详细解读谷歌新模型 BERT 为什么嗨翻 AI 圈

大家好,我是为人造的智能操碎了心的智能禅师。
很开心。昨天1024节,公司特许,从00:00到8:00放假。禅师感慨:终于可以有机会知道半夜12点睡觉是什么体验了。
之前人工智能头条的股东粉群里,有人提到 BERT 模型,禅师正准备好好了解一下,怎么就全面超越人类了?怎么就谷歌最强 NLP 模型了?

今天带来的这篇文章,详细的讲解了 BERT 以及和其他模型之间的区别。由深思考人工智能(iDeepWise Artificial Intelligence)投稿。
深思考人工智能是一家专注于类脑人工智能与深度学习核心科技的AI公司,公司核心技术是“多模态深度语义理解技术”,可同时理解文本、视觉图像背后的语义。
全文大约3500字。读完可能需要下面这首歌的时间
👇

了解 BERT
BERT 模型全称 Bidirectional Encoder Representations from Transformer s,是一种新型的语言模型,通过联合调节所有层中的双向 Transformer 来训练预训练深度双向表示。
只需要一个额外的输出层,对预训练 BERT 进行微调,就可以满足各种任务,根本没有必要针对特定任务对模型进行修改。这就是为什么 BERT 模型能做在11项 NLP 任务上取得突破进展的原因。
想深入了解 BERT 模型,首先应该理解预训练的语言模型。
预训练的语言模型,对众多自然语言处理问题起到了重要作用。比如 SQuAD 问答任务、命名实体识别,以及情感识别。
目前将预训练的语言模型应用到 NLP 任务主要有两种策略:
一种是基于特征的语言模型,如 ELMO 模型
另一种是基于微调的语言模型,如 OpenAI GPT
主流模型对比
Word2Vec
Word2Vec 作为里程碑式的进步,对 NLP 的发展产生了巨大的影响。但 Word2Vec 本身是一种浅层结构价值训练的词向量,所“学习”到的语义信息受制于窗口大小,因此后续有学者提出利用可以获取长距离依赖的 LSTM 语言模型预训练词向量。
但上述语言模型有自身的缺陷。它是根据句子的上文信息来预测下文,或者根据下文来预测上文的。
我们理解语言,是需要考虑到双向的上下文信息,而传统的 LSTM 模型只学习到了单向的信息。
ELMO
今年年初, ELMO 的出现在一定程度上解决了这个问题。ELMO 是一种双层双向的 LSTM 结构,其训练的语言模型可以学习到句子左右两边的上下文信息,但此处所谓的上下文信息并不是真正意义上的上下文。
OpenAI GPT
除此之外, OpenAI 的 GPT 是利用了 Transformer 的编码器作为语言模型进行预训练的,之后特定的自然语言处理任务在其基础上进行微调即可。
和 LSTM 相比,此种语言模型的优点是可以获得句子上下文更远距离的语言信息,但也是单向的。
BERT
为了充分利用左右两侧的上下文信息, BERT 出现了!
OpenAI GPT 采用的从左到右的 Transformer;ELMO 采用经过单独训练的从左到右和从右到左的 LSTM 来生成下游任务的特征。
只有 BERT 模型采用的是双向 Transformer,模型的表示在所有层中,共同依赖于左右两侧的上下文。
BERT 的出现,似乎融合了其他模型的所有的优点,并摒弃了它们的缺点,因此才可以在诸多后续特定任务上取得最优的效果。
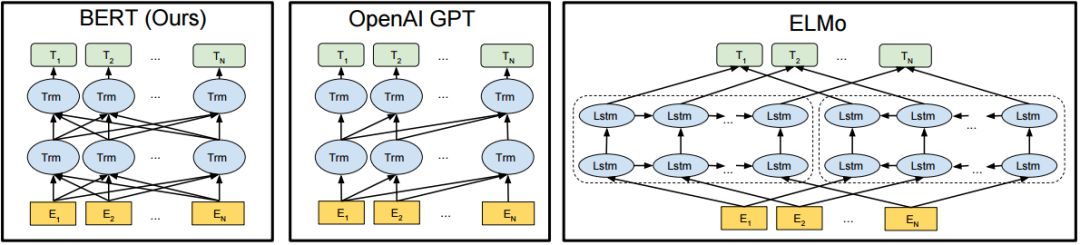
图1 预训练模型结构对比图
下面将从 BERT 模型的结构、输入以及训练三块进行介绍。
BERT 总体结构
BERT 是一种基于微调的多层双向 Transformer 编码器,其中的 Transformer 与原始的 Transformer 是相同的,并且实现了两个版本的 BERT 模型。在两个版本中前馈大小都设置为4层:
BERT BASE:L=12,H=768,A=12,Total Parameters=110M
BERT LARGE:L=24,H=1024,A=16,Total Parameters=340M
👆层数(即 Transformer blocks 块)表示为 L,隐藏大小表示为 H,自注意力的数量为 A。
BERT 模型两个版本的本质是一样的;区别是参数的设置。BERTBASE 作为 baseline 模型,在此基础上优化模型,进而出现了 BERTLARGE。
BERT 模型输入表示
输入表示,可以在一个词序列中表示单个文本句或一对文本,例如:[问题,答案]。对于给定的词,其输入表示是可以通过三部分 Embedding 求和组成。Embedding 的可视化表示👇:
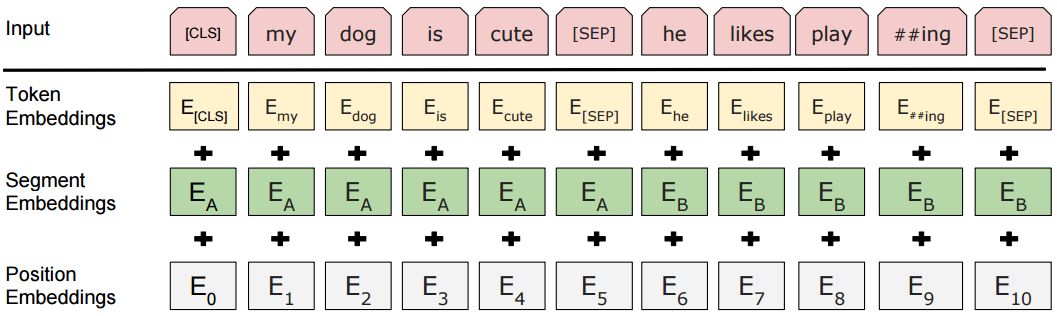
图2 BERT 模型的输入表示
其中:
token Embedding s表示的是词向量,第一个单词是CLS标志,可以用于之后的分类任务,对于非分类任务,可以忽略词向量
Segment Embedding s用来区别两种句子,因为预训练不只做语言模型还要做以两个句子为输入的分类任务
Position Embedding s是通过模型学习得到的
BERT 模型预训练任务
BERT 模型使用两个新的无监督预测任务对 BERT 进行预处理,分别是Masked LM 和 Next Sentence Prediction。
Masked LM

来源:Fresh 92.7
为了训练深度双向 Transformer 表示,采用了一种简单的方法:随机掩盖部分输入词,然后对那些被掩盖的词进行预测。
此方法被称为 Masked LM (MLM),预训练的目标是构建语言模型,BERT 模型采用的是 bidirectional Transformer。基于 Masked LM 预处理的 BERT 模型能够完成序列标注和命名实体识别等任务。
为什么采用 bidirectional 的方式呢?因为在预训练语言模型来处理下游任务时,我们需要的不仅仅是某个词左侧的语言信息,还需要右侧的语言信息。
在训练的过程中,随机地掩盖每个序列中15%的 token,并不是像 Word2Vec 中的 cbow 那样去对每一个词都进行预测。
MLM 从输入中随机地掩盖一些词,其目标是基于上下文,来预测被掩盖单词的原始词汇。与从左到右的语言模型预训练不同,MLM 目标允许表示融合左右两侧的上下文,这使得可以预训练深度双向 Transformer。
Transformer 编码器不知道它将被要求预测哪些单词,或者哪些已经被随机单词替换,因此它必须对每个输入词保持分布式的上下文表示。
此外,由于随机替换在所有词中只发生1.5%,所以并不会影响模型对于语言的理解。
Next Sentence Prediction

来源:BitDegree
很多句子级别的任务,如自动问答(QA)和自然语言推理(NLI)等任务,都需要理解两个句子之间的关系。譬如上述 Masked LM 任务中,经过第一步的处理,15%的词汇被遮盖。
那么在这一任务中,我们需要随机将数据划分为同等大小的两部分:
一部分数据中的两个语句对是上下文连续的
另一部分数据中的两个语句对是上下文不连续的。
然后让 Transformer 模型来识别这些语句对中,哪些语句对是连续的,哪些语句对不连续。
BERT 模型场景应用
命名实体识别
命名实体是文本中信息的主要载体,是构建信息抽取系统的重要组成部分。
BERT 模型在 CoNLL-2003 NER 数据集的试验结果, F1值相对于基线模型(CVT+Multi)只提高了0.2%,似乎指标上没有什么惊艳的表现,模型在实验上获得的指标提升远低于增加的计算成本。
但这种方式可以有效利用已有数据进行预训练,充分利用先验知识,在领域迁移性,模型通用型方面有巨大优势。
在命名实体识别,尤其是在开放域实体方面,BERT 模型给了我们很大的想象空间,相信以后在开放域实体识别方面会不断刷新基线模型的指标。
机器阅读理解
在机器阅读理解领域,经过谷歌、微软、百度、科大讯飞、腾讯、斯坦福大学等在内的众多研究机构的不懈努力,目前已形成了向量化-语义编码-语义交互-答案预测这样一套四层机器阅读理解模型体系。
从英文领域的代表 SQuAD 技术评测到中文领域的代表2018机器阅读理解技术竞赛,Top 团队无一例外的在“向量化”层做足了文章。
“向量化”层主要负责将问题及篇章公离散字符转变为隐含语义的表征向量,从 One-Hot 到 Word2Vec/Glove 再到 ELMO ,这一系列技术的变革都是在最大化的利用无监督的预训练方式,将更多的隐含语义信息嵌入模型,从而在不用应用场景中提高模型的评测指标。
BERT 模型则是利用 Deep bidirectional Transformers 预训练一个通用语言模型,从而更好的正确理解语句和文章的语义信息。
在 SQuAD 1.1竞赛评测中惊人表现,也证实了该模型至少在目前已经开始引领 NLP 发展的潮流。能不能最终摘取AI领域最后的皇冠,只能时间去验证。
情感计算
在情感计算领域,希望可以借助其强大的语言建模能力来获得更多的领域知识,进而减少后续特定自然语言任务的人工标注成本。
比如:可以先在维基百科或者某些商业售后评论上预训练语言模型,对相关领域进行“知识学习”,然后结合现有的有监督学习进行情绪识别和情感计算。
总结
语言模型的每一次进步都推动着 NLP 的发展。
从 Word2Vec 到 ELMO,从 OpenAI GPT 到 BERT,我们有幸见证着一个又一个记录被打破,见证着一个又一个 AI 项目成功落地。
人工智能,正在激励着人类向着未知探索前进。
顺便说一句,人工智能头条已经介入微软小冰机器人。大家可以在公众号随意聊天。
文末福利
1024感恩大促

请注意,知识点来了,为什么叫“猿族崛起”而不是“XXXX”呢?
程序员是人工智能时代的基石,是最有智慧的群体,是未来世界的缔造者,1024 是创造这一切的开始,我们一起见证了时代的变革,我们为创造了这个伟大的互联网时代而狂欢。

讲实话,1024 这种节日,会有很多福利活动,但很多都是听听就过了,没办法让你产生一丝兴奋。但,对于我们这种连做个课都得磨上半年的(变态)公司来说,老板说给程序员的福利只有一个要求:整点有用的,没用的不要。(此处应该有掌声)

所以,我们这个活动到底要怎样参加呢?再穷不能穷奖品——
活动期间全场课程、电子书 5 折起;
活动期间累计消费金额满 32 元(含购买会员),送价值 10 元通用优惠券,仅限前 1024 位;
活动期间累计消费金额满 128 元(含购买会员),送价值 99 元月度超级会员,仅限前 256 位;
活动期间累计消费金额满 512 元(含购买会员),送精美 CSDN 定制背包,不限量;每天随机抽取 3 位赠送价值 399 元机械键盘。
1024 优惠活动已经开始,按照以往大家抢购的速度来看,不到 5 个小时就把几百张优惠券全抢走了,去买极客书、买课程、看 Chat ......所以赶紧去扫描上方海报的二维码或者点击阅读原文参加活动吧,越晚不仅越贵,还有可能得不到礼品!

活动说明:
活动期间消费统计以实际支付金额为准;
活动礼品兑换以活动期间消费累计金额最高档为准;
活动礼品领取将在活动结束后统一发送通知,请大家注意关注服务号(GitChat)查看通知;
本次活动最终解释权归 GitChat 所有。





