【推荐】全卷积语义分割综述
转自:爱可可-爱生活
Semantic Segmentation
Introduction
Semantic Segmentation of an image is to assign each pixel in the input image a semantic class in order to get a pixel-wise dense classification. While semantic segmentation / scene parsing has been a part of the computer vision community since 2007, but much like other areas in computer vision, major breakthrough came when fully convolutional neural networks were first used by 2014 Long et. al. to perform end-to-end segmentation of natural images.

Figure : Example of semantic segmentation (Left) generated by FCN-8s ( trained using pytorch-semseg repository) overlayed on the input image (Right)
The FCN-8s architecture put forth achieved a 20% relative improvement to 62.2% mean IU on Pascal VOC 2012 dataset. This architecture was in my opinion a baseline for semantic segmentation on top of which several newer and better architectures were developed.
Fully Convolutional Networks (FCNs) are being used for semantic segmentation of natural images, for multi-modal medical image analysis and multispectral satellite image segmentation. Very similar to deep classification networks like AlexNet, VGG, ResNet etc. there is also a large variety of deep architectures that perform semantic segmentation.
I summarize networks like FCN, SegNet, U-Net, FC-Densenet E-Net & Link-Net, RefineNet, PSPNet, Mask-RCNN, and some semi-supervised approaches like DecoupledNet and GAN-SShere and provide reference PyTorch and Keras (in progress) implementations for a number of them. In the last part of the post I summarize some popular datasets and visualize a few results with the trained networks.
Network Architectures
A general semantic segmentation architecture can be broadly thought of as an encoder network followed by a decoder network. The encoder is usually is a pre-trained classification network like VGG/ResNet followed by a decoder network. The decoder network/mechanism is mostly where these architectures differ. The task of the decoder is to semantically project the discriminative features (lower resolution) learnt by the encoder onto the pixel space (higher resolution) to get a dense classification.
Unlike classification where the end result of the very deep network ( i.e. the class presence probability) is the only important thing, semantic segmentation not only requires discrimination at pixel level but also a mechanism to project the discriminative features learnt at different stages of the encoder onto the pixel space. Different architectures employ different mechanisms (skip connections, pyramid pooling etc) as a part of the decoding mechanism.
A number of above architectures and loaders for datasets is available in PyTorch at:
PyTorch: meetshah1995/pytorch-semseg
A more formal summarization of semantic segmentation ( including recurrent style networks ) can also be found here
Fully Convolution Networks (FCNs)
| CVPR 2015 | Fully Convolutional Networks for Semantic Segmentation | Arxiv |
We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a novel architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional network achieves state-of-the-art segmentation of PASCAL VOC (20% relative improvement to 62.2% mean IU on 2012), NYUDv2, and SIFT Flow, while inference takes one third of a second for a typical image.
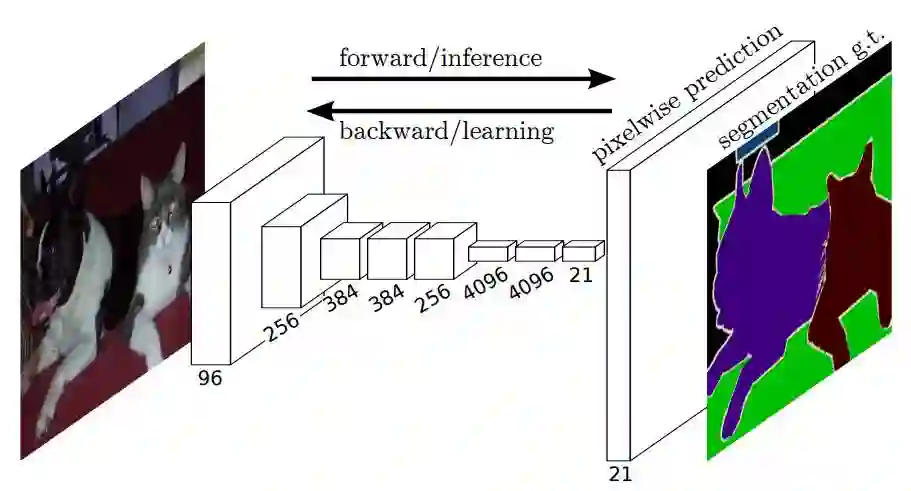
Figure : The FCN end-to-end dense prediction pipeline.
A few key features of networks of this type are:
The features are merged from different stages in the encoder which vary in coarseness of semantic information.
The upsampling of learned low resolution semantic feature maps is done using deconvolutions which are initialized with billinear interpolation filters.
Excellent example for knowledge transfer from modern classifier networks like VGG16, Alexnet to perform semantic segmentation
链接:
https://meetshah1995.github.io/semantic-segmentation/deep-learning/pytorch/visdom/2017/06/01/semantic-segmentation-over-the-years.html
原文链接:
https://m.weibo.cn/3193816967/4146423228075680

