BERT、GPT-2这些顶尖工具到底该怎么用到我的模型里?

新智元推荐
新智元推荐
来源:专知(ID:Quan_Zhuanzhi)
整理编辑:三石
【新智元导读】NLP方向近日各种大神工具层出不穷。然而,实践才是硬道理,如何将它们应用到自己的模型是个关键问题。本文就对此问题进行了介绍。
近期的NLP方向,ELMO、GPT、BERT、Transformer-XL、GPT-2,各种预训练语言模型层出不穷,这些模型在各种NLP任务上一次又一次刷新上线,令人心驰神往。但是当小编翻开他们的paper,每一个上面都写着四个大字:“弱者退散”,到底该怎么将这些顶尖工具用到我的模型里呢?答案是Hugging Face的大神们开源的pytorch-pretrained-BERT。
Github 地址:
https://github.com/huggingface/pytorch-pretrained-BERT
近期的各种预训练语言模型,横扫各种NLP任务,这里我们介绍三个最火的预训练模型:
BERT,由Google AI团队,发表于2018年10月11日。它的文章是: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding。
Transformer-XL, 由Google AI和Carnegie Mellon大学,发表于2019年1月9日。它的文章是:Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context。
GPT-2,由OpenAI 团队,发表于2019年2月14日,它的文章是:Language Models are Unsupervised Multitask Learners。
基本上,每一个文章,都在发表的时候,刷新当时的几乎所有NLP任务的State-of-the-Art,然后引发一波热潮。 当然,目前风头正盛的是GPT-2,它前几天刚发表。
然而,让小编翻开他们的paper,发现每一个上面都写着四个大字:“弱者退散”,到底该怎么将这些顶尖工具用到我的模型里呢,Hugging Face 的大神们,紧跟前沿,将所有的预训练语言模型都实现并开源了。更令人钦佩的是,它们还做了很多封装,让大家都可以才在这些巨人模型的肩膀上。
Hugging Face开源的库叫pytorch-pretained-bert, 你可以在本文开头找到链接。接下来的部分,我们介绍一下它的安装和使用。
你可以直接使用 Pip install 来安装它:
pip install pytorch-pretrained-bert
pytorch-pretrained-bert 内 BERT,GPT,Transformer-XL,GPT-2。
为了获取一句话的BERT表示,我们可以:


拿到表示之后,我们可以在后面,接上自己的模型,比如NER。
我们也可以获取GPT的表示:
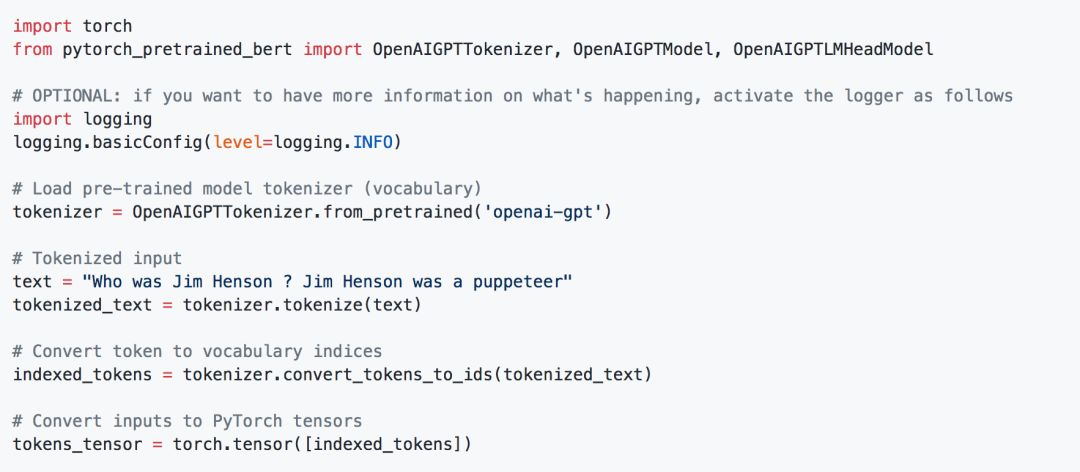

Transformer-XL表示:
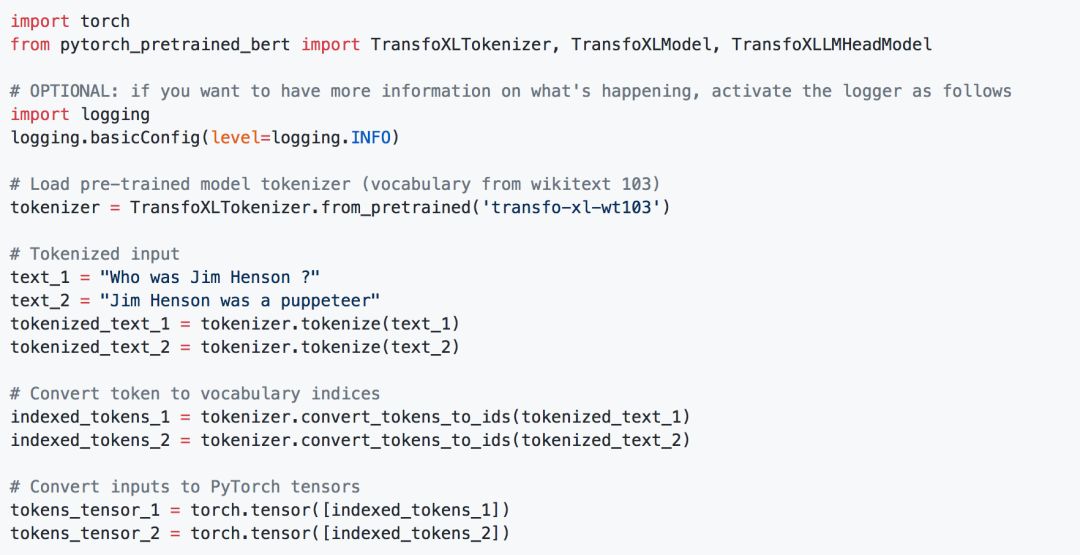

以及,非常火的,GPT-2的表示:
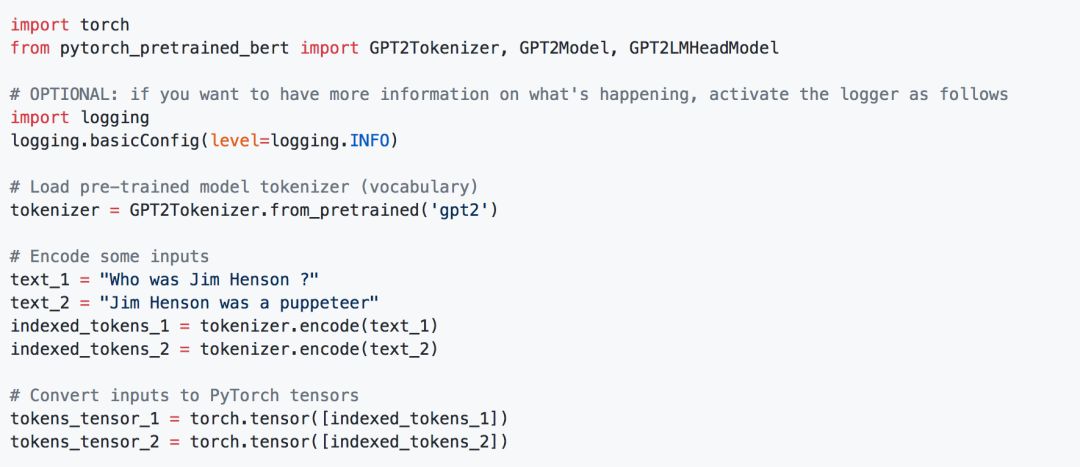

有了这些表示,我们可以在后面,接入自己的模型,比如:
文本分类
https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/examples/run_classifier.py
阅读理解
https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/examples/run_squad.py
语言模型
https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/examples/run_lm_finetuning.py
等等
本文经授权转载自专知,点击阅读原文查看原文
更多阅读
【加入社群】
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。



