文科生也能看懂的机器学习术语解释
点“计算机视觉life”关注,置顶更快接收消息!
本篇文章写给正在入门或者还没入门的同学,高手可以看看权当娱乐,欢迎指正错误。

入门机器学习是不是很多新的概念映入眼帘,什么数据集、测试集、分类、回归、聚类......对于才入门的同学是不是头都大了,这些概念到底是什么意思呢?本文想从一个特殊的角度,能让大家更深刻的对这些概念有个理解。(本文是面试让你手推公式不在害怕的前序,抱歉“强迫症”总要从头开始写才觉得成体系)
一、数据相关名词
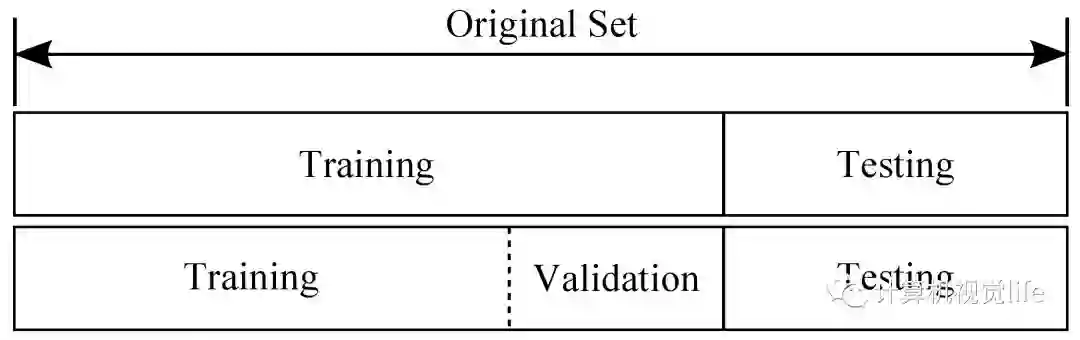
我们从一个比较容易混淆的概念入手,开始解析这些名词。训练集、验证集和测试集这三个名词在机器学习领域极其常见,但很多人并不是特别清楚,尤其是后两个经常被混淆。
训练集(train set) —— 用于模型拟合的数据样本。
验证集(development set)—— 是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。
测试集 —— 用来评估模最终模型的泛化能力。但不能作为调参、选择特征等算法相关的选择的依据。
俗话说一图盛千言,让我们通过一张图简单了解一下。
一个形象的比喻:
训练集-----------学生的课本,也就是我们的课后题,学生根据课本里的内容来掌握知识。
验证集------------模拟考,通过作业可以知道对模拟考的掌握情况怎么样,发现自己薄弱部分。
测试集-----------高考,考的题是平常都没有见过,考察学生举一反三的能力。
数据集-----------课后题,模拟考,高考的总和。
样本-----------所做的每一道题可以看做为一个样本。
标签-----------题的答案可以看做标签。
| 训练集 | 验证集 | 测试集 | 数据集 | |
|---|---|---|---|---|
| 数据 | 课后题 | 模拟考 | 高考 | 课后题+模拟考+高考 |
| 标签 | 答案 | 答案 | 答案 | 答案 |
我们假设我们自己就是机器学习算法,我们并不是家里有矿不需要学习类型,也不是天才型不学就啥都会,要想得高分,上一个名牌学校,走上人生巅峰,迎娶白富美,(呵呵,想多了),怎么办?于是唯一有效的策略就是:努力学习对不对,玩命做题,那我们不能光做,而不知道自己做的对不对,这时候标签登场了也就是我们的课后题答案, 标签就可以理解为正确答案,想想看带标签的训练数据,是不是很像你平时做的课后题呢?

我们学习的过程,也就是训练过程结束了,我们说你学会了东西,但空口无凭啊,你不能去学校门口说我是好学生,你应该要我啊,我上知天文下知地理。呵呵,膨胀了!那怎么证明你学会了呢?你得通过一次考试来证明自己!于是就有了测试集。测试集相当于考试的原因是,你只能看到题目(数据)而无法得知答案(标签)。你只能在交卷之后等老师给你打分(测试过程)。
于是小伙伴可能会想:“那我可以多尝试几次选最高分么?”。如果这场考试要是高考咋办!一年只能考一次,怎么可能允许你无限刷分?你的模型只能在测试集上面跑一次,一考定终身!那咋办,有么有其他方法测验自己平常学的咋样呢?

所以我们需要模拟考,也就是验证集。我们可以获得验证集的标签,但是我们假装得不到,让自己以对付高考的心态去面对,过后也就能通过自己对答案来了解自己到底学会了多少,而这种几乎没有成本的考试我们想进行多少次都行!这就是验证集存在的意义!
我们需要验证集的真正原因是:防止机器学习算法作弊!我们训练一个机器学习模型的最终目标是要将模型应用于真实世界,也就是所说要确保模型的泛化能力。绝大多数情况下,我们无法直接从真实世界获得答案,我们能收集到的数据是没有标签的裸数据,我们需要高效准确的机器学习模型为我们提供答案。不能直接使用测试集不是因为我们负担不起在测试集上跑模型的成本(事实上几乎为0),而是因为我们不能泄露测试集的信息。试想一下,假如你搞到了真正的高考题和答案,你一遍又一遍地去做这套题目,会发生什么?也许你会成为高考状元,可是你真的学会这些知识了吗?你能够再去做一套高考题并且拿高分吗? 所以不能拿训练过的数据去作为评测标准。
我们学习过程所做的所有题,包括我们的课本,作业,试卷的总和就是数据集,其中每一道题就是一个样本。
总结:
tips:为什么要测试集
a)训练集直接参与了模型调参的过程,显然不能用来反映模型真实的能力(防止课本死记硬背的学生拥有最好的成绩,即防止过拟合)。
b)验证集参与了人工调参(超参数)的过程,也不能用来最终评判一个模型(刷题库的学生不能算是学习好的学生)。
c) 所以要通过最终的考试(测试集)来考察一个学(模)生(型)真正的能力(进行高考作为最后测试)。
为什么要验证集:
a)开发模型时总是需要调节模型配置,比如选择层数或每层大小(这叫作模型的超参数)。这个调节过程需要使用模型在验证数据上的性能作为反馈信号。
二、算法相关名词
2.分类、回归、聚类
当机器学习预测的值是离散的,就是分类;值是连续的,就是回归。例如: 做判断题,就有点像二分类,要么是对要么是错的。多分类类似于选择题,有多个选项。至于回归的话,那我们可以把老师给你判卷子看做回归,比如这套卷子得了是71还是72还是100,是一个连续的值。
聚类真的用这个列子不好解释,可以这么想,聚类是在没有标签的情况,也就是你不知道答案是什么。那我们做题有什么意义呢?当然有,假如我们的目标是汇总每一类的题型,就像我们平常所做的笔记总结,我们不用通过答案,也能把一类题型归到一类,这个问题就很有意义了,我们聚类的目的就是把一类题型的题放到一起。
3.监督学习、无监督学习、半监督学习
监督学习:有正确答案的学习。刷题对答案,查看自己做对了没,没对的话,接着调整,接着做,直到大部分都能做对。
无监督学习:没有答案的学习。这就是不给你答案,光让你做,你说这有啥意义,别说,你看英语老师是不是经常说这句话做多了就有语感。
半监督学习:一部分有答案一部分没答案,这才是更贴近真实世界的情况啊,毕竟不是每一本书都有答案啊,对于机器学习一样,现实生活中带标签的数据还是一小部分。
参考文献:
不能更简单通俗的机器学习基础名词解释, filwaline,知乎专栏
机器学习,周志华
相关文章

欢迎关注公众号:计算机视觉life,一起探索计算机视觉新世界~
好文!给个好看啦~





