干货 | 基于贝叶斯推断的分类模型& 机器学习你会遇到的“坑”

本文转载自公众号“读芯术”(ID:AI_Discovery)
本文3153字,建议阅读8分钟。
本文讲解了在学习基于贝叶斯推断的分类模型中,我们需要的准备和方法。
数学准备
概率:事件不确定性程度的量化,概率越大,表示事件发生的可能性越大。
条件概率:P(A|B),在条件B下,发生A的概率。
联合概率:P(A,B),A事件与B事件同时发生的概率。如果因子相互独立,联合概率等于因子概率乘积,即P(A,B)=P(A)P(B)。如果因子独立性不可知,那么有更普遍的形式:P(A,B)=P(B)P(A|B)。
边缘概率:∑AP(A,B)或∫AP(A,B),对联合分布其中一个因子的求和(积分),就得到了另一个因子的边缘概率。
独立同分布:随机变量中每个变量的概率分布相同,且变量之间互相独立。
贝叶斯定理
曾经有一个笑话:有个人坐飞机,带了个炸弹。问他为什么,他说,飞机上有1个炸弹的几率(假设)是万分之一,根据概率论,同时有两个炸弹的概率就是亿分之一,所以我自己带一个炸弹来降低该飞机上有炸弹的概率。
这个笑话之所以好笑,就是因为这个人混淆了联合概率和条件概率,联合概率是指两件事情同时发生的概率,假如说飞机上有一个炸弹的概率是万分之一,那么有两个炸弹的概率就是亿分之一。而条件概率则是指在一件事情在另外一件事情的约束下发生的概率,此人已经携带了一个炸弹,那么飞机上出现第二个炸弹的概率就是条件概率,仍然为万分之一(假设携带炸弹相互独立)。
如果A,B两件事情相互独立,联合概率可以表示为P(AB)=P(A)P(B),我们用P(A|B)来表示给定B条件下A的发生概率,事实上,如果A,B不相互独立,则P(A|B)≠P(A),联合概率就表示为P(AB)=P(B)P(A|B)。
相应的,我们用P(B|A)来表示给定A条件下B的发生概率,联合概率就变成了P(AB)=P(A)P(B|A)。如果我们连接起这两个等式,再分别除以P(B)就会得到一个非常诱人且强大的公式,我们把他叫做贝叶斯定理:
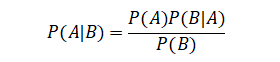
我们会把等式左边的P(A|B)叫做后验概率,等式右边的P(A)叫做先验概率,P(B|A)叫做似然,但后验概率和似然函数在本质上仍然是条件概率。这样的叫法是为了强调贝叶斯定理从结果推原因的过程,也可以理解为一种事件发生之后的概率的修正。
Example:
假设我们现在有两个碗,一个碗里有30个蓝色的小球,10个红色的小球,另一个碗里蓝色小球和红色小球分别有20个,现在的问题并不是你随机挑一个碗从里面拿球,拿到蓝色的概率是多少(因为这太简单了)。我要问的问题是,我拿到了一个蓝球,它更可能来自我随机挑选的第几个碗?
我们把挑选碗的过程叫做事件A1,A2,挑选小球的过程叫做事件B1,B2,分别对应蓝色和红色,我们先求P(A1|B1),将其带入贝叶斯公式,就可以求出后验概率为0.6,我们再求P(A2|B1),代入得后验概率为0.4,说明我们如果选出一个蓝球,这个蓝球更可能来自于第一个碗。
贝叶斯引入的动机
我们在本系列课程的第一篇《过拟合问题》中提到将数据分为训练集和测试集,以及我们做交叉验证的意义。简单来说,分集的目的是为了评估模型的泛化能力,而交叉验证的目的是为了将整个评估过程变得准确。
模型的泛化能力为什么如此重要?因为无论在实验室还是在工业界,真实的数据量太过庞大,而且数据的增长速度越来越快,我们所利用的数据只能被认为是从现实采样而来,我们的模型势必要接触那些从来没在训练集出现过的数据。我们希望模型面对未知数据会有好的预测效果,也就是说,模型势必要对观测上的不确定性做出推断。
我们通常用概率来表示变量的不确定性程度,并且将真实的变量取值当作一个概率分布,机器学习会有视角的转变:
从贝叶斯的框架讨论机器学习,那么问题的目标就变成了:从现有的数据中估计后验概率P(l|x)。比如分类问题,我们对于每一个x,选择能使后验概率最大的类别。
如果我们选取的模型存在有限个参数,可以利用最大似然估计或最大后验估计来给出我们的优化函数。
现在我们主要集中于第一个视角,探讨基于贝叶斯推断的模型。从贝叶斯定理可以看出,我们对后验概率的计算要通过似然和先验概率,这样的模型叫做生成式模型。而譬如logistic regression,是直接对后验概率进行估计,没有用到贝叶斯定理,这样的模型叫做判别式模型。
基于贝叶斯推断的分类方法
我们现在考虑典型的机器学习的二分类问题,我们每一个训练样本都有若干的特征(feature)和确定的标签(label),我们的测试样本只有特征,没有标签。所以从贝叶斯推断的角度来看,我们需要寻找的是一个最大化的条件概率(后验概率)P(l|X),我们可以将其理解为,在已知样本X的前提下,最大化它来自类别l的概率。也可以理解为:对于每一个样本X,我们选择能够使后验概率最大的类别l。
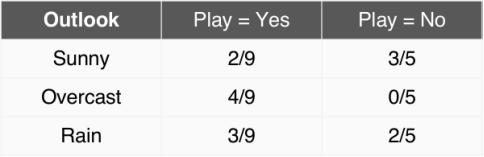
假如我们面临的问题是,根据天气、温度、湿度和风力4个特征来预测要不要去打网球,我们训练样本如下图所示:
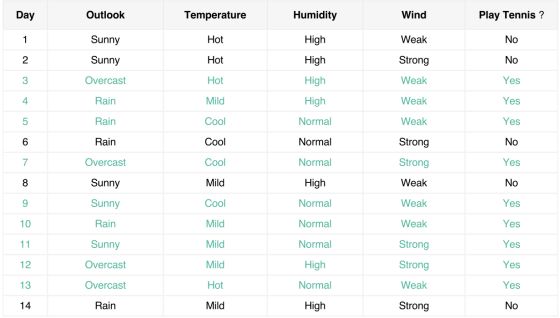
可以看出,类别l只有Yes和No两种情况。如果我们的测试样本X为(天气=Sunny,温度=Cool,湿度=high,风力=Strong),我们要分别计算出P(l=Yes|X)和P(l=No|X),然后比较大小,然后将概率大的那一方所选择的类别当作我们预测的结果。
我们接下来的问题是,如何计算后验概率P(l=Yes|X)和P(l=No|X)。我们将其带入贝叶斯公式:
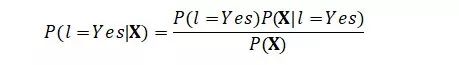
其中,P(l=Yes)很好理解,就是标记为Yes的样本占全部样本的比例,我们也把它叫做类先验(prior)概率,根据大数定律,我们可以根据出现的频率来估计概率,这也是我们要从训练样本中获取的信息。
P(X)则是用于归一化的证据(evidence)因子,也是X出现的概率。我们可以考虑,对于类别为No的后验概率:
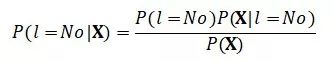
可以看出,P(X)是相同的,所以当我们比较两者大小时,这一项与计算无关。
P(X|l=Yes)是条件概率,是指在标记Yes的样本中具有特征X的样本所占的比例,我们也把它叫做似然(likelihood),这也是我们要从训练样本中获取的信息.真正的问题在于,如果我们真的将X本身作为一个事件,那么很有可能我们的测试样本概率为零,而未被观测到并不等于概率为零。
朴素贝叶斯(Naive Bayes)
我们注意到X是个向量,它包含了每个特征的取值,于是我们可以将P(X|l=Yes)视为各个特征取值的条件概率下的联合概率,如果我们继续假设特征之间互相独立,那么联合概率就变得非常容易计算:
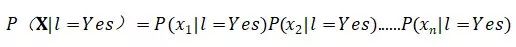
朴素贝叶斯中,朴素(naive)的含义正是如此,它采用了属性条件独立性假设(attribute conditional independence assumption),让似然变得简单可计算。
让我们先来总结一下上面那幅图,分别计算各个属性的条件概率:



所以,就有:
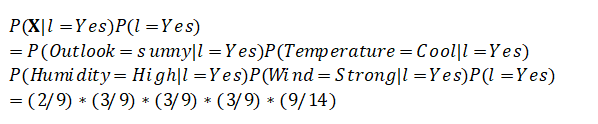
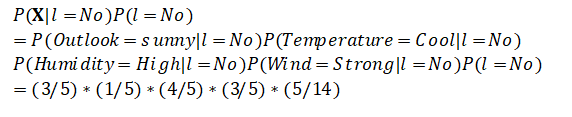
计算结果发现,将这个样本归结于Yes的后验概率大约为0.0053,归结于No的后验概率大约为0.0206,No的后验概率远远大于Yes的后验概率,也就是说,对于这样一个样本,我们的预测结果会是——不要去打网球。
除了朴素贝叶斯这样一种基于贝叶斯推断的分类模型,面对机器学习的回归问题,我们是否也有基于贝叶斯推断的模型?甚至我们还可以问,贝叶斯只是应用于模型之中吗?那么,我们的下一篇将会为大家介绍贝叶斯推断的回归模型。
课堂TIPS
广义来看,贝叶斯分类器是生成式模型的一种(generative models)。朴素贝叶斯是贝叶斯分类最简单的形式,因为它假设了属性的条件概率互相独立,使得计算后验概率简单可行。
我们文中所举的例子是离散属性,所以概率的形式均为概率质量函数(PMF),我们可以将其推广到连续属性,只需要将概率的形式换为概率密度函数(PDF),但本质并不会发生改变。
我们在用朴素贝叶斯方法时,需要计算多个属性的条件概率下的联合概率。但如果我们的样本多样性不够丰富,很可能会出现我们的测试样本中的某些属性值并未在训练样本的某个类中出现,如果直接求解,则会造成概率为零的后果。面对这样的情形,我们会在计算先验概率的时候,引入拉普拉斯修正,强行使未出现的属性条件概率不为零。
我们在使用贝叶斯分类器做训练时,实际上是在训练先验概率P(l)和似然P(X|l)。我们可以为了预测准确度,不断地将新增样本的属性所涉及的概率估计进行修正;我们也可以为了预测速度,将所有的P(X|l)和P(l)预先计算好,遇到测试样本时直接查表判别。
-
朴素贝叶斯所依赖的属性条件独立性不一定成立,所以还有半朴素贝叶斯分类器(semi-naive),它假设每个属性存在一定的依赖,适当考虑一部分的属性依赖。(可以看这篇论文: Semi-naive Bayesian classifier)







