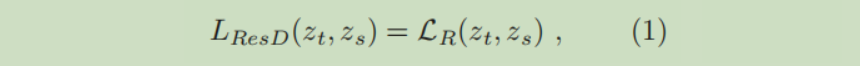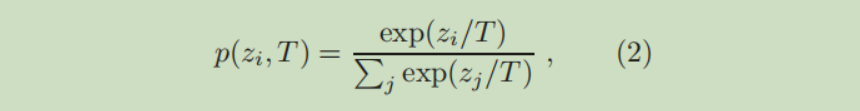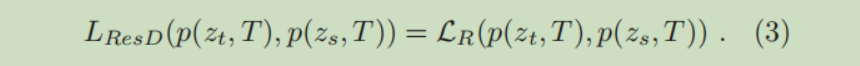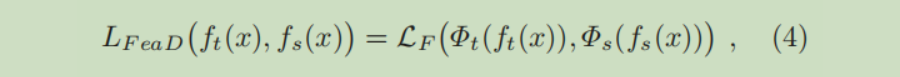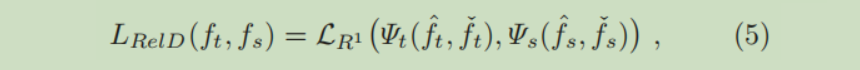![]()
©作者 | 夏劲松
学校 | 哈尔滨理工大学
研究方向 | 知识蒸馏、图神经网络
摘要
深度学习通过参数量巨大的模型,近几年中在多个领域取得了较好的效果,但是往往因为模型体积过大(模型的体积指的就是模型的大小,比如 ResNet18 体积为 44.6MB 等)、计算耗时等因素,无法部署在一些资源受限的移动设备或者嵌入式设备中。因此人们提出了多种对模型体积进行压缩,或者加速模型计算的方法。
在这些方法中,知识蒸馏利用一个体积小的模型(在知识蒸馏中称为学生神经网络,Student)从一个体积较大的模型中学习知识(在知识蒸馏中称为教师神经网络, Teacher),进行模型压缩,得到了学术界的关注。
这篇文章从以下几方面提供给读者一个对知识蒸馏清晰的认识:
![]()
论文标题:
Knowledge Distillation: A Survey
https://arxiv.org/abs/2006.05525
![]()
引言
近几年随着一些训练深层神经网络方法的提出,比如残差连接,Batch Normalization(BN),和算力的提升,使得训练一些深层的神经网络已经不像以前那么困难了,而且这些具有更深层的神经网络被证明在许多任务上是有效的。但是还是存在一个问题——那就是无法有效的将这些体积巨大的模型部署在一些资源受限的设备中。
关于如何训练更深的网络结构,普遍从以下几方面入手:
1. 设计更有效的 blocks,(blocks 的意思是作为一个深度学习神经网络中的基本层,然后我们可以像搭积木一样重叠 blocks,以此来构建更深层的网络结构)。比如 MobileNets 中深度可分离卷积的设计。
1. Parameter pruning and sharing:这种方法的核心思想是删除掉神经网络中那些对于最终模型效果没有指导作用的参数,压缩模型的体积。方法包括——Model Quantization(原先用 float 存储,转换为用 int 存储),Model Binarization(二级制存储),Structural Matrices, Parameter sharing.
2. Low-rank factorization:分解参数矩阵;
3. Transferred compact convolutional filter:压缩卷积核中的无用参数;
4. Konwledge distillation(KD):本文要介绍的知识蒸馏。
知识蒸馏的主要思路是利用一个预先在数据集上进行过训练的教师神经网络(一般体积较大),去指导、监督一个学生神经网络的训练(一般体积较教师神经网络要小很多)。
面临的主要问题就是如何迁移教师神经网络中学习到的知识到学生神经网络中。
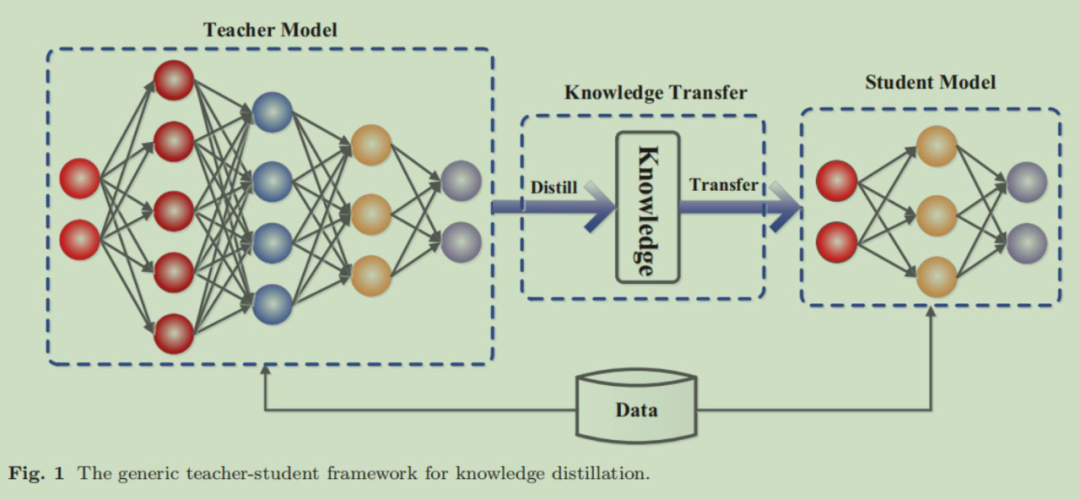
一个知识蒸馏系统的必要组成是:知识的发掘、蒸馏方法、教师,学生结构的设计。如图所示:
![]()
首先利用数据集训练一个教师神经网络 [最左边],教师神经网络会通过训练过程逐渐学习到隐藏在数据集上的知识。
然后我们要发掘出教师神经网络都学习到了那些知识 [中间].
通过 Distill 和 Transforer,将这些已经学习到的知识,迁移到学生神经网络中。
学生神经网络同样是在数据集上进行训练,只不过相比于教师神经网络,它有额外的来自于教师神经网络的知识,辅助训练。
但是知识蒸馏存在一个问题:没有严格的理论支撑。大多都是来自于训练过程中的经验,一些研究人员做了一些理论层面的研究(最近在读这方面的论文)
模仿人类学习的过程,知识蒸馏逐渐发展出:teacher-student learning(普通的知识蒸馏过程。训练完的教师神经网络指导学生神经网络的训练)、mutual learning(互相学习,在多教师或者多学生知识蒸馏过程中有体现,相当于一种模型集成方法)、assistant teachering,lifelong learning,self-learning(教师和学生模型是同一个,也叫 self-distillation,自蒸馏)
知识蒸馏不仅可以作为一种模型压缩的方法,它也被用作一种迁移学习的方法应用在不同领域中(个人感觉迁移学习这个角度应用知识蒸馏比较重要,上一篇论文的创新点压在了这里)。
![]()
Knowledge
![]()
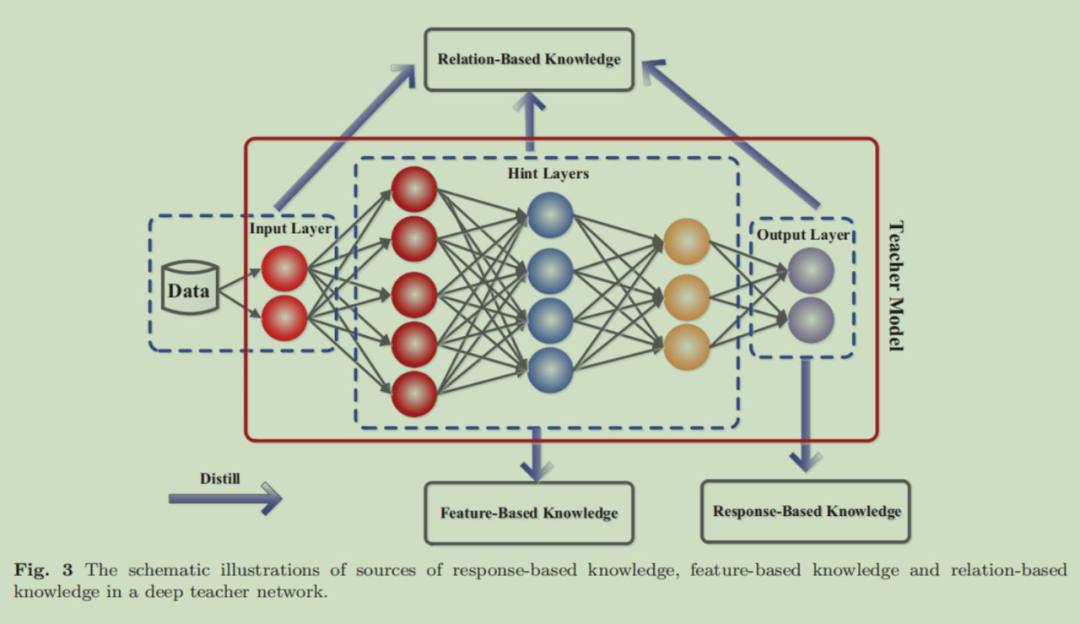
上面我们一直在说‘知识’,那么知识蒸馏中的知识具体都有哪些呢。
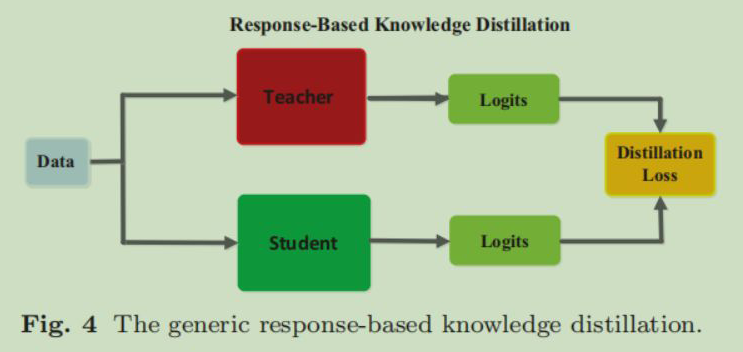
可以简单理解为所谓的教师神经网络中包含的知识就是各个网络层的输出或者其包含的参数。Response-Based Knowledge 是教师神经网络最后的输出,也叫 Logits,注意这个 Logits 是没经过 Softmax 计算的网络输出。
https://zhuanlan.zhihu.com/p/51431626
Feature-Based Konwledge 指的是教师神经网络中间层的输出,比如卷积神经网络中卷积层输出的 Feature Map,循环神经网络中的 hidden state,Transformer 中的注意力矩阵等。Relation-Based Knowledge 可以理解为是教师神经网络所有中间输出结果之间的一种关系捕获,所有知识之间的关系。
最初的知识蒸馏(Hinton 他们)使用的是教师神经网络的 Logits 作为知识。后来开始用中间层的一些输出作为知识进行蒸馏。不同知识之间的关系也可以看做一种知识用来进行知识蒸馏。在这篇文章中,我们称以上三种知识为:response-based konwledge,feature-based knowledge,relation-based knowledge。下面分别介绍。
2.1 Response-Based Knowledge
Response-Based Knowledge 指的是教师神经网络最后的输出(未经过Softmax,一般叫 Logits)。利用这种知识的蒸馏思想是直接让学生神经网络模仿教师神经网络的预测。
蒸馏损失函数(知识蒸馏中提出的一个附加在原始损失函数后面的函数,用来刻画在蒸馏的过程中有多少教师神经网络中的知识被蒸丢了。)定义为:
![]()
其中
是教师神经网络,学生神经网络的 Logits,
是一个能够衡量相似性的函数。一般不直接计算上面的损失函数,而是先将
利用一个温度参数(知识蒸馏的命名来源于此操作)进行平滑处理,计算公式为
![]()
![]()
![]()
首先注意 Teacher 已经在 Data 上训练过了,然后在利用 Data 训练 Student 的时候,同样将 Data 输入到 teacher 中。因为我们想获取 Teacher 中的知识,而知识我们上面说过可以简单的理解为就是 teacher 的输出,要想获得输出你得首先有个输入吧,所以在知识蒸馏的过程中还是要将 Data 输入到 teacher 中的。
前向传递,获取到 teacher 的 Logits,student 的 Logits,计算我们上面定义的蒸馏损失,还有关于 Data 自身的损失函数,比如如果 Data 是图像分类,那么可能就是计算一个交叉熵损失。
计算完损失之后,反向传播,更新 Student 中的参数。注意在普通的知识蒸馏中 Teacher 是不随着更新的。
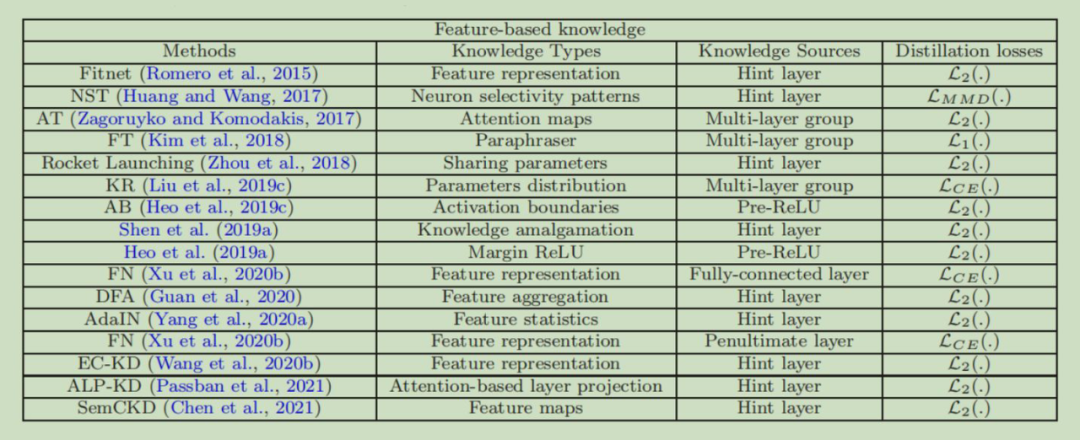
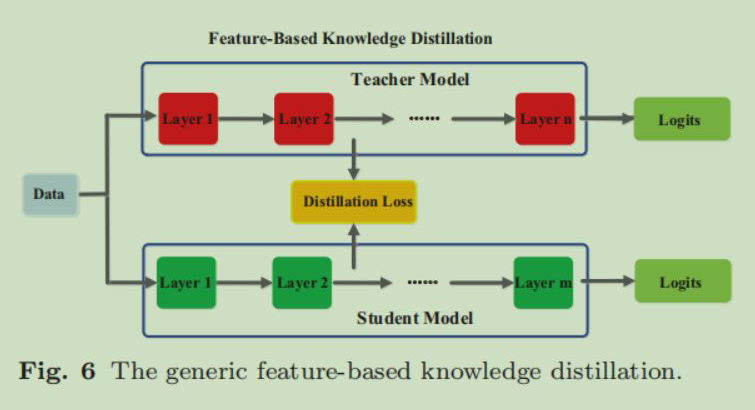
2.2 Feature-Based Knowledge
把中间层的输出作为一种知识,进行知识蒸馏,蒸馏损失函数定义为:
![]()
其中
分别是教师神经网络,学生神经网络的中间层输出,也就是 Feature-Based Knowledge,外面的
是当两个网络中间层输出维度不一样时使用的维度变换函数(也叫知识嵌入,中间层知识蒸馏重点就在于设计这个
),
是一个能够衡量相似性的函数。
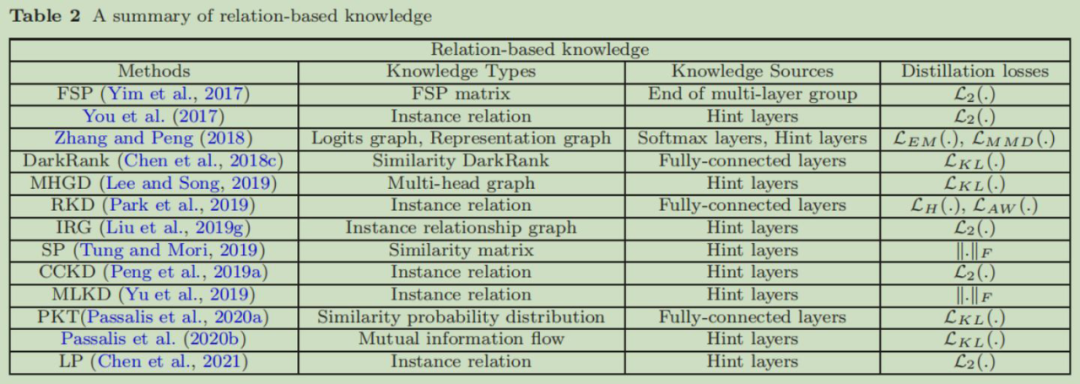
![]()
这个表中,第一列是中间层知识蒸馏方法名,第二列是那种中间层知识进行蒸馏,第三列是知识的来源,也就是网络中哪一层的输出,最后一列表明使用的衡量相似性的函数是什么。
![]()
首先还是 Teacher 是在 Data 上进行过训练的模型,然后对于中间层知识蒸馏,我们事先要指定对于 Teacher 和 Student 的哪个中间层进行知识蒸馏,然后分别获取这个指定中间层的输出,计算中间层知识蒸馏损失,反向传播,更新学生网络。
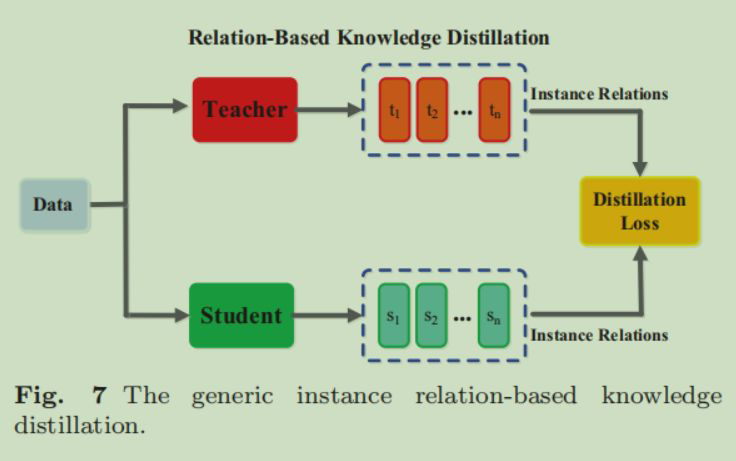
2.3 Relation-Based Knowledge
利用知识之间的关系进行知识蒸馏,知识可以是网络的输出,也可以是中间层的输出,重点在于它们之间的关系,利用这个关系进行知识蒸馏,蒸馏损失函数为:
![]()
符号含义没有变化,但是为什么里面是两个 f 呢,因为我们想要获取的是知识之间的关系,只有两个以上的物体才可以谈得上具有关系,所以里面是两个 f,其实也不一定是两个,多少个都行,这个是你自己定义的,你用三个中间层的输出建立关系,那自然里面就是三个啦。
![]()
还是首先 Teacher 要进行在 Data 上的预训练,然后获取我们想要发现它们之间关系的知识,图中标虚线的那里,用提取出来的关系进行知识蒸馏。我跑过几个这种类型的知识蒸馏实验,有基于图捕获知识之间关系的,有知识之间算一个关系矩阵的,个人感觉,训练明显比前两个耗时而且准确率提升的效果一般。
![]()
Distillation Schemes
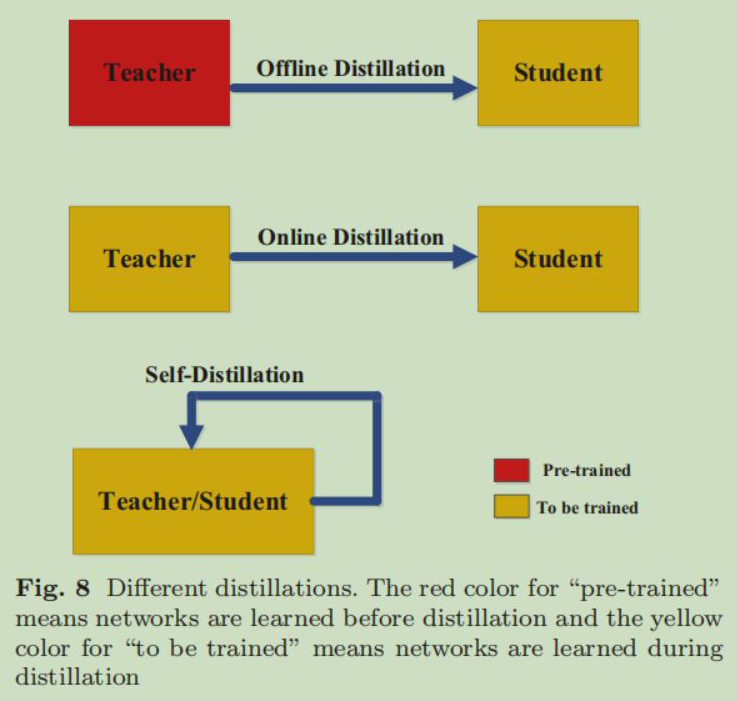
本节介绍知识蒸馏中教师、学生网络的训练方式,根据教师神经网络是否随着学生神经网络的更新而更新,可以分为:
![]()
3.1 Offine Distillation
这是最原始的知识蒸馏训练方式:先在数据集(可以是与学生神经网络相同的数据集,不同的但是任务相同的也可以)上预训练教师神经网络,然后提取教师神经网络中的知识指导学生神经网络的训练。
3.2 Online Distillation
这种方式的知识蒸馏中教师神经网络会随着学生神经网络的更新进行更新(可以把学生神经网络的损失作为一种反馈信号,教师神经网络利用这个反馈信号提升自己,以便更好的指导学生),另外一种方式常见于多教师知识蒸馏中,这种方法中教师神经网络的结构是动态变化的。
3.3 Self-Distillation
教师神经网络和学生神经网络是同一个结构。可以把网络深层的输出作为一种知识指导网络浅层的训练(神经网络中更深层的网络层,学习到的更多是与数据无关的、较高层次的抽象知识,可以联想卷积神经网络,卷积神经网络最后面那些深层的卷积学习到的是图片中的语义层面的知识,浅层是图像的边缘,点什么的信息)。
Teacher-Student Architecture
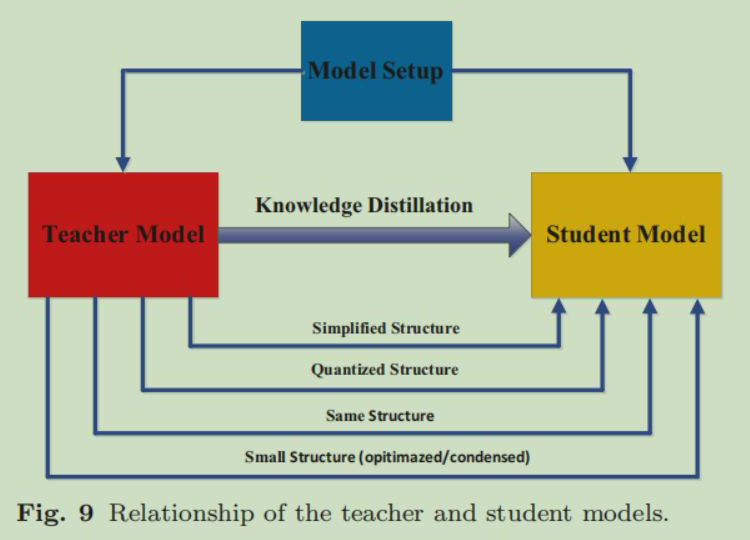
这节讲知识蒸馏中教师、学生神经网络的结构如何设计。
![]()
教师神经网络的结构一般没啥要求,根据教师神经网络我们有以下几种方式设计学生神经网络的结构:
1. Simplified Stucture:比如教师神经网络是 ResNet101,学生神经网络是ResNet18;
2. Quantized Structrue:比如 float 存储转为 int 存储;
4. Small Sturcture:原先 6 个卷积层,学生可以选 3 个卷积层。
![]()
Distillation Alorithms
在上面介绍的知识蒸馏方法基础上介绍一些其它的知识蒸馏方法。
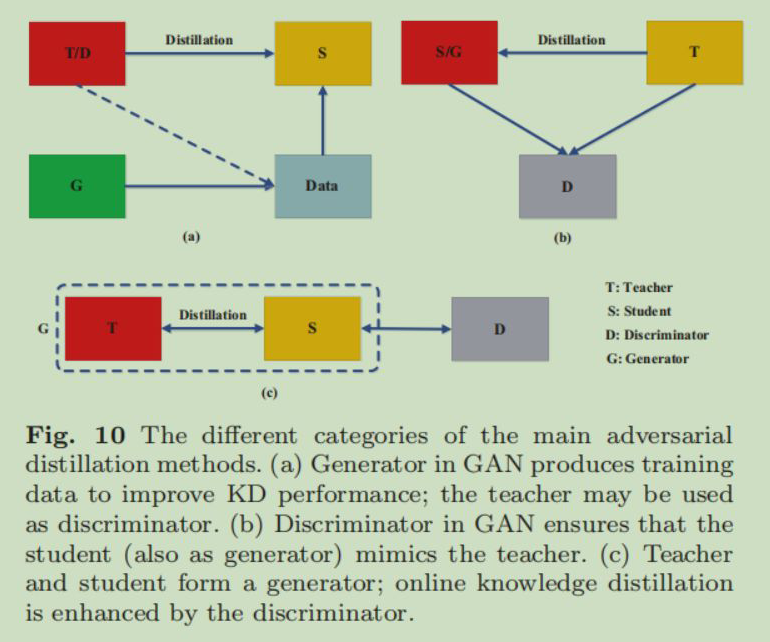
5.1 Adversarial Distillation
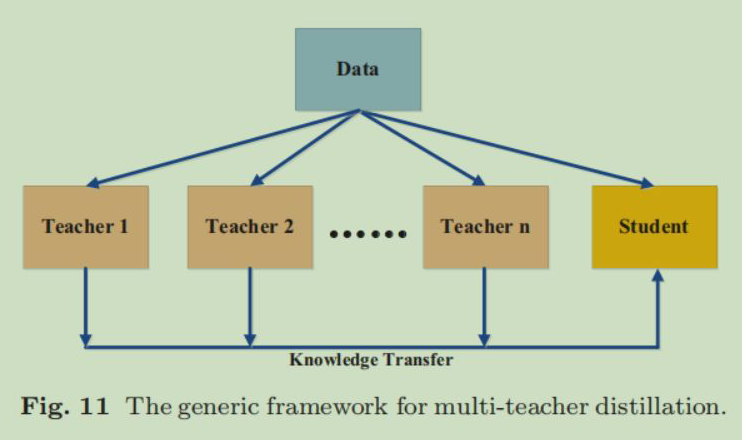
5.2 Multi-Teacher Distillation
![]()
这种方式研究的比较多,利用多个教师指导一个学生,相当于一种模型集成方法。
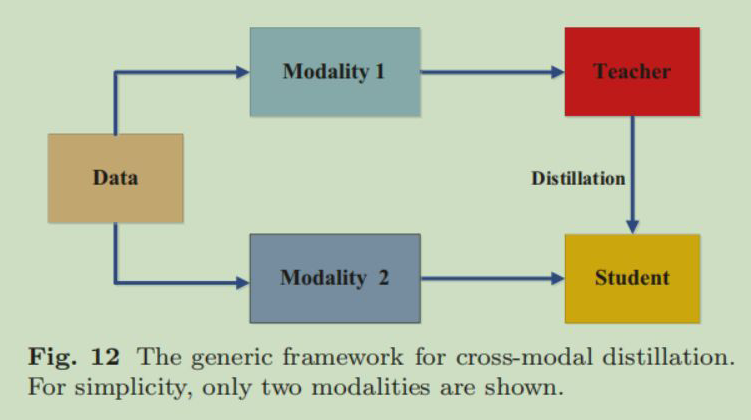
5.3 Cross-Modal Distillation
将在 A 模态数据集上训练的教师神经网络中的知识迁移到 B 模态数据集上训练学生神经网络:
![]()
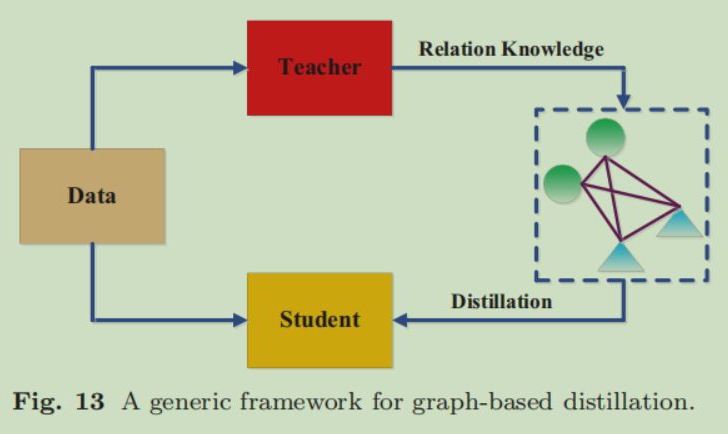
5.4 Grpaph-Based Distillation
将知识之间的关系组织成图,然后利用图结构指导学生神经网络的训练:
5.5 Attention-Based Distillation
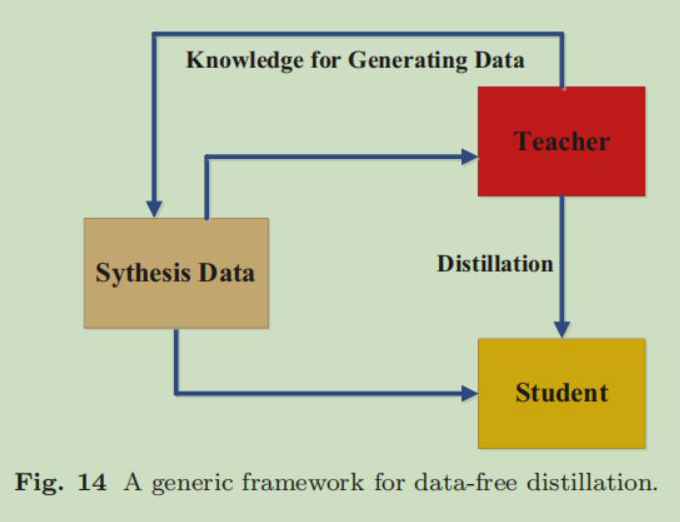
5.6 Data-Free Distillation
![]()
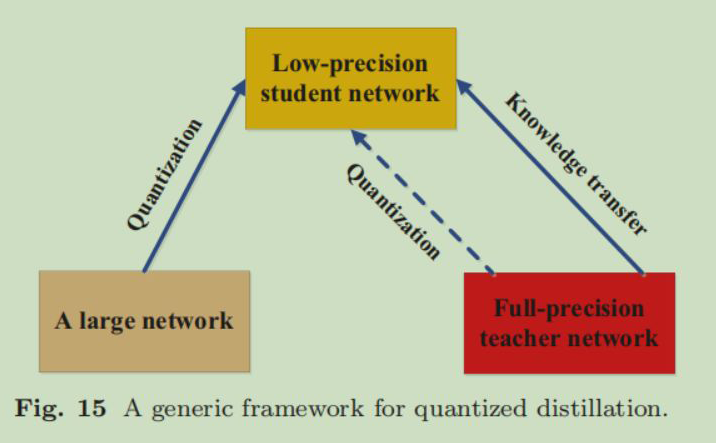
5.7 Quantized Distillation
5.8 Lifelong Distillation
将知识蒸馏作为一种迁移学习任务,用于增量学习,小样本学习等领域。
5.9 NAS-Based Distillation
![]()
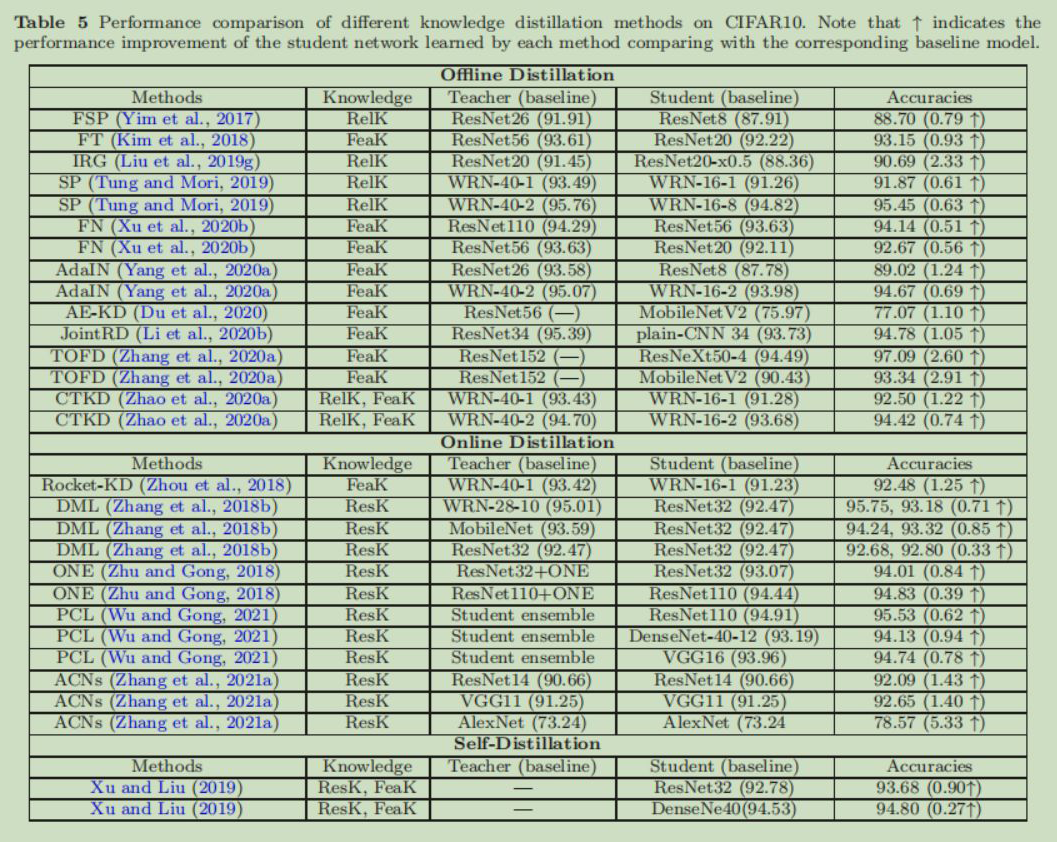
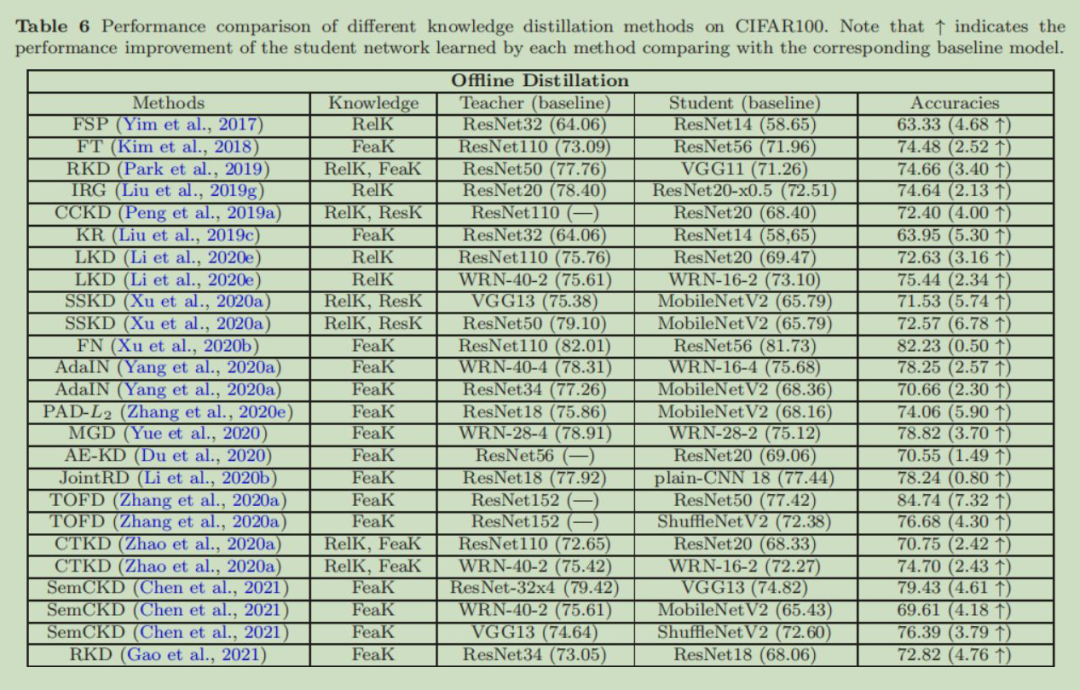
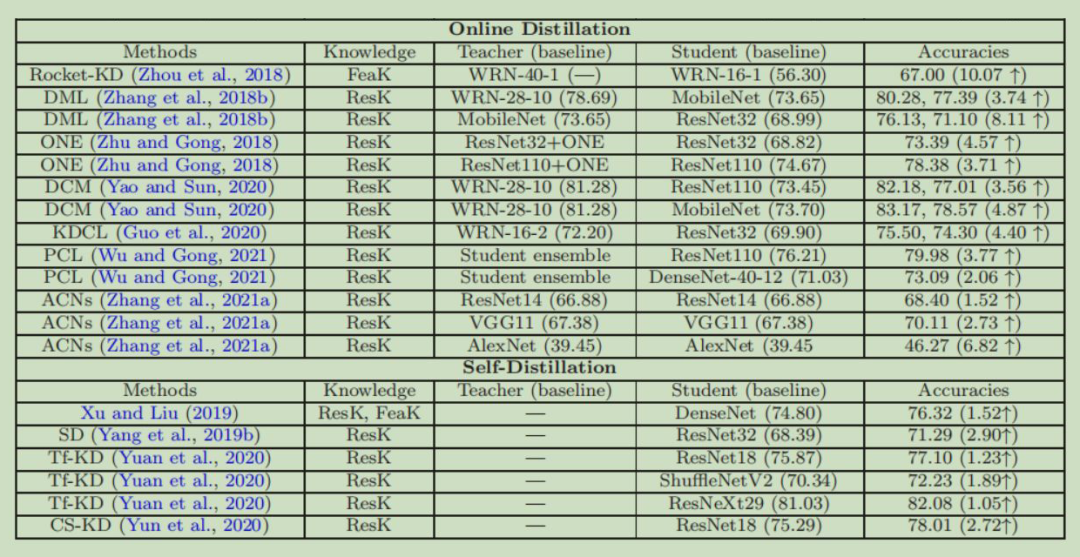
Performance Comparison
比较了知识蒸馏方法在 CIFAR-10,CIFAR-100 上的准确率提升:
![]()
![]()
![]()
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()