 AP, APIOU=0.50, APIOU=0.75, ARmax=1, ARmax=10, ARmax=100, 和 ARmax=500,且这些指标是基于 10 个对象类别计算出来的。
![]()
最终,来自电子科技大学的李宏亮团队获得了 Task1「图像中的目标检测」的冠军;中科院信息工程研究所的葛仕明团队获得了 Task3「单目标跟踪挑战」的冠军;来自深兰科技北京 AI 研发中心的 DeepBlueAI 团队获得了 Task2「视频目标检测」和 Task4「多目标追踪」两项冠军。以下是 DeepBlueAI 团队分享的解决方案
![]()
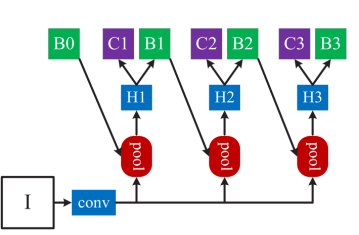
检测器:Cascade RCNN + DCN + FPN + DH
团队基于现有数据集,并结合以往检测经验,打造了一个强大的目标检测器。
![]()
用低 IoU 阈值进⾏训练会导致效果不好,因为会产⽣很多噪声框;所以我们希望阈值尽量⾼,但 IoU 阀值设过⾼时,训练出的 detector 效果却会呈现下降趋势。Cascade RCNN 将多个阈值越来越⾼的 detector 串联,得到了更好的效果。
⾸先,在每次 detector 计算后,IoU⾼的 bbox 的分布都会提升,使得下⼀阶段更⾼阈值下正样本的数量得到保证;其次,每经过⼀次 detector 计算,bbox 都会变得更准确,更⾼的阈值可保证下⼀次回归效果更好。
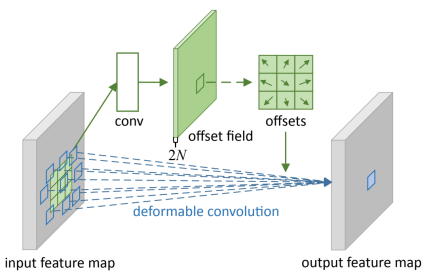
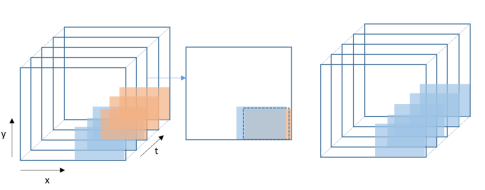
2. DCN(Deformable Convolution Network)
![]()
deformable convolution network 提出了「deformable convolution」和「deformable RoI pooling」两种网络结构单元,deformable convolution 和 deformable RoI pooling 都是基于通过学习一个额外的偏移(offset),使卷积核对输入 feature map 的采样产生偏移,集中于感兴趣的目标区域, 从而产生更好的感受野。
![]()
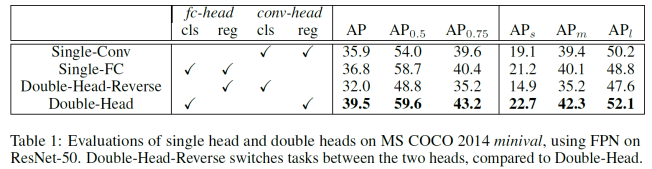
![]()
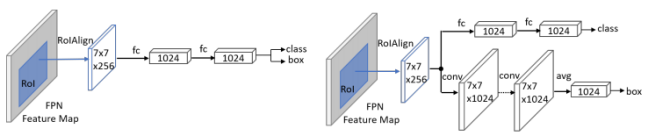
通过对比实验可发现:用 fc-head 去做分类,同时用 conv-head 去做回归,可以实现最好的效果。因为分类更多的需要语义信息,而回归坐标框需要更多的空间信息,这种方法采用「分而治之」的思想,针对不同的需求设计 head 结构,当然这种方法增加了计算量,在平衡速度和准确率的情况下,最后选择了 3 残差、2non-local,共 5 个模块。
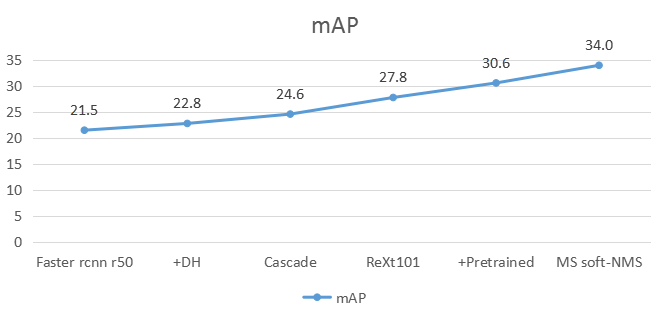
1. 我们将 Faster rcnn + DCN + FPN 作为我们的 baseline,因为这两个模块总是能在不同的数据集上起到效果。
2. 将原有 head 改为 Double head
4. 将 ResNeXt101 作为 backbone
5. 使用 cascade rcnn COCO-Pretrained weight
![]()
![]()
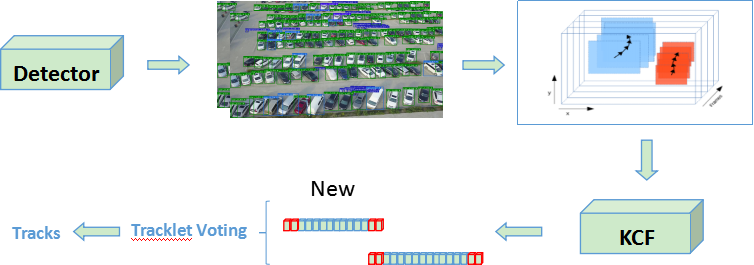
跟踪算法:IOU tracker + KCF + tracklet vote
根据赛题描述与数据集分析结果,我们可以知道,如果图中有大量目标且大部分都为小目标,在这种情况下仍然使用 reid 相关跟踪算法的话,不仅最终效果不理想,而且也会在匹配排序的过程中耗费大量的资源,所以我们最终决定使用 iou-tracker。
使用不需要图片信息,仅根据检测结果的相邻帧的 iou 进行计算;
iou-tracker 对检测结果有着较高的要求,我们对自己的检测结果有信心;
运行速度极快,不涉及到神经网络,节省时间和 GPU 资源。
![]()
难点:使用 iou tracker 之后,还是会不可避免地遇到断帧 (一条轨迹无法全部预测,被预测为多个子段) 的问题,这样会大大降低最后的得分,所以我们使用 KCF 对现有结果进行一个更新。
KCF 的原理极为复杂,但 KCF 作用就是根据现有结果使用传统算法,去预测之后几帧的结果,这相当于对一些丢失的信息进行补充的操作。
得到新的轨迹之后再使用 IOU 相关投票融合方法,将更新后的结果融合,融合过程如图所示:
![]()
KCF 更新轨迹之后,正常情况下轨迹之间就会有相互重叠的地方,我们使用一个基于 IOU 的投票方法,如果轨迹之间重叠部分的投票结果大于某个阈值,就将这两个轨迹进行融合。
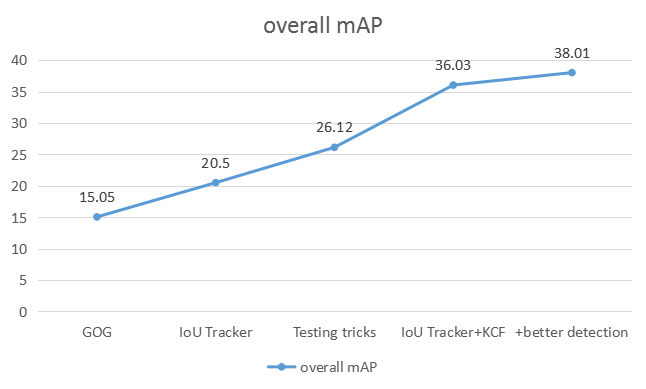
1. 我们将任务二中的检测结果当做输入,先使用 GOG 方法作为我们的 baseline
![]()
在检测方面,在网络结构上有一些其他可以使用的模块,例如「PAFPN--FPN 的改进版」,可以在特征提取之后更好地处理各层级之间的信息;以及「GCnet」,一种结合了两个不错的 attention 机制所得到的网络,等等。
由于时间的限制,在更新原有跟踪结果的时候,我们使用的是比较传统的 KCF 算法,这类算法比较节省时间,但同时也有很大的局限性。如果有机会,以后想尝试一些更好的、基于神经网络的方法进行更新。
[1]Lin T Y , Dollár, Piotr, Girshick R , et al. Feature Pyramid Networks for Object Detection[J]. 2016.
[2]Dai J, Qi H, Xiong Y, et al. Deformable Convolutional Networks[J]. 2017.
[3]Cai Z , Vasconcelos N . Cascade R-CNN: Delving into High Quality Object Detection[J]. 2017.
[4]Xie S , Girshick R , Dollar P , et al. Aggregated Residual Transformations for Deep Neural Networks[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society, 2017.
[5]Bochinski E , Eiselein V , Sikora T . High-Speed tracking-by-detection without using image information[C]// 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). IEEE, 2017.
[6]Henriques J F , Caseiro R , Martins P , et al. High-Speed Tracking with Kernelized Correlation Filters[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(3):583-596.
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、检测分割识别、三维视觉、医学影像、GAN、自动驾驶、计算摄影、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
![]()
投稿欢迎联系:simiter@126.com
欢迎加入从零开始学习SLAM知识星球,详见:如何从零开始系统化学习视觉SLAM?
推荐阅读
CV+医疗领域实践项目!适合入门的图像分类领域新赛事
最新AI干货,我在看 ![]()