八篇NeurIPS 2019最新公布的【图神经网络(GNN)】相关论文
【导读】最近,人工智能和机器学习领域的国际顶级会议NeurIPS 2019接收论文公布,共有1428篇论文被接收。为了带大家抢先领略高质量论文,专知小编特意整理了八篇NeurIPS 2019最新GNN相关论文,并附上arXiv论文链接供参考。
IJCAI2019GNN_Part1、IJCAI2019GNN_Part2、 KDD2019GNN、ACL2019GNN、CVPR2019GNN、 ICML2019GNN
1. Approximation Ratios of Graph Neural Networks for Combinatorial Problems
作者:Ryoma Sato, Makoto Yamada, Hisashi Kashima;
摘要:本文从理论的角度研究了图神经网络(GNNs)在学习组合问题近似算法中的作用。为此,我们首先建立了一个新的GNN类,它可以严格地解决比现有GNN更广泛的问题。然后,我们弥合了GNN理论和分布式局部算法理论之间的差距,从理论上证明了最强大的GNN可以学习最小支配集问题的近似算法和具有一些近似比的最小顶点覆盖问题比率,并且没有GNN可以执行比这些比率更好。本文首次阐明了组合问题中GNN的近似比。此外,我们还证明了在每个节点特征上添加着色或弱着色可以提高这些近似比。这表明预处理和特征工程在理论上增强了模型的能力。


网址:
https://arxiv.org/abs/1905.10261
2. D-VAE: A Variational Autoencoder for Directed Acyclic Graphs
作者:Muhan Zhang, Shali Jiang, Zhicheng Cui, Roman Garnett, Yixin Chen;
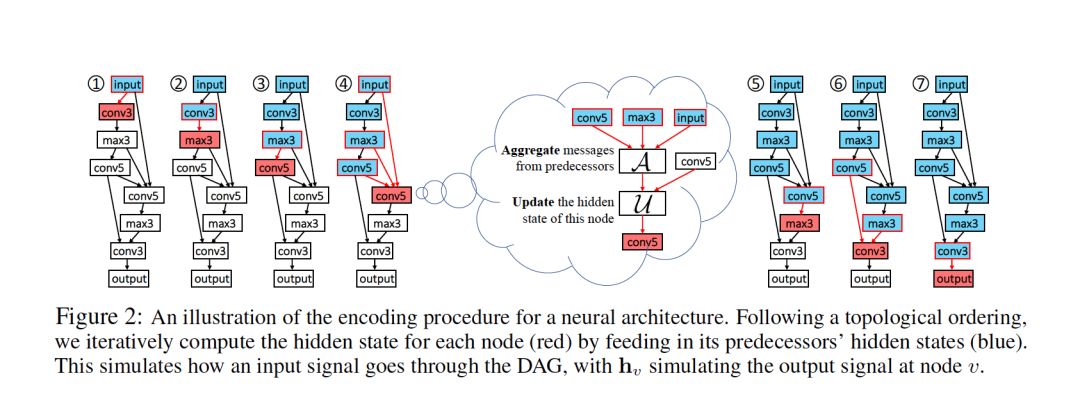
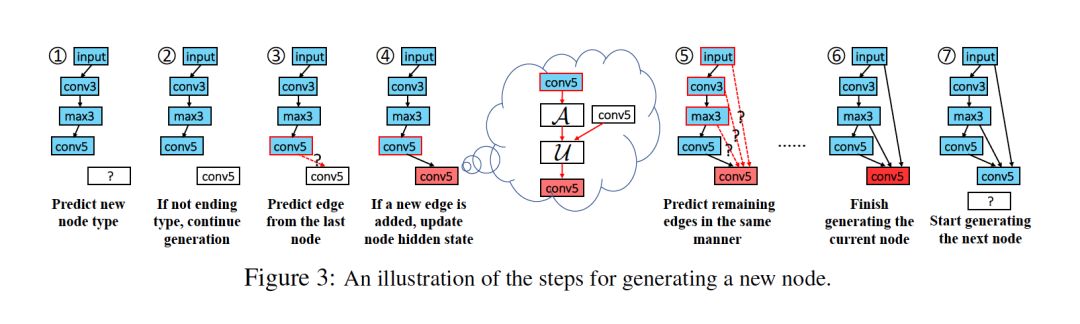
摘要:图结构数据在现实世界中是丰富的。在不同的图类型中,有向无环图(DAG)是机器学习研究人员特别感兴趣的,因为许多机器学习模型都是通过DAG上的计算来实现的,包括神经网络和贝叶斯网络。本文研究了DAG的深度生成模型,提出了一种新的DAG变分自编码器(D-VAE)。为了将DAG编码到潜在空间中,我们利用了图神经网络。我们提出了一个异步消息传递方案,它允许在DAG上编码计算,而不是使用现有的同步消息传递方案来编码局部图结构。通过神经结构搜索和贝叶斯网络结构学习两项任务验证了该方法的有效性。实验表明,该模型不仅生成了新颖有效的DAG,还可以生成平滑的潜在空间,有助于通过贝叶斯优化搜索具有更好性能的DAG。
网址:
https://arxiv.org/abs/1904.11088
3. End to end learning and optimization on graphs
作者:Bryan Wilder, Eric Ewing, Bistra Dilkina, Milind Tambe;
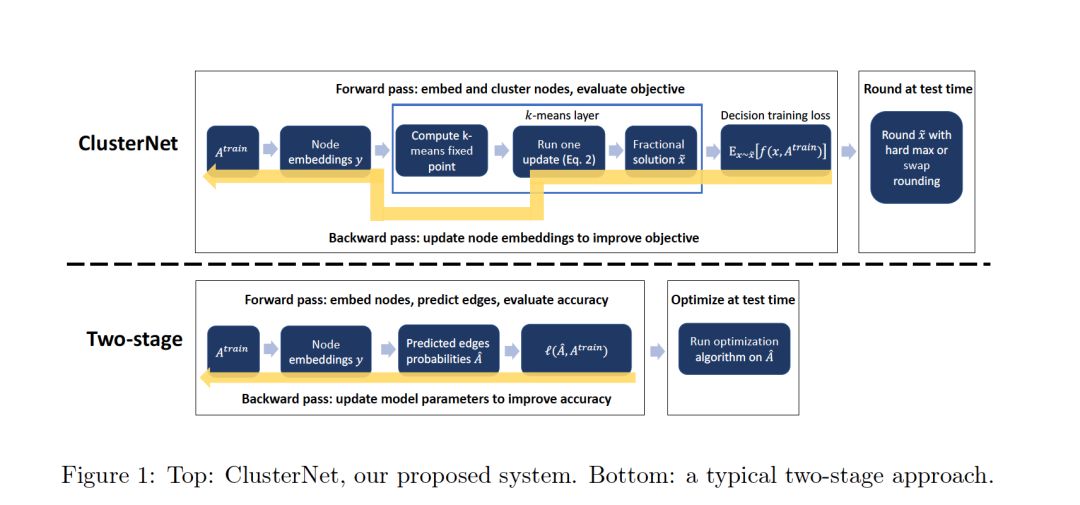
摘要:在实际应用中,图的学习和优化问题常常结合在一起。例如,我们的目标可能是对图进行集群,以便检测有意义的社区(或者解决其他常见的图优化问题,如facility location、maxcut等)。然而,图或相关属性往往只是部分观察到,引入了一些学习问题,如链接预测,必须在优化之前解决。我们提出了一种方法,将用于常见图优化问题的可微代理集成到用于链接预测等任务的机器学习模型的训练中。这允许模型特别关注下游任务,它的预测将用于该任务。实验结果表明,我们的端到端系统在实例优化任务上的性能优于将现有的链路预测方法与专家设计的图优化算法相结合的方法。
网址:
https://arxiv.org/abs/1905.13732
4. Graph Neural Tangent Kernel: Fusing Graph Neural Networks with Graph Kernels
作者:Simon S. Du, Kangcheng Hou, Barnabás Póczos, Ruslan Salakhutdinov, Ruosong Wang, Keyulu Xu;
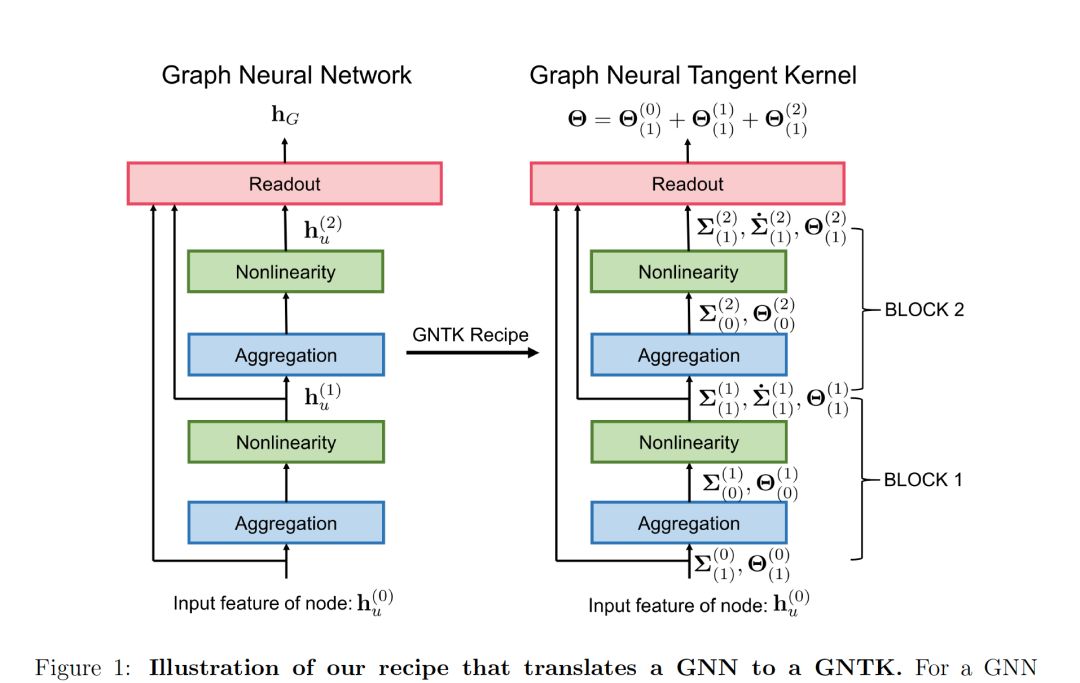
摘要:虽然图内核(graph kernel,GK)易于训练并享有可证明的理论保证,但其实际性能受其表达能力的限制,因为内核函数往往依赖于图的手工组合特性。与图内核相比,图神经网络通常具有更好的实用性能,因为图神经网络使用多层结构和非线性激活函数来提取图的高阶信息作为特征。然而,由于训练过程中存在大量的超参数,且训练过程具有非凸性,使得GNN的训练更加困难。GNN的理论保障也没有得到很好的理解。此外,GNN的表达能力随参数的数量而变化,在计算资源有限的情况下,很难充分利用GNN的表达能力。本文提出了一类新的图内核,即图神经切线核(GNTKs),它对应于通过梯度下降训练的无限宽的多层GNN。GNTK充分发挥了GNN的表现力,继承了GK的优势。从理论上讲,我们展示了GNTK可以在图上学习一类平滑函数。根据经验,我们在图分类数据集上测试GNTK并展示它们实现了强大的性能。
网址:
https://arxiv.org/abs/1905.13192
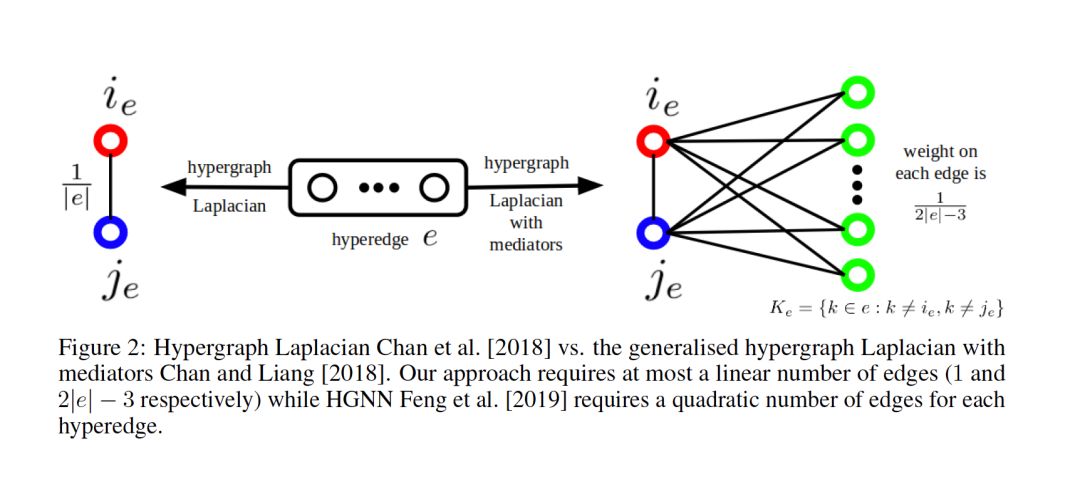
5. HyperGCN: A New Method of Training Graph Convolutional Networks on Hypergraphs
作者:Naganand Yadati, Madhav Nimishakavi, Prateek Yadav, Vikram Nitin, Anand Louis, Partha Talukdar;
摘要:在许多真实世界的网络数据集中,如co-authorship、co-citation、email communication等,关系是复杂的,并且超越了成对关联。超图(Hypergraph)提供了一个灵活而自然的建模工具来建模这种复杂的关系。在许多现实世界网络中,这种复杂关系的明显存在,自然会激发使用Hypergraph学习的问题。一种流行的学习范式是基于超图的半监督学习(SSL),其目标是将标签分配给超图中最初未标记的顶点。由于图卷积网络(GCN)对基于图的SSL是有效的,我们提出了HyperGCN,这是一种在超图上训练用于SSL的GCN的新方法。我们通过对真实世界超图的详细实验证明HyperGCN的有效性,并分析它何时比最先进的baseline更有效。
网址:
https://arxiv.org/abs/1809.02589
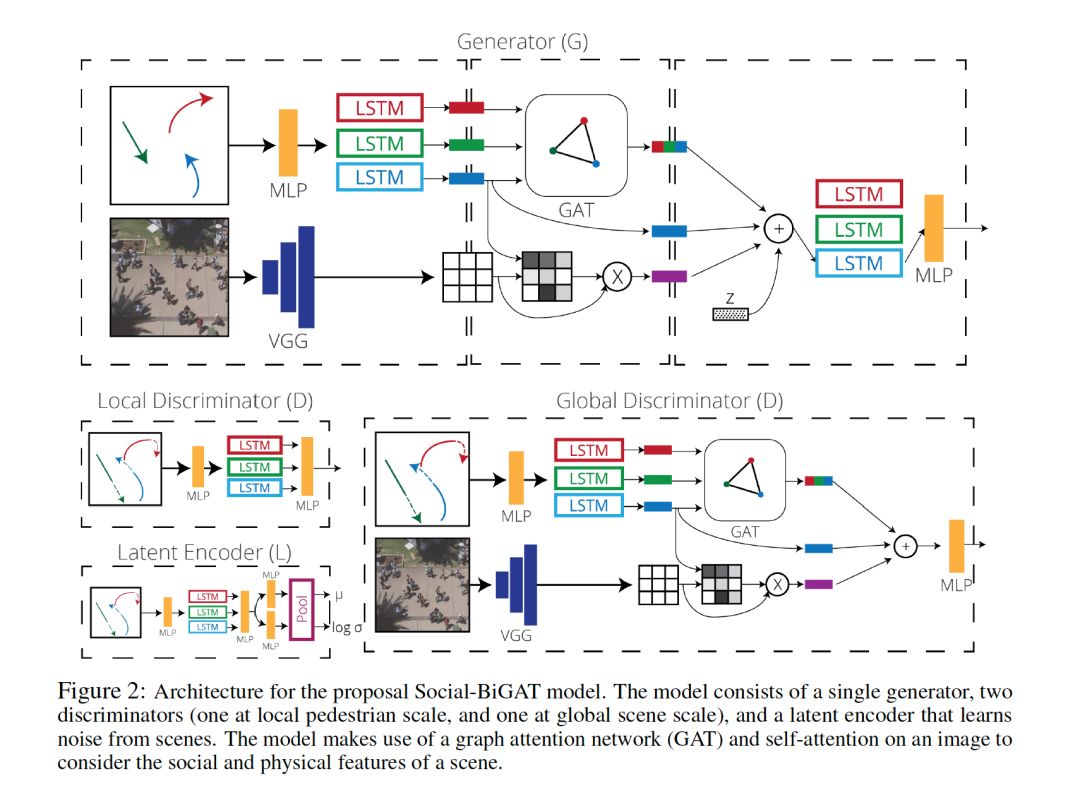
6. Social-BiGAT: Multimodal Trajectory Forecasting using Bicycle-GAN and Graph Attention Networks
作者:Vineet Kosaraju, Amir Sadeghian, Roberto Martín-Martín, Ian Reid, S. Hamid Rezatofighi, Silvio Savarese;
摘要:从自动驾驶汽车和社交机器人的控制到安全监控,预测场景中多个交互主体的未来轨迹已成为许多不同应用领域中一个日益重要的问题。这个问题由于人类之间的社会互动以及他们与场景的身体互动而变得更加复杂。虽然现有的文献探索了其中的一些线索,但它们主要忽略了每个人未来轨迹的多模态性质。在本文中,我们提出了一个基于图的生成式对抗网络Social-BiGAT,它通过更好地建模场景中行人的社交互来生成真实的多模态轨迹预测。我们的方法是基于一个图注意力网络(GAT)学习可靠的特征表示(编码场景中人类之间的社会交互),以及一个反方向训练的循环编解码器体系结构(根据特征预测人类的路径)。我们明确地解释了预测问题的多模态性质,通过在每个场景与其潜在噪声向量之间形成一个可逆的变换,就像在Bicycle-GAN中一样。我们表明了,与现有轨迹预测基准的几个baseline的比较中,我们的框架达到了最先进的性能。
网址:
https://arxiv.org/abs/1907.03395
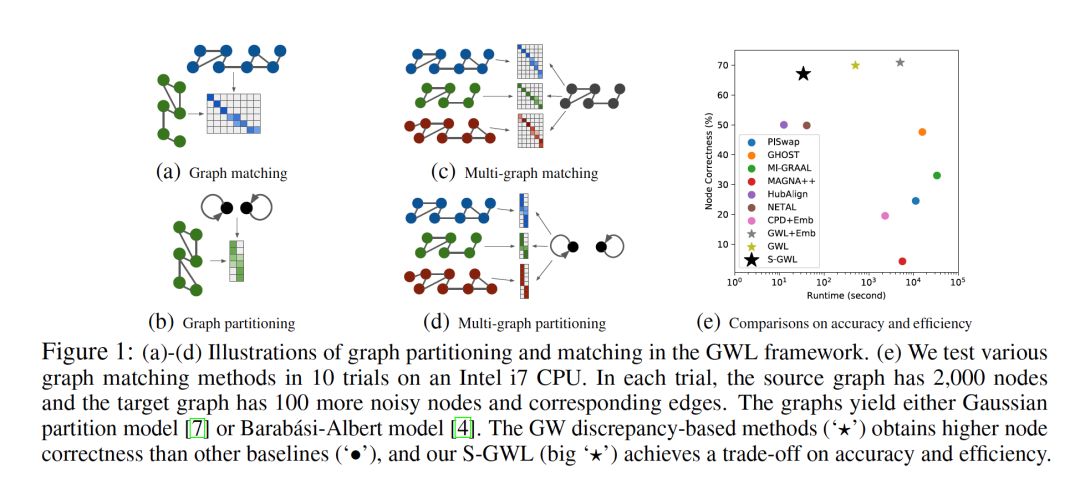
7. Scalable Gromov-Wasserstein Learning for Graph Partitioning and Matching
作者:Hongteng Xu, Dixin Luo, Lawrence Carin;
摘要:我们提出了一种可扩展的Gromov-Wasserstein learning (S-GWL) 方法,并建立了一种新的、理论支持的大规模图分析范式。该方法基于Gromov-Wasserstein discrepancy,是图上的伪度量。给定两个图,与它们的Gromov-Wasserstein discrepancy相关联的最优传输提供了节点之间的对应关系,从而实现了图的匹配。当其中一个图具有独立但自连接的节点时(即,一个断开连接的图),最优传输表明了其他图的聚类结构,实现了图的划分。利用这一概念,通过学习多观测图的Gromov-Wasserstein barycenter图,将该方法推广到多图的划分与匹配; barycenter图起到断开图的作用,因为它是学习的,所以聚类也是如此。该方法将递归K分割机制与正则化近似梯度算法相结合,对于具有V个节点和E条边的图,其时间复杂度为O(K(E+V) logk V)。据我们所知,我们的方法是第一次尝试使Gromov-Wasserstein discrepancy适用于大规模的图分析,并将图的划分和匹配统一到同一个框架中。它优于最先进的图划分和匹配方法,实现了精度和效率之间的平衡。
网址:
https://arxiv.org/abs/1905.07645
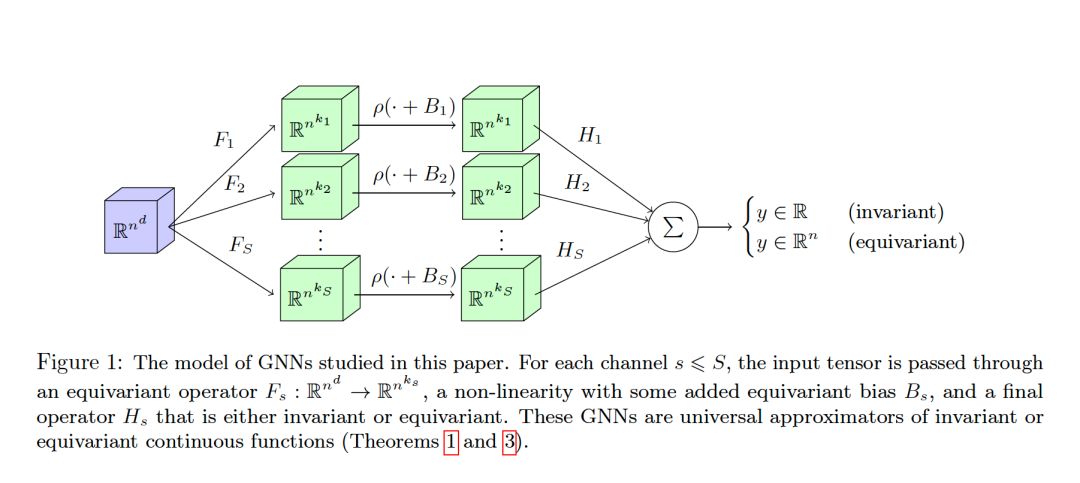
8. Universal Invariant and Equivariant Graph Neural Networks
作者:Nicolas Keriven, Gabriel Peyré;
摘要:图神经网络(GNN)有多种形式,但应该始终是不变的(输入图节点的排列不会影响输出)或等变的(输入的排列置换输出)。本文考虑一类特殊的不变和等变网络,证明了它的一些新的普适性定理。更确切地说,我们考虑具有单个隐藏层的网络,它是通过应用等变线性算子、点态非线性算子和不变或等变线性算子形成的信道求和而得到的。最近,Maron et al. (2019b)指出,通过允许网络内部的高阶张量化,可以获得通用不变的GNN。作为第一个贡献,我们提出了这个结果的另一种证明,它依赖于实值函数代数的Stone-Weierstrass定理。我们的主要贡献是将这一结果推广到等变情况,这种情况出现在许多实际应用中,但从理论角度进行的研究较少。证明依赖于一个新的具有独立意义的广义等变函数代数Stone-Weierstrass定理。最后,与以往许多考虑固定节点数的设置不同,我们的结果表明,由一组参数定义的GNN可以很好地近似于在不同大小的图上定义的函数。
网址:
https://arxiv.org/abs/1905.04943








