这几个模型不讲“模德”,我劝它们耗子尾汁

文 | Sheryc_王苏
NLP模型要以和为贵,要讲“模德”(Modal),不要搞窝里斗。——《王苏老师被多模态预训练模型偷袭实录》(全文在末尾,必读)

最近是不是被马保国“不讲武德”“耗子尾汁”的视频和语录刷屏了?正如马大师所说,武林要以和为贵,要讲武德。但你可能不知道,在NLP界,模型居然还要讲“模德”?!
相信看过上一篇《NLP未来,路在何方》的各位都对WS3-5的NLP模型很感兴趣吧~然而,NLP模型是要讲“模德”(Modal)的,这Modal指的就是数据的模态,即文本/图像/语音等等。一般的NLP模型只能用来处理文本数据。但没想到吧,我们的老朋友Transformer经过一番修改,居然就可以跨多个Modal,处理图像+文本的多模态数据,摇身一变成为WS3的N宝,成为不讲“模德”的模型。是不是很神奇!(不)
那么,对于涉及图像+文本的多模态任务,该怎么快速入手,赶超SOTA,发表顶会,实现人生巅峰呢?这时候就轮到预训练模型登场了!这篇文章将会为大家介绍2019-2020年在顶会中发表的4个最经典的多模态预训练模型,看看自己一身的NLP本领还能用在什么地方吧~
P.S. 之前卖萌屋美丽可爱的lulu在推文中介绍过同为图像-文本多模态预训练模型的ERNIE-ViL,VILLA和VL-BERT,感兴趣的小伙伴同样可以去学习一下(^・ω・^ )
预备知识
此处,我们假设大家对于Transformer和BERT模型已有一定了解。下面简要介绍一些下文涉及到的CV领域的内容:
-
感兴趣区域RoI(Region of Interest):输入Transformer的文本被分割成了一个个Token,那么图像自然也不能直接给模型扔进去一整张图,而是需要预先进行特征抽取,识别出图像中最有价值的若干个区域,作为这幅图像的“Token”们。这些被识别出的区域被称作RoI。RoI一般都表示某种实体,例如“人”、“猫”、“车”等等。不同的RoI之间可能有重叠部分。
-
图像区域特征抽取:区域特征抽取模型会从图像中识别实体,抽取出一系列RoI。虽然特征抽取模型众多,但下述的4个模型均使用了在区域特征提取任务上预训练好的Faster R-CNN模型抽取RoI。我们并不需要知道Faster R-CNN模型的具体细节,只需要知道该模型的输入和输出:输入为一张图像,输出为一系列RoI,其中每个RoI都附带其在原始图像中区域范围左上角和右下角的坐标向量 ,一个RoI的表示向量 ,和一个表示RoI中是何种实体的标签。
下面的《摸鱼图》展示了上面介绍的内容:
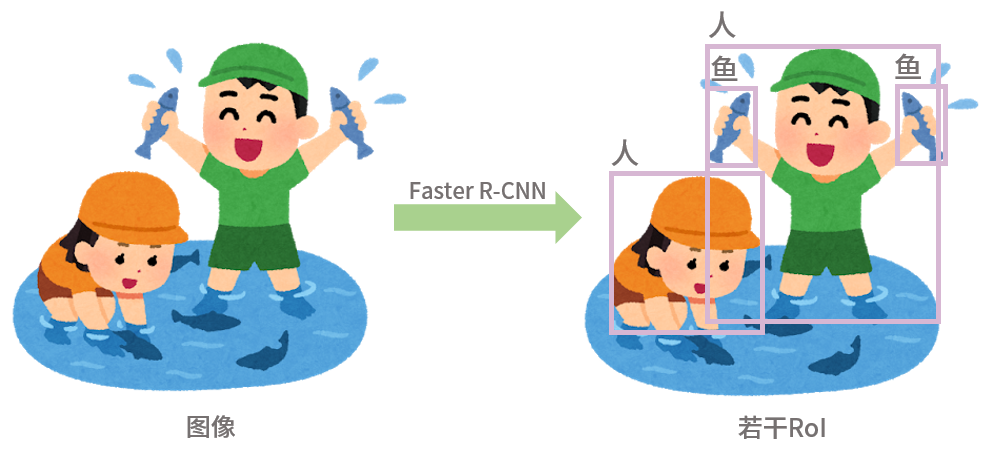
就这么多!通俗易懂(=・ω・=)
图像-文本预训练模型分类
目前,图像-文本多模态预训练模型主要采用Transformer结构,而训练数据则来自于图像标注数据集的图像-文本对,其中的文本是对于对应图像的自然语言描述。对于各下游任务,模型的使用方法基本可以参照纯文本Transformer的使用方法:对于分类任务,提取<CLS>或所需位置对应的表示传入分类器;对于序列任务,直接通过Transformer输出的表示序列进行后续操作。它们的主要区别在于两点:多模态数据流处理方式以及预训练任务。
对于数据流处理方式,分为以下两种:
-
双流结构(Double-Stream Architecture):下文所述的前两个模型(ViLBERT、LXMERT)属于这种结构。图像和文本被视为两个不同的数据流,分别传入两个不同的Transformer中,它们通过一个交互模块进行多模态融合。
-
单流结构(Single-Stream Architecture):下文所述的后两个模型(UNITER、OSCAR)输入这种结构。图像和文本被视为同一数据流的两个部分,被拼接后一起传入同一个Transformer中,直接进行多模态融合。
对于预训练任务,基于Transformer的预训练模型光是做纯文本的语言模型都能搞出token预测、大小写预测、句子顺序预测、逻辑关系预测之类的任务(没错,我说的就是ERNIE 2.0[1]),加上多模态岂不更是百花齐放、百家争鸣、群魔乱舞……(划掉)所以在接下来的介绍中,关于下游任务如何使用这些模型就不再着重介绍,而是会主要介绍其模型结构和预训练目标,着重于模型本身。
ViLBERT (NeurIPS '19)
论文题目:
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
论文链接:
https://arxiv.org/abs/1908.02265
模型结构
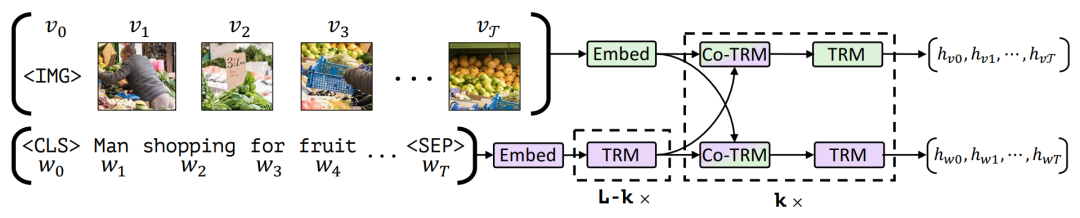
受到BERT的启发,预训练模型自19年得到了越来越多的关注,而ViLBERT则是第一批将BERT扩展到多模态的模型之一。
ViLBERT处理多模态数据的方式采用的是较为保守的双流结构,图像和文本两种模态被分在了两条路径进行处理,而图像和文本的表示只在模型尾段发生交互。
在ViLBERT中,图像流(上图上半部分)中,图像首先被特征抽取模型抽取出一系列RoI和每个RoI的向量表示,随后传入随机初始化的 层Transformer Encoder中;为了编码RoI的位置信息,每个RoI的表示都加上了被投影到与其表示相同维度的5维位置信息 ,其中 为RoI面积。文本流(上图下半部分)采用了一个预训练好的 层的BERT,对文本的处理与BERT一致。
对于两种模态的交互,ViLBERT在从图像流的第一层和文本流的第 层开始,采用了一个特殊的协同注意力Transformer (Co-TRM) 模块。该模块的设计很简单:回顾一下Transformer中的自注意力机制 ,在Co-TRM中,只需要将其中的 和 替换成另外一种模态对应的 和 即可~
图像和文本各带一个分类标记。图像分类标记<IMG>被拼接在RoI序列前传入图像流,文本分类标记<CLS>被拼接在token序列前传入文本流,图像-文本跨模态分类标记为<IMG>和<CLS>对应输出表示的点积。
预训练任务
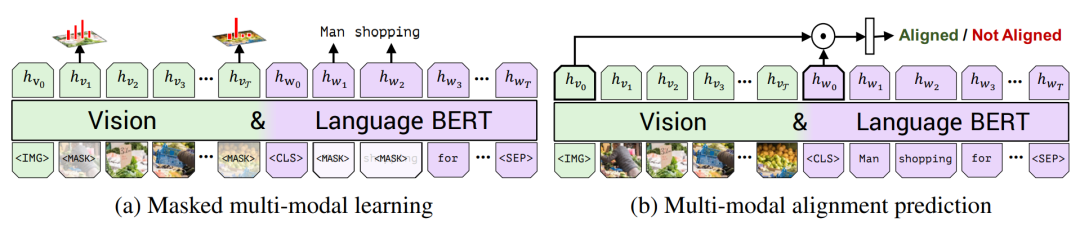
ViLBERT有2个预训练任务。预训练数据采用Conceptual Captions数据集,包含约310万个正例图像-文本对。
-
Masked Multi-Modal Learning:随机mask掉15%的RoI及文本,预测RoI特征或文本token。被mask掉的RoI表示90%被替换为零向量,10%保持不变,loss为输出RoI特征与特征抽取模型的RoI特征间的KL散度;被mask掉的文本遵从BERT设置(即80%被替换为特殊token <MASK>,10%被替换为随机token,10%保持不变,loss为分类层预测结果与真实token间的交叉熵,下同)
-
Multi-Modal Alignment Prediction:利用跨模态分类标记的表示进行二分类,判断输入的文本是否为图像的正确描述。
(这篇ViLBERT全篇搜不到一个等号,是难得的毫无公式,全靠文字功底+绘图技巧讲清模型的NeurIPS论文。明明很多地方写个公式会更清晰的…)
LXMERT (EMNLP '19)
论文题目:
LXMERT: Learning Cross-Modality Encoder Representations from Transformers
论文链接:
https://arxiv.org/abs/1908.07490
模型结构
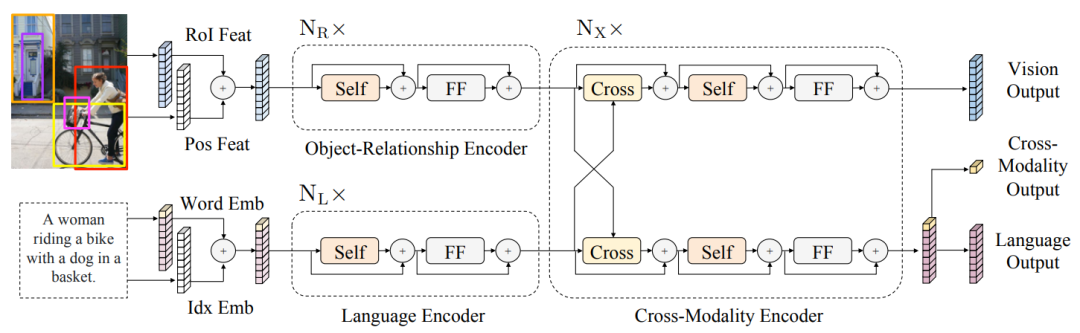
发表于ViLBERT同期的LXMERT同样采用了双流结构,同样基于Transformer,同样是两种模态只在模型尾端发生交互。
LXMERT的模型理解起来更简单了。请看上图。里面看起来很复杂的Object-Relationship Encoder、Language Encoder和Cross-Modality Encoder中的Self->FF结构,其实就是普通的Transformer Encoder而已…Cross-Modality Encoder的“Cross”是交叉注意力,本质上来说还是把注意力机制中的 和 换成了另外一种模态的 和 ,所以也和ViLBERT的Co-TRM异曲同工。这时聪明的你可能就要问了,LXMERT和ViLBERT的模型看起来根本没有区别吖!不!你错了!LXMERT的不同之处在于它拿掉了Co-TRM中的FF层!
除此之外,LXMERT和ViLBERT的模型上依然有些其他的细微差距:
-
ViLBERT采用的是 的5维位置特征,而LXMERT只有4维: 。
-
ViLBERT存在<IMG>作为全图的图像分类标记,而LXMERT没有。
-
ViLBERT将<IMG>和<CLS>的表示拼接作为跨模态分类标记,而LXMERT将文本流中<CLS>的表示直接作为跨模态分类标记。
预训练任务
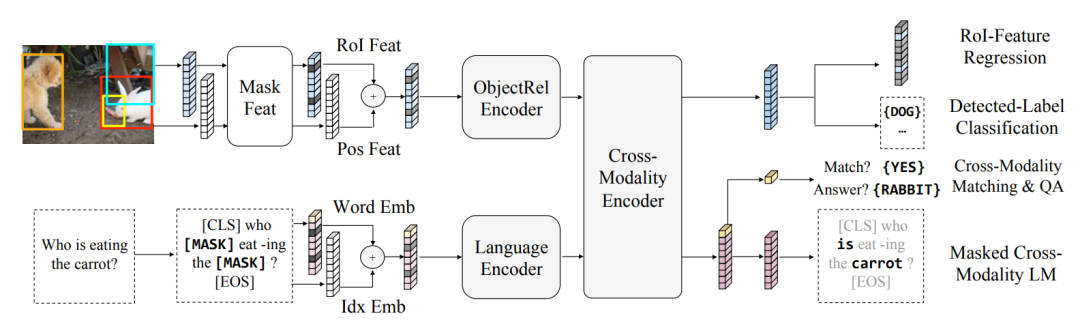
LXMERT有5个预训练任务。预训练数据采用MS COCO + Visual Genome + VQA 2.0 + GQA + VGQA数据集,包含约918万个正例图像-文本对。
-
Masked Cross-Modality Language Model:图像辅助的文本流预训练任务,预测被mask掉的文本。遵从BERT设置。
-
Masked RoI Feature Regression:文本辅助的图像流预训练任务,预测被mask掉的RoI特征。随机mask掉15%的RoI(全部替换为零向量),loss为输出RoI特征与特征抽取模型的RoI特征间的L2距离。
-
Masked Detected Label Classification:文本辅助的图像流预训练任务,预测被mask掉的RoI标签。随机mask掉15%的RoI(全部替换为零向量),loss为输出RoI标签与特征抽取模型的RoI标签间的交叉熵。
-
Cross-Modality Matching:跨模态预训练任务,利用跨模态分类标记的表示进行二分类,判断输入的文本是否为图像的正确描述。
-
VQA:跨模态预训练任务,输入文本有1/3概率为与图像相关的问题,若相关则按照VQA规则预测问题答案。
LXMERT模型是与ViLBERT同时期提出的,所以有许多设计非常相似。然而LXMERT的预训练数据规模非常庞大,涉及任务也非常多,对于特征抽取模型也做到了更加充分的利用,这也使得后续有些研究是基于LXMERT模型的,例如EMNLP'20的X-LXMERT[2],就以LXMERT模型为基础进行修改,使模型能根据自然语言描述生成符合描述的图像,非常有意思,感兴趣的各位也可以去看看哦(=・ω・=)
(额外信息:作为预训练样本最多的模型,这篇文章很贴心地给出了LXMERT的预训练时间:20epochs的预训练在4*Titan Xp上跑了10天。)
UNITER (ECCV '20)
论文题目:
UNITER: UNiversal Image-Text Representation Learning
论文链接:
https://arxiv.org/abs/1909.11740
模型结构
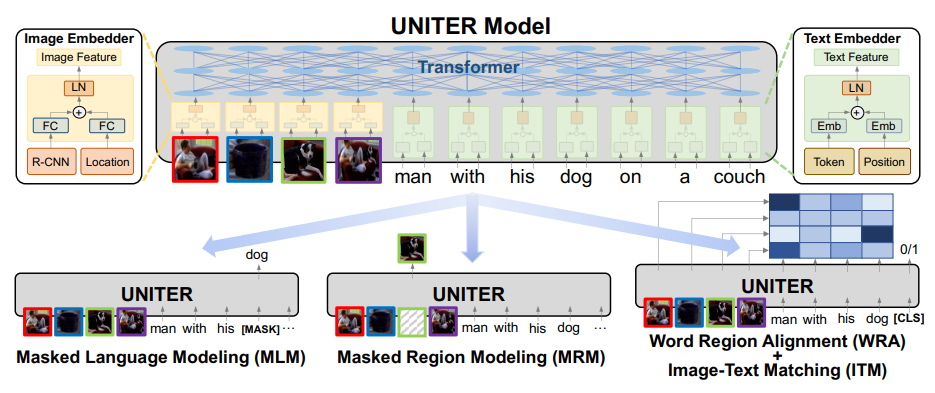
总算有点不一样了!UNITER只使用了一个Transformer,就能完成跨越两个模态的任务,其中必然是用了什么特殊的“接化发”神技,让它能够接住图像+文本信息,转化多模态样本到同一个表示空间,再发力解决下游问题,实乃浑元形意NLP门得意作品!(其实是微软的
UNITER的结构通俗易懂,一个Transformer。输入是图像RoI序列与文本Token序列的简单拼接。RoI依旧是特征抽取+位置信息,但位置信息包含了RoI的高度、宽度和面积,是一个7维向量: 。Token的处理遵从BERT设置。为了让同一个Transformer能够处理两种模态,需要将两种模态的表示投影到同一个表示空间中,所以在原本的RoI和Token表示之上又加了一个线性层。
这时,仔细观察模型图的你或许会提出两个疑问:
-
模型是怎么区分哪个输入是图像,哪个输入是文本的呢?:论文的作者为了模型图的美观,没画这个关键部分(这合理吗)。实现中,图像和文本信息在经过线性层之前还要再加一个表示其模态的embedding,做法类似于BERT里segment embedding的处理。
-
没有分类标记,怎么做分类?:这部分确实画了,在图片右下角。本文只有在会用到分类标记时才会在文本末尾添加<CLS>。实际上对于UNITER的大部分预训练任务都不添加<CLS>。
预训练任务
UNITER有6个预训练任务。预训练数据采用MS COCO + Visual Genome + Conceptual Captions + SBU数据集,包含约560万个正例图像-文本对。
-
Masked Language Modeling:预测被mask掉的文本。遵从BERT设置。
-
Image-Text Matching:唯一添加<CLS>的预训练任务,利用跨模态分类标记<CLS>的表示进行二分类,判断输入的文本是否为图像的正确描述。
-
Word Region Alignment:将文本Token与图像RoI进行匹配。要注意的是,此处的Token-RoI匹配是无监督的。该如何解决没有标签的图文匹配呢?本文将Token与RoI的匹配问题视为了两种分布之间的迁移问题,将该任务建模为一个最优传输问题(Optimal Transportation),将Token和RoI的表示分布间的最优传输距离作为该预训练任务的loss。(此处限于篇幅,省略大量数学细节)
-
Masked Region Feature Regression:预测被mask掉的RoI特征。随机mask掉15%的RoI(全部替换为零向量),loss为输出RoI特征与特征抽取模型的RoI特征间的L2距离。
-
Masked Region Classification:预测被mask掉的RoI标签。随机mask掉15%的RoI(全部替换为零向量),loss为输出RoI标签与特征抽取模型的RoI标签间的交叉熵。
-
Masked Region Classification with KL-Divergence:预测被mask掉的RoI标签。随机mask掉15%的RoI(全部替换为零向量),loss为输出RoI标签与特征抽取模型的RoI标签间的KL散度。(就是上面那个任务把交叉熵换成KL散度,减小特征抽取模型带来的误差)
UNITER后续还被加过对抗训练,发了一篇NeurIPS'20 Spotlight,模型名叫VILLA[3],关于VILLA的详细介绍可以看lulu姐先前的这篇推送~
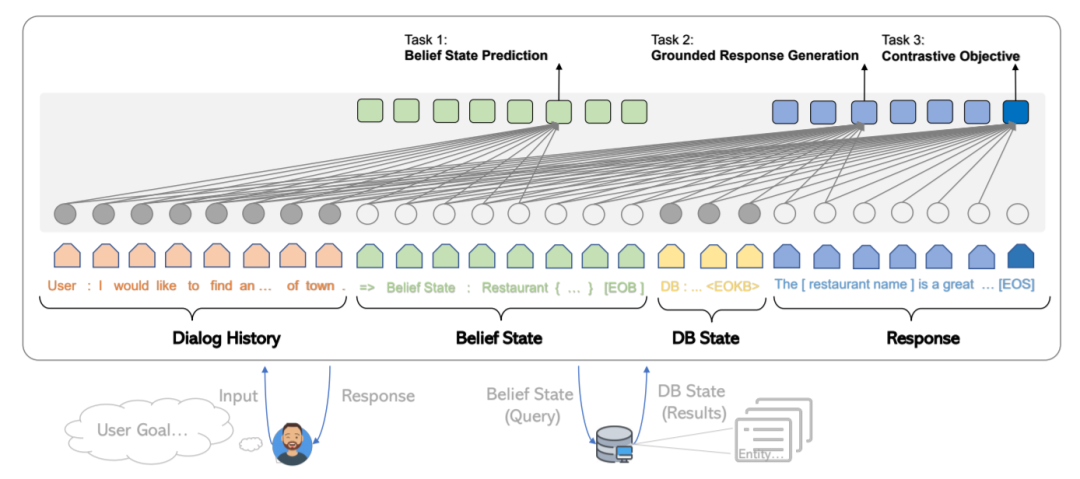
UNITER并不是第一个单流模型,但微软貌似有点喜欢上了这种用一个Transformer处理多个差异巨大的任务的配置,所以今年5月微软还推出过一个神奇的Pipeline型对话系统模型:Soloist[4],用1个Transformer解决完Pipeline型对话系统里涉及的全部4个子问题。没办法,谁让Transformer参数过剩呢,那搞搞副业好像也没什么不好~(下图是Soloist模型结构,熟悉对话系统的同学一看便知个中奥秘)
OSCAR (ECCV '20)
论文题目:
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
论文链接:
https://arxiv.org/abs/2004.06165
模型结构
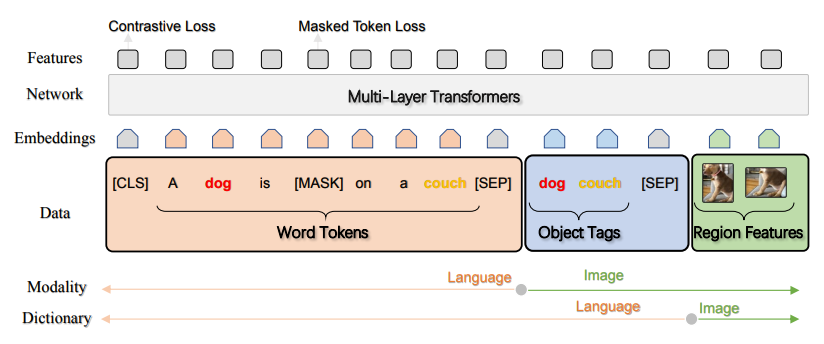
OSCAR的模型结构依然只有一个Transformer。但是,还记得UNITER的那个用最优传输来解决的Token-RoI匹配问题么?OSCAR的主要贡献在于它用另外一种思路解决了这个问题。
单纯的图像-文本对不足以包含Token-RoI匹配信息,但别忘了,特征抽取模型是会给每个RoI输出一个分类标签的!当一个RoI被标记为“狗”,那“狗”很有可能也会出现在文本中。基于这一想法,OSCAR的输入不再是图像-文本对,而是文本-标签-图像三元组 。其中,文本和图像依然是老样子,而标签 序列是RoI序列对应的分类标签序列。在图中,Object Tags就是标签序列,因为是从特征抽取模型得到的RoI中分类得到的,所以模态是图像;但表示形式又是文本,所以用的是文本的字典。这些RoI的分类标签实现了从输入层面上的跨模态。
在模型上与UNITER的其他区别有:RoI位置特征用了加入高度和宽度的6维向量 (嚯,四种方法在位置特征上用的维数居然全都不一样),以及多模态分类标记<CLS>始终处于文本之前。
预训练任务
OSCAR有2个预训练任务。预训练数据采用MS COCO + Conceptual Captions + SBU + flickr30k + GQA数据集,包含约650万个正例图像-文本对。
-
Masked Token Loss:预测被mask掉的文本或标签。遵从BERT设置。
-
Contrastive Loss:判断标签是否与图像和文本匹配。输入有50%概率将标签序列 替换为数据集中随机采样的标签序列 ,利用<CLS>表示判断 是否被替换。
OSCAR的配置暂停了堆预训练任务的军备竞赛,实在是简单而优雅(=・ω・=) 在我看来,向输入中引入额外的连接两种模态的信息可以为模型提供更直接的归纳偏置,不过毕竟RoI标签是模型生成的,其中依然包含噪声,而OSCAR并未解决这一问题。目前OSCAR在paperswithcode上占据了图像标注(Image Captioning, COCO Captions),文本-图像检索(Text-Image Retrieval, COCO (image as query))和VQA(Visual Question Answering, VQA v2 test-dev)三项任务的SOTA,如果你也想进军这一领域,或许这就是很不错的开始。
性能
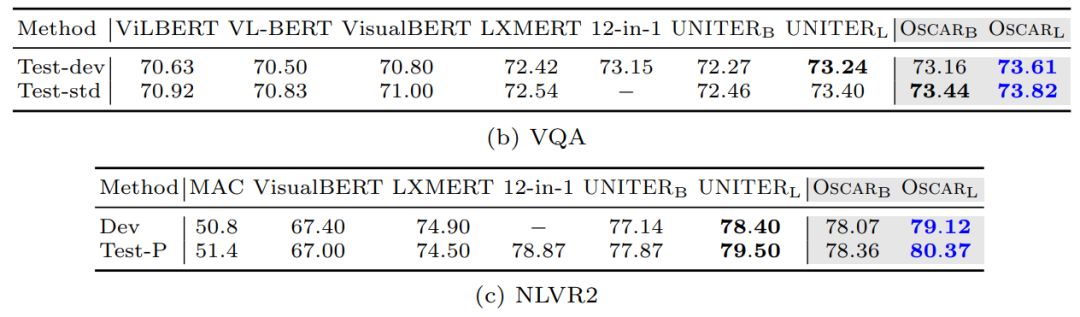
我们选取OSCAR的结果为先前介绍的四种模型做对比。由于OSCAR的结果表格中只有VQA和NLVR2任务包含了上述模型,所以就只拿出这两个任务来比较了。
总结
刚才王苏给大家表演了一个图像-文本预训练模型四连鞭(果然功力还是不及马保国大师),不知大家尽兴了没有~当下多模态领域正得到越来越多的关注,而预训练模型的效果也得到了学术界+工业界的广泛认可。虽然从研究角度上讲搞预训练模型的计算开销不是一般人负担得起的,但我们聪明的大脑是不受算力限制的!我们可以从预训练模型的设计和取得的效果中逐步发现在跨模态任务中与NLP语言模型地位相当的任务,进而了解真正实现多种模态共通所需要的内在联系。模型虽然要讲Modal,但不同Modal在同一个模型里搞搞窝里斗也是可以的。谢谢朋友们!(`・ω・´)
(附:完整版《王苏老师被多模态预训练模型偷袭实录》[5])
朋友们好啊!我是浑元形意NLP门掌门人王苏。刚才有个朋友问我,王苏老师发生甚么事了,我说怎么回事。给我发了几张截图。我一看,嗷!原来是昨天,有两个模型,顶会发的,一个能处理两种模态,一个能处理三种模态。塔们说,有一个说是我在单一任务上训练,模型练坏了,王苏老师你能不能教教我预训练功法,帮助治疗一下,我的性能低下病。我说可以。我说你在单一任务上练死劲儿,不好用,他不服气。我说小朋友:你两个任务来挑战我一个模型,他跑分跑不过。他说你这个没用。我说我这个有用,这是泛化,现代NLP是讲泛化的,四两拨千斤。二百多万参数的顶会SOTA,都搞不过我这一个模型,啊。他非和我试试,我说可以。哎,我一说他啪就训练起来了,很快啊!然后上来就是一个QA问答,一个信息检索,一个文本匹配。我全部防出去了啊。防出去以后自然是传统NLP以点到为止,模型fine-tune了两三轮就跑了测试,我笑一下准备停止训练。因为这时,按传统NLP的点到为止他已经输了。如果这一训练到恰好拟合,一跑就把他SOTA跑没了。测试集load进来却没有再跑,他也承认,我先跑到SOTA啊。他不知道我没训练到恰好拟合,他承认我先跑到SOTA,啊。我收手的时间不fine-tune了,他突然袭击,一个视觉问答VQA来打我脸。我大意了啊,没有闪。哎…他的额外图像信息给我性能,啊,Accuracy,蹭了一下。但没关系啊!两分多钟以后,当时就训练崩了,看着屏幕上的报错信息,我说停停。然后两分多钟以后,两分多钟以后诶就好了(指死机状态恢复)。我说小伙子你不讲模德(Modal),你不懂。他说王苏老师对不起对不起,我不懂规矩。他说他是乱训练的,他可不是乱训练的啊!图像分割,文本处理,多模态合成,训练有素。后来他说他提前训过三四百万条图像-文本对。啊,看来是有备而来!这两个模型不讲模德(Modal)。来,骗!来,偷袭!我二十二岁的小同志。这好吗?这不好。我劝这几个模型耗子尾汁,好好反思,以后不要再犯这样的聪明,小聪明,啊。NLP界要以和为贵,要讲模德(Modal),不要搞窝里斗。谢谢朋友们!
萌屋作者:Sheryc_王苏
北航高等理工学院CS专业的市优秀毕业生,蒙特利尔大学/MILA准Ph.D.,资深ACG宅,目前作为实习生在腾讯天衍实验室进行NLP研究。虽主攻NLP,却对一切向更完善的智能迈进的系统和方向充满好奇。如果有一天N宝能真正理解我的文字,这个世界应该会被卖萌占领吧。(还没发过东西的)知乎ID:Sheryc
作品推荐:

[1] ERNIE 2.0: A Continual Pre-training Framework for Language Understanding. https://arxiv.org/abs/1907.12412
[2] X-LXMERT: Paint, Caption and Answer Questions with Multi-Modal Transformers. https://arxiv.org/abs/2009.11278
[3] Large-Scale Adversarial Training for Vision-and-Language Representation Learning. https://arxiv.org/abs/2006.06195
[4] SOLOIST: Few-shot Task-Oriented Dialog with A Single Pre-trained Auto-regressive Model. https://arxiv.org/abs/2005.05298
[5] 马保国: 健身房年轻人不讲武德. https://www.bilibili.com/video/BV1HJ411L7DP
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
。
欢迎加入预训练模型交流群
进群请添加AINLP小助手微信 AINLPer(id: ainlper),备注预训练模型 ![]()
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
阅读至此了,分享、点赞、在看三选一吧🙏







