作者:Batchlechner等
机器之心编译
机器之心编辑部
深度学习在众多领域都取得了显著进展,但与此同时也存在一个问题:深层网络的训练常常面临梯度消失或梯度爆炸的阻碍,尤其是像 Transformer 这样的大型网络。现在,加州大学圣迭戈分校的研究者提出了一种名为 ReZero 的神经网络结构改进方
法,并使用 ReZero 训练了具有一万层的全连接网络,以及首次训练了超过 100 层的 Tansformer,效果都十分惊艳。
![]()
深度学习在计算机视觉、自然语言处理等领域取得了很多重大突破。神经网络的表达能力通常随着其网络深度呈指数增长,这一特性赋予了它很强的泛化能力。然而深层的网络也产生了梯度消失或梯度爆炸,以及模型中的信息传递变差等一系列问题。研究人员使用精心设计的权值初始化方法、BatchNorm 或 LayerNorm 这类标准化技术来缓解以上问题,然而这些技术往往会耗费更多计算资源,或者存在其自身的局限。
近日,来自加州大学圣迭戈分校(UCSD)的研究者提出一种神经网络结构改进方法「ReZero」,它能够动态地加快优质梯度和任意深层信号的传播。
论文地址:https://arxiv.org/abs/2003.04887v1
代码地址:https://github.com/majumderb/rezero
这个想法其实非常简单:ReZero 将所有网络层均初始化为恒等映射。在每一层中,研究者引入了一个关于输入信号 x 的残差连接和一个用于调节当前网络层输出 F(x) 的可训练参数α,即:
在刚开始训练的时候将α设置为零。这使得在神经网络训练初期,所有组成变换 F 的参数所对应的梯度均消失了,之后这些参数在训练过程中动态地产生合适的值。改进的网络结构如下图所示:
学习信号能够有效地在深层神经网络中传递,这使得我们能够训练一些之前所无法训练的网络。研究者使用 ReZero 成功训练了具有一万层的全连接网络,首次训练了超过 100 层的 Tansformer 并且没有使用学习速率热身和 LayerNorm 这些奇技淫巧。
与带有标准化操作的常规残差网络相比,ReZero 的收敛速度明显更快。当 ReZero 应用于 Transformer 时,在 enwiki8 语言建模基准上,其收敛速度比一般的 Transformer 快 56%,达到 1.2BPB。当 ReZero 应用于 ResNet,在 CIFAR 10 上可实现 32% 的加速和 85% 的精度。
ReZero (residual with zero initialization)
ReZero 对深度残差网络的结构进行了简单的更改,可促进动态等距(dynamical isometry)并实现对极深网络的有效训练。研究者在初始阶段没有使用那些非平凡函数 F[W_i] 传递信号,而是添加了一个残差连接并通过初始为零的 L 个可学习参数α_i(作者称其为残差权重)来重新缩放该函数。目前,信号根据以下方式进行传递:
在初始阶段,该网络表示为恒等函数并且普遍满足动态等距关系。在该架构修改中,即使某一层的 Jacobian 值消失,也可以训练深度网络(正如 ReLU 激活函数或自注意力机制出现这样的状况)。这一技术还可以在现有的已训练网络上添加新层。
图 3 展示了训练损失的演变过程。在一个简单实验中,一个使用了 ReZero 的 32 层网络,拟合训练数据的收敛速度相比其他技术快了 7 到 15 倍。值得注意的是,与常规的全连接网络相比,残差连接在没有额外的标准化层时会降低收敛速度。这可能是因为初始化阶段信号的方差并不独立于网络深度。
随着深度的增加,ReZero 架构的优势更加明显。为了验证该架构可用于深度网络训练,研究者在一台配备 GPU 的笔记本电脑上成功训练了多达 1 万层的全连接 ReZero 网络,使其在训练数据集上过拟合。
![]() 图 3:256 宽度和 ReLU 激活的 32 层全连接网络四种变体,在训练过程中的交叉熵损失。
研究者提出,常规的 Transformer 会抑制深层信号传递,他们在输入序列 x 的 n x d 个 entry 的无穷小变化下评估其变化,获得注意力处理的输入-输出 Jacobian,从而验证了之前的观点。
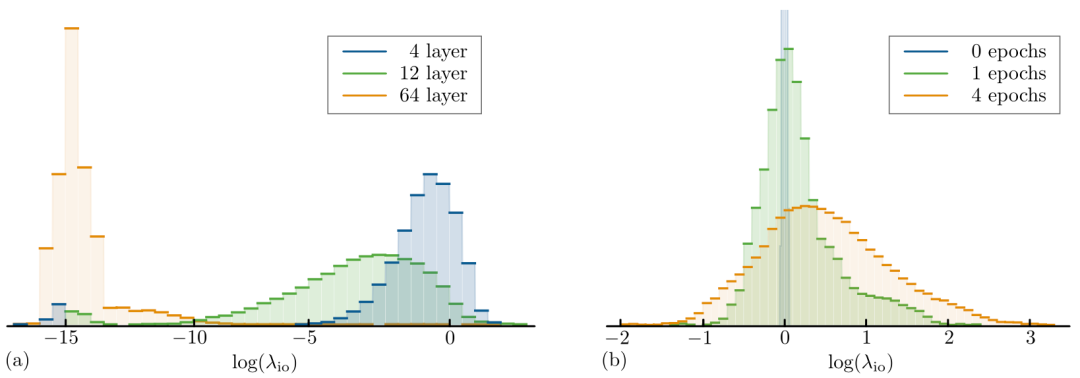
图 5a 展示了不同深度中使用 Xavier 统一初始化权重的 Transformer 编码层的输入-输出 Jacobian 值。浅层的 Transformer 表现出峰值在零点附近的单峰分布,可以发现,深层结构中 Jacobian 出现了大量超出计算精度的峰值。虽然这些分布取决于不同初始化方法,但以上量化的结论在很大范围内是成立的。这些结果与普遍认为的相一致,也就是深层 Transformer 很难训练。
图 5:多个输入-输出 Jacobian 矩阵中对数奇异值λ_io 的直方图。(a)层数分别为 4、12、64 层的 Transformer 编码器网络;(b)是 64 层时训练前和训练中的 ReZero Transformer 编码器网络。深层 Transformer 距离动态等距很远,即λ_io ≪ 1,而 ReZero Transformer 更接近动态等距,平均奇异值 λ_io ≈ 1。
能够在多项 NLP 任务中实现 SOTA 的 Transformer 模型通常是小于 24 层的,这项研究中,最深层模型最多使用了 78 层,并且需要 256 个 GPU 来训练。研究者又将这一模型扩展至数百个 Transformer 层,并且仍然可以在台式机上训练。为了检查该方法是否可以扩展至更深层的 Transformer 模型之上,研究者将 ReZero Transformer 拓展到了 64 及 128 层,并与普通 Transformer 进行了对比。
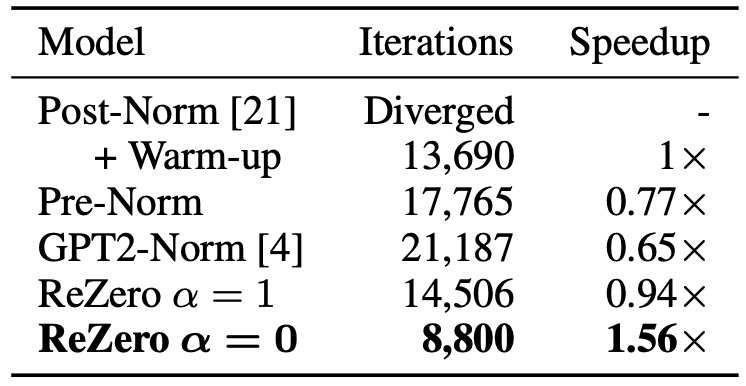
结果显示,收敛之后,12 层的 ReZero Transformer 与常规的 Transformer 取得了相同的 BPB。也就是说,用 ReZero 来替代 LayerNorm 不会失去任何模型表现。训练普通的 Transformer 模型会导致收敛困难或训练缓慢。当达到 64 层时,普通的 Transformer 模型即使用了 warm-up 也无法收敛。ReZero Transformer 在α初始化为 1 时发散,从而支持了α = 0 的初始化理论。深层的 ReZero Transformer 比浅层的 Transformer 表现出了更优越的性能。
表 3:在 enwiki8 测试集上的 Transformers (TX) 对比。
选择 enwiki8 上的语言建模作为基准,因为较难的语言模型是 NLP 任务性能的良好指标。在实验中,其目标是通过测量 12 层的 Transformer 在 enwiki8 上达到 1.2 位每字节(BPB)所需的迭代次数,由此来衡量所提出的每种方法的收敛速度。
表二:针对 ReZero 的 12 层 Transformers 归一化后与 enwiki8 验证集上达到 1.2 BPB 时所需的训练迭代比较。
通过前述部分,看到了 ReZero 的连接是如何使深层网络的训练成为可能的,并且这些深层网络都包含会消失的 Jacobian 奇异值,例如 ReLU 激活或自我注意力。但是,如果没有 ReZero 的连接或者是其他架构的更改,其中某些架构将无法执行训练。在本节中,会将 ReZero 连接应用于深层残差网络从而进行图像识别。
虽然这些网络并不需要 ReZero 连接便可以进行训练,但通过观察发现,在 CIFAR-10 数据集上训练的 ResNet56 model4(最多 200 个 epochs)的验证误差得到了非常明显的提升:从(7.37±0.06)%到(6.46±0.05)%。这一效果是将模型中的所有残差连接转换为 ReZero 连接之后得到的。在实施 ReZero 之后,验证误差降低到 15%以下的次数也减少了(32±14)%。尽管目前这些结果只提供了有限的信息,但它们仍指出了 ReZero 连接拥有更广泛的适用性,从而也推进了进一步的研究。
https://github.com/majumderb/rezero
在此提供了自定义的 ReZero Transformer 层(RZTX),比如以下操作将会创建一个 Transformer 编码器:
图 3:256 宽度和 ReLU 激活的 32 层全连接网络四种变体,在训练过程中的交叉熵损失。
研究者提出,常规的 Transformer 会抑制深层信号传递,他们在输入序列 x 的 n x d 个 entry 的无穷小变化下评估其变化,获得注意力处理的输入-输出 Jacobian,从而验证了之前的观点。
图 5a 展示了不同深度中使用 Xavier 统一初始化权重的 Transformer 编码层的输入-输出 Jacobian 值。浅层的 Transformer 表现出峰值在零点附近的单峰分布,可以发现,深层结构中 Jacobian 出现了大量超出计算精度的峰值。虽然这些分布取决于不同初始化方法,但以上量化的结论在很大范围内是成立的。这些结果与普遍认为的相一致,也就是深层 Transformer 很难训练。
图 5:多个输入-输出 Jacobian 矩阵中对数奇异值λ_io 的直方图。(a)层数分别为 4、12、64 层的 Transformer 编码器网络;(b)是 64 层时训练前和训练中的 ReZero Transformer 编码器网络。深层 Transformer 距离动态等距很远,即λ_io ≪ 1,而 ReZero Transformer 更接近动态等距,平均奇异值 λ_io ≈ 1。
能够在多项 NLP 任务中实现 SOTA 的 Transformer 模型通常是小于 24 层的,这项研究中,最深层模型最多使用了 78 层,并且需要 256 个 GPU 来训练。研究者又将这一模型扩展至数百个 Transformer 层,并且仍然可以在台式机上训练。为了检查该方法是否可以扩展至更深层的 Transformer 模型之上,研究者将 ReZero Transformer 拓展到了 64 及 128 层,并与普通 Transformer 进行了对比。
结果显示,收敛之后,12 层的 ReZero Transformer 与常规的 Transformer 取得了相同的 BPB。也就是说,用 ReZero 来替代 LayerNorm 不会失去任何模型表现。训练普通的 Transformer 模型会导致收敛困难或训练缓慢。当达到 64 层时,普通的 Transformer 模型即使用了 warm-up 也无法收敛。ReZero Transformer 在α初始化为 1 时发散,从而支持了α = 0 的初始化理论。深层的 ReZero Transformer 比浅层的 Transformer 表现出了更优越的性能。
表 3:在 enwiki8 测试集上的 Transformers (TX) 对比。
选择 enwiki8 上的语言建模作为基准,因为较难的语言模型是 NLP 任务性能的良好指标。在实验中,其目标是通过测量 12 层的 Transformer 在 enwiki8 上达到 1.2 位每字节(BPB)所需的迭代次数,由此来衡量所提出的每种方法的收敛速度。
表二:针对 ReZero 的 12 层 Transformers 归一化后与 enwiki8 验证集上达到 1.2 BPB 时所需的训练迭代比较。
通过前述部分,看到了 ReZero 的连接是如何使深层网络的训练成为可能的,并且这些深层网络都包含会消失的 Jacobian 奇异值,例如 ReLU 激活或自我注意力。但是,如果没有 ReZero 的连接或者是其他架构的更改,其中某些架构将无法执行训练。在本节中,会将 ReZero 连接应用于深层残差网络从而进行图像识别。
虽然这些网络并不需要 ReZero 连接便可以进行训练,但通过观察发现,在 CIFAR-10 数据集上训练的 ResNet56 model4(最多 200 个 epochs)的验证误差得到了非常明显的提升:从(7.37±0.06)%到(6.46±0.05)%。这一效果是将模型中的所有残差连接转换为 ReZero 连接之后得到的。在实施 ReZero 之后,验证误差降低到 15%以下的次数也减少了(32±14)%。尽管目前这些结果只提供了有限的信息,但它们仍指出了 ReZero 连接拥有更广泛的适用性,从而也推进了进一步的研究。
https://github.com/majumderb/rezero
在此提供了自定义的 ReZero Transformer 层(RZTX),比如以下操作将会创建一个 Transformer 编码器:
import torchimport torch.nn as nnfrom rezero.transformer import RZTXEncoderLayerencoder_layer = RZTXEncoderLayer(d_model=512, nhead=8)transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=6)src = torch.rand(10, 32, 512)out = transformer_encoder(src)
import torchimport torch.nn as nnfrom rezero.transformer import RZTXDecoderLayerdecoder_layer = RZTXDecoderLayer(d_model=512, nhead=8)transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers=6)memory = torch.rand(10, 32, 512)tgt = torch.rand(20, 32, 512)out = transformer_decoder(tgt, memory)
注意确保 norm 参数保留为 None,以免在 Transformer 中用到 LayerNorm。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content
@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com





 图 3:256 宽度和 ReLU 激活的 32 层全连接网络四种变体,在训练过程中的交叉熵损失。
图 3:256 宽度和 ReLU 激活的 32 层全连接网络四种变体,在训练过程中的交叉熵损失。