加入Transformer-XL,这个PyTorch包能调用各种NLP预训练模型
机器之心报道
参与:思源、路
作为预训练模型,BERT 目前常充当系统的重要模块,并衍生出大量 NLP 项目。但是 BERT 官方实现基于 TensorFLow 框架,因此那些借助 PyTorch 实现的 NLP 系统可能并不方便嵌入它。为此,开发者从每一个 OP 开始重新用 PyTorch 预训练 BERT 等模型。这个项目不仅提供预训练 BERT、GPT 和 Transformer-XL 模型,同时还提供对应的微调示例和代码。
PT-BERT 项目地址:https://github.com/huggingface/pytorch-pretrained-BERT
短短两个多月以来,该项目已经获得了 3 千多的收藏量,而这两天发布的 0.5 版本更是收录了由谷歌和 CMU 最新提出的 Transformer-XL 模型。
在 0.5 版本的更新中,它主要提供了两个新的预训练模型,即在 Toronto Book Corpus 上预训练的 Open AI GPT 模型和在 WikiText 103 上预训练的 Transformer-XL 模型。其中 Open AI GPT 模型主要修正了分词和位置嵌入编码,从而提升预训练的性能;Transformer-XL 模型主要是针对 TensorFlow 官方实现的复现,且对相对位置编码等模块做一些修改。
这次更新比较重要的就是 Transformer-XL 预训练模型,它是对 Transformer 及语言建模的修正,这项前沿研究也是上个月才公布。一般而言,Transformer-XL 学习到的长期依赖性比标准 Transformer 学到的长 450%,无论在长序列还是短序列中都得到了更好的结果,而且在评估时比标准 Transformer 快 1800 多倍。
除了预训练模型的发布,0.5 发行版还更新了一些脚本和微调示例,例如更新 SQuAD 微调脚本以适应 SQuAD V2.0 数据集。现在让我们看看 0.5 版如何快速导入 Open AI GPT 和 Transformer-XL 模型,并预测一句话缺失的下一个词吧:
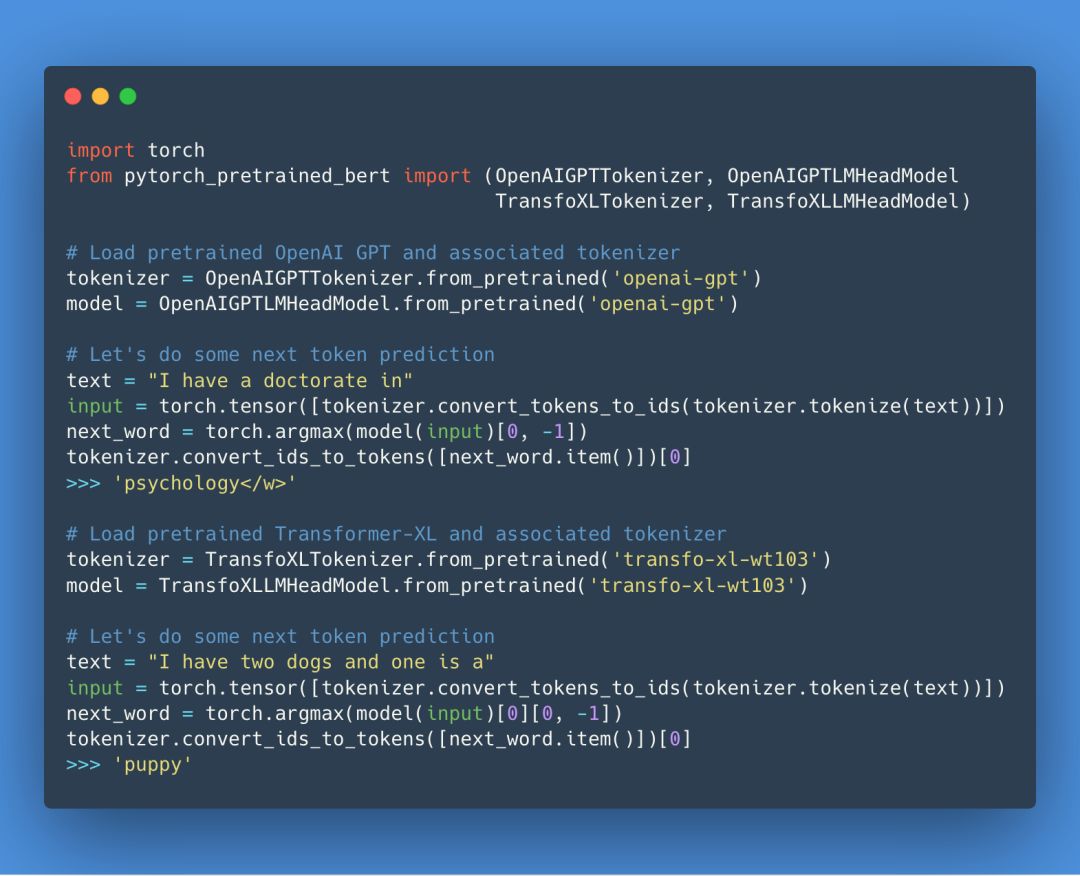
PT-BERT
上面简单介绍了什么是 PT-BERT 即最新的 0.5 版,那么这个项目到底有什么特点呢?目前项目一共包含三大类预训练模型,它们的实现均已在多个数据集上进行测试(详见示例),性能堪比对应的 TensorFlow 实现。
以下是三大类预训练模型的信息详情:
BERT 是在论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》中提出的。该 PyTorch 实现包括谷歌的预训练模型(https://github.com/google-research/bert)、示例、notebook,以及命令行接口,允许加载 BERT 的任意预训练 TensorFlow 检查点。
OpenAI GPT 是在论文《Improving Language Understanding by Generative Pre-Training》中提出的。该 PyTorch 实现是对 HuggingFace 的 PyTorch 实现进行改进后得到的,包括 OpenAI 的预训练模型(https://github.com/openai/finetune-transformer-lm)和命令行接口,可将预训练 NumPy 检查点转换为 PyTorch。
Google/CMU 提出的 Transformer-XL 是在论文《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》中提出的。该 PyTorch 实现是对原版 PyTorch 实现的改进版本,以获得与 TensforFlow 版本相匹配的性能,并允许复用预训练权重。该实现提供命令行接口,以将 TensorFlow 检查点转换为 PyTorch 模型。
以上所有预训练模型都可以直接通过软件库调用,使用方法就和前面图片那样简单便捷。整个包体的安装也可以直接使用命令行 pip install pytorch-pretrained-bert 完成。目前该软件包含以下模型与模块,它们均可被导入 Python 中。
8 个具备预训练权重的 Bert PyTorch 模型:包括原版 BERT Transformer 模型(完全预训练)、执行下一句预测分类的 BERT Transformer 模型(完全预训练)、实现序列分类的 BERT Transformer 模型、实现 token 分类的 BERT Transformer 模型等。
3 个具备预训练权重的 OpenAI GPT PyTorch 模型:原版 OpenAI GPT Transformer 模型(完全预训练)、实现捆绑语言建模的 OpenAI GPT Transformer 模型(完全预训练)、实现多类别分类的 OpenAI GPT Transformer 模型。
2 个具备预训练权重的 Transformer-XL PyTorch 模型:Transformer-XL 模型,输出最后一个隐藏状态和记忆单元(完全预训练)、具备 tied adaptive softmax head 的 Transformer-XL 模型,输出 logits/loss 和记忆单元(完全预训练)。
3 种 BERT 分词器:基础分词、WordPiece 分词、端到端分词。
OpenAI GPT 分词器:执行 Byte-Pair-Encoding (BPE) 分词。
Transformer-XL 分词器
BERT 优化器:Adam 算法的 BERT 版本。
OpenAI GPT 优化器:Adam 算法的 OpenAI GPT 版本。
此外,该库还包括 5 个 BERT 使用示例、1 个 OpenAI GPT 使用示例、1 个 Transformer-XL 使用示例、3 个用于检查 TensorFlow 和 PyTorch 模型是否行为一致的 notebook,以及将 TensorFlow 检查点(BERT、Transformer-XL)和 NumPy 检查点(OpenAI)转换成 PyTorch 的命令行接口。

本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




