【推荐】GAN架构入门综述(资源汇总)
转自:爱可可-爱生活
Introduction
How do you teach a machine to draw a human face if it has never seen one? A computer can store petabytes of photos, but it has no idea what gives a bunch of pixels a meaning related to someone’s appearance.
For many years this problem has been tackled by various generative models. They used different assumptions, often too strong to be practical, to model the underlying distribution of the data.
The results were suboptimal for most of the tasks we have now. Text generated with Hidden Markov Models was very dull and predictable, images from Variational Autoencoders were blurry and, despite the name, lacked variety. All those shortcomings called for an entirely new approach, and recently such method was invented.
In this article, we aim to give a comprehensive introduction to general ideas behind Generative Adversarial Networks (GANs), show you the main architectures that would be good starting points and provide you with an armory of tricks that would significantly improve your results.
Towards the invention of GANs
The basic idea of a generative model is to take a collection of training examples and form a representation of their probability distribution. And the usual method for it was to infer a probability density function directly.
When I was studying generative models the first time I couldn't help but wonder - why bother with them when we have so many real life training examples already? The answer was quite compelling, here are just a few of possible applications that call for a good generative model:
Simulate possible outcomes of an experiment, cutting costs and speeding up the research.
Action planning using predicted future states - imagine a GAN that "knows" the road situation the next moment.
Generating missing data and labels - we often lack the clean data in the right format, and it causes overfitting.
High-quality speech generation
Automated quality improvement for photos (Image Super-Resolution)
In 2014, Ian Goodfellow and his colleagues from University of Montreal introduced Generative Adversarial Networks (GANs). It was a novel method of learning an underlying distribution of the data that allowed generating artificial objects that looked strikingly similar to those from the real life.
The idea behind the GANs is very straightforward. Two networks -- a Generator and a Discriminator play a game against each other. The objective of the Generator is to produce an object, say, a picture of a person, that would look like a real one. The goal of the Discriminator is to be able to tell the difference between generated and real images.
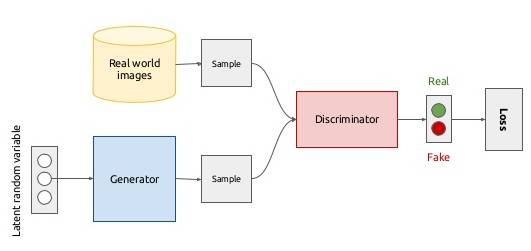
This illustration gives a rough overview of the Generative Adversarial Network. For the moment it's most important to understand that the GAN is rather a way to make two networks work together - and both Generator and Discriminator have their own architecture. To better understand where this idea came from we will need to recall some basic algebra and ask ourselves - how can we fool a neural network that classifies images better than most humans?
Adversarial examples
Before we get to describing GANs in details, let’s take a look at a similar topic. Given a trained classifier, can we generate a sample that would fool the network? And if we do, how would it look like?
It turns out, we can.
Even more - for virtually any given image classifier it’s possible to morph an image into another, which would be misclassified with high confidence while being visually indistinguishable from the original! Such process is called an adversarial attack, and the simplicity of the generating method explains quite a lot about GANs.
An adversarial example in an example carefully computed with the purpose to be misclassified. Here is an illustration of this process. The panda on the left in indistinguishable from the one on the right - and yet it's classified as a gibbon.
链接:
https://sigmoidal.io/beginners-review-of-gan-architectures/
原文链接:
https://m.weibo.cn/3193816967/4146423228075680




