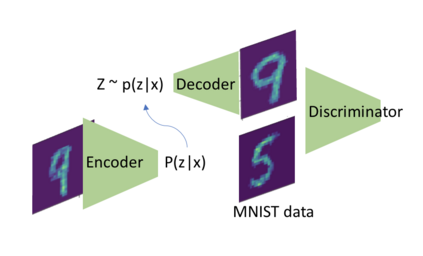
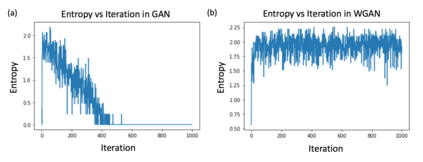
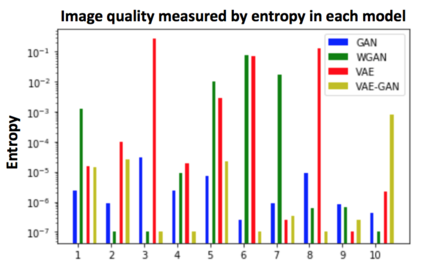
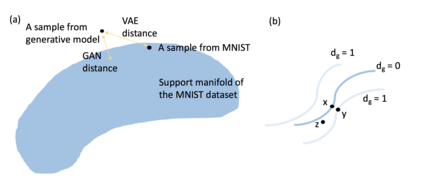
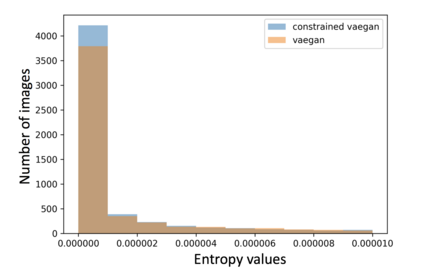
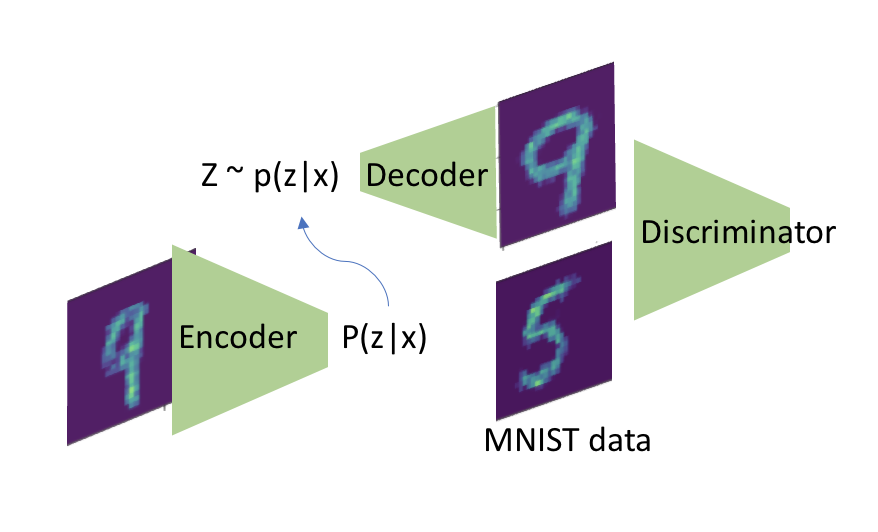
Both generative adversarial network models and variational autoencoders have been widely used to approximate probability distributions of datasets. Although they both use parametrized distributions to approximate the underlying data distribution, whose exact inference is intractable, their behaviors are very different. In this report, we summarize our experiment results that compare these two categories of models in terms of fidelity and mode collapse. We provide a hypothesis to explain their different behaviors and propose a new model based on this hypothesis. We further tested our proposed model on MNIST dataset and CelebA dataset.
翻译:基因对抗网络模型和变异自动编码模型都被广泛用来估计数据集的概率分布。虽然它们都使用对称分布法来估计基础数据分布,而其确切的推论是棘手的,但它们的行为非常不同。在本报告中,我们总结了将这两类模型在忠诚和模式崩溃方面进行比较的实验结果。我们提供了一种假设来解释它们的不同行为并根据这一假设提出一个新的模型。我们进一步测试了我们提议的MNIST数据集模型和CelibA数据集模型。