【巨头升级寡头】AI产业数据称王,GAN和迁移学习能否突围BAT垄断?
1 新智元原创
作者:张易
【新智元导读】AI时代,数据为王让巨头越来越难以被打败。谷歌和 CMU 的10亿+数据集的设想,似乎又将这一假设往前推进了一步。数据为王还是算法为王,这是人工智能时代一直争论不休的话题。近年来,对抗生成网络、迁移学习等新技术不断涌现,让人看到小数据突围的曙光,这些技术会为初创公司带来一线生机吗?作为国内互联网数据的井喷之地,BAT 对算法和数据又持有哪些观点?他们的数据布局是怎样的?

上周,谷歌和 CMU 的一项合作研究,为拥有大数据优势的技术巨头们带来了喜讯:在不调整现有算法、只是给模型多得多的数据的情况下,图像识别结果取得了较大提升。
这一波人工智能的兴起主要有三大因素推动——计算力、数据和算法。而谷歌和 CMU 的这项合作研究可能会将“数据”这一项进一步高亮显示。
据 Wired 报道,研究结果一方面印证了通过给模型喂食多得多的数据,同样的算法也能显著提升性能,另一方面,这也是对拥有海量数据的技术巨头的喜讯。无论是谷歌、Facebook 还是微软,都会更加坚信自己手中的数据是决胜的王牌。虽然从 1 百万扩充到 3 百万数据集,对象检测的结果只提高了 3 个百分点,但研究者表示,他们相信如果对软件进行调整,使其更适应于超大数据集,那么优势还将扩大。退一万步说,即使没有扩大,这 3 个百分点也足以形成和小公司、初创公司的天堑。举例来说,在自动驾驶中,准确率的每一点点提升都至关重要,有可能带来数以亿计的回报。
以 AI 为中心的公司,早就建立了自己的数据壁垒。谷歌、微软等巨头,会开源大量软件,甚至硬件设计,但对能这些工具真正发挥效用的数据却视若珍宝,绝不轻易开放。他们有时确实也会释放数据:去年,谷歌放出了从 7 百万 YouTube 视频中提取的数据集,Salesforce 也开源了从维基百科抽取的数据集,以帮助算法更好地处理自然语言。
然而正如 Luke de Oliveira (AI development lab Manifold 合伙人、Lawrence Berkeley National Lab 的访问学者)所说:“这种开放对竞争来说没什么价值。这些数据集都是对该公司产品的未来市场地位没什么影响的东西。”

在不久前的百度开发者大会上,百度公布了“Apollo 资源共享时间表”。其中各种细化数据非常有吸引力。
巨头笼罩下,小数据学习会为初创公司带来一线生机吗?
有人说科技公司的生态越来越讲求创新和快速反应,这似乎对小公司、初创公司更为有利。但机器学习和 AI 浪潮却彻底地凸显了大数据的重要性,仅此一点,就让小公司“杀死”巨头的任务难上加难。
谷歌和 CMU 的研究者在论文中表示:“我们真诚的希望,(他们的研究)将激发视觉界不要低估数据的价值,并形成共同的努力来构建更大的数据集。”研究的参与者之一、CMU 的 Abhinav Gupta 表示,选择之一就是和 Common Visual Data Foundation 合作。而这个 Foundation 正是由曾发布过公开图像数据集的 Facebook 和微软资助的非盈利组织。
在数据方面拙荆见肘的公司,如果想在这个数据比金子还贵的时代生存,只能盼着自己的算法更聪明。初创公司 DataRobot 的 CEO JeremyAchin 猜测,随着机器学习变得日益流行,小公司利用小数据做出的模型,比如保险业中用于风险预测的模型,在大公司用大数据打造的模型前可能会抵挡不住。
有一种研发趋势,是在让机器学习较少地依赖数据,比如小数据学习。这一类研究会阻挡 AI 的数据经济吗?Uber 去年曾收购了一家公司,就是以此为研发方向。
针对数据量匮乏的问题,有一项技术非常有价值:生成对抗网络(Generative Adversarial Networks,简称GAN)。
生成对抗网络依赖于两个模型:
生成模型(Generative Model),即借助于学习、模拟、仿照、以及数据扩增等技术自动生成数据的模型;
判别模型(discriminative model),即判别生成数据是否符合预期的模型。
生成对抗网络首先会基于生成模型来生成数据样本,再用判别模型来鉴别这个自动生成的样本是否符合预期。通过这样的双方对抗网络,实现互相博弈,共同提升。
另一种思路是迁移学习。迁移学习基于标签数据量大的领域,做特征、参数权重的预训练(pre-train),再通过迁移当前领域可复用的特征、参数、或者是领域知识、通用知识,对目标领域进行半监督、无监督学习。
Fast.ai 的联合创始人 Rachel Thomas 认为,初创公司应该努力开拓新的疆域,在互联网巨头的地盘以外寻找应用机器学习的场景,比如农业。她表示:“即使是巨头也不是无处不在,在很多特定领域,数据还没有被任何人收集过。”即使是巨人也有盲点,这也许才是小公司的机会。
在中国国内市场,BAT 垄断了大部分的数据。关于算法重要还是数据重要,他们的看法如何?
李彦宏曾在重庆举行的联盟峰会上说过:我们百度的工程师总结出来一句话,叫‘数据秒杀算法’,但是我后来跟他们讲,真正推动社会进步的是算法,而不是数据。

在之后的数博会上,李彦宏再次表达过类似的意思:工业时代最宝贵的东西不是煤,是蒸汽机这样的技术革命、革新,而人工智能时代最宝贵的也不是数据,是因为数据带来的技术的创新。
让我们简单看一下百度大数据的“家底”,其实用两个短语就可以概括:万亿级搜索数据,百亿级定位数据。
试以语音相关的数据为例。作为百度 ALL IN AI 的两大发力方向之一(自动驾驶和智能语音),百度如此展示自己在相关数据上的肌肉:

网上流传一句话,说百度是“数据为重,不为上。” 作为很可能是 BAT 三家中数据量最大的公司,百度的优势在于数据最全面,数据样本比较复杂,数据的广度和多样性上比较强。而问题在于,百度的数据,较之阿里和腾讯,其变现能力可能是最弱的。
作为一家技术驱动的公司,百度在数据挖掘技术和 AI 人才的储备上优势明显,但其优势的应用出口较少。也正是在这种背景下,李彦宏在数博会上发言:我觉得这个数据确实重要,没有数据训练的话人工智能走不到今天的,但是数据是不是根本呢?数据不是根本,数据有点像新时代的能源,像燃料,那么推动时代进步的是技术,是创新,不是这些资源......所以工业时代最宝贵的东西不是煤,是蒸汽机这样的技术革命、革新,而人工智能时代最宝贵的也不是数据,是因为数据带来的技术的创新。而且过去一年就有这么多的创新,有大幅度的提升,连我在这个领域的人都要觉得要改变心态,适应这种环境,适应各种各样的可能性。
阿里的大数据是基于淘宝天猫业务而诞生的电商数据、信用数据。阿里的核心业务在电子商务上,数据比较聚集,更容易做分析。这种数据类型的优势在于,更容易变现,挖掘出商业价值。正如马云在数博会上所说:“我们对世界的认识将会提升到一个新的高度,大数据会让市场变得更加聪明。”
而腾讯的大数据是基于微信、QQ 诞生的社交数据、关系数据,以及游戏数据,相对较杂,但场景化极高。很自然的,马化腾在数博会上强调了场景的意义:“有了应用场景,有了市场,数据自然会产生,也会驱动技术发展。”“就好像今天BAT三家分别在社交、电商和搜索有各自的主战场和场景;滴滴、摩拜有交通出行的场景;微信、支付宝有支付场景。”腾讯的大数据是其自身各类产品(尤其是游戏)成功的坚实基础。
对于场景化的数据,我们还很容易想到滴滴出行和小米,它们分别在各自的场景中收集并利用其数据优势。
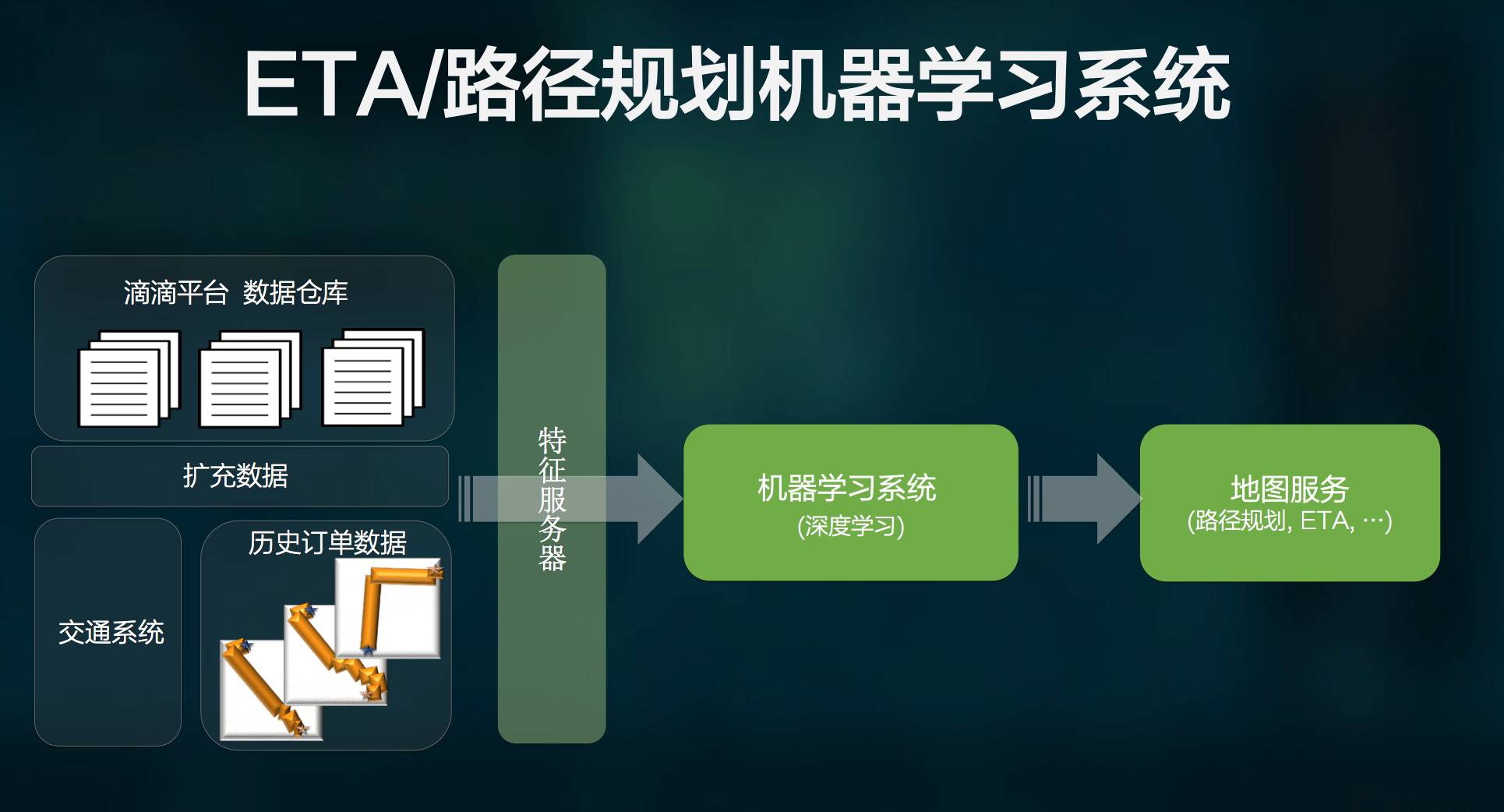
滴滴出行基于大数据的路径规划系统
滴滴研究院副院长叶杰平曾在北大 AI 公开课上透露:下面说一下我们的大数据......我们每天大概2000万单,平台的每一辆在开着的车,每几秒钟就会给我们传递 GPS 信息。现在滴滴每天新增的数据量是 70TB,这个数据应该是几个月之前的,现在应该更大了。我们平台在做很多的预测和模型,每天处理的数据是2000TB。每天的路径规划是 90亿,这个数据量特别大。然后是定位数据,我们必须要知道乘客在哪,司机在哪,所以定位是非常重要的,这个数据不光要精确,而且要快速。定位数据每天是 130亿.....”

小米科技联合创始人黄江吉在北大 AI 公开课上也曾透露:“小米全部产品加起来,每天产生的数据量一天是300T。为了存储这个300T,每天我们付出的存储成本是天文数字。为什么我们要存储大量昂贵的数据?其实我们等 AI 这个弯道已经等了很久,终于在去年迎来爆发点。现在,我们有可能利用最前沿的技术,比如深度学习、对抗性网络来取得进一步发展。现在技术发展是以周计算。这对于我们都是好消息。因为技术发展到这个点的时候,我们已经准备了很多大数据。这些技术可以用来验证算法是否靠谱,可以把我们的产品变得更智能化,真正实现闭环。大数据其实讲了很多年。我刚进入微软的第二年,就开始做data warehouse,当时已经存了海量数据,都觉得大数据很有价值......我们对于数据增长很开心,并不在意成本。"
从这个角度来说,大数据对 AI 的赋能,确实是从应用场景中来,到应用场景中去的。
10亿+数据集,谷歌的大数据野心
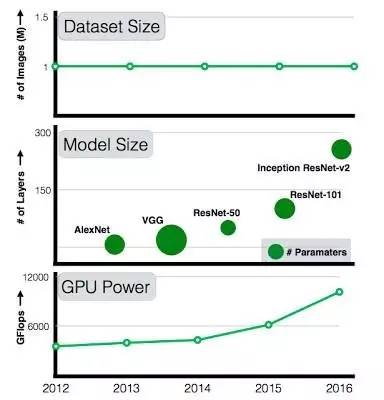
过去十年中,在计算机视觉领域,虽然计算力(GPU)和模型大小不断增长,数据集的规模一直停步不前。
这项研究(【10亿+数据集,ImageNet千倍】深度学习未来,谷歌认数据为王),用了 50 颗 K80 GPU(计算等于 8.3 GPU 年),花了整整两个月,在 300M 标记图像的海量数据集上进行图像识别训练。这个名叫“JFT-300M”的内部数据集,含有 18291 个类别,是 ImageNet 的 300 倍。这一研究项目的初衷是看在不调整现有算法、只是给模型多得多的数据的情况下,能否取得更好的图像识别结果。
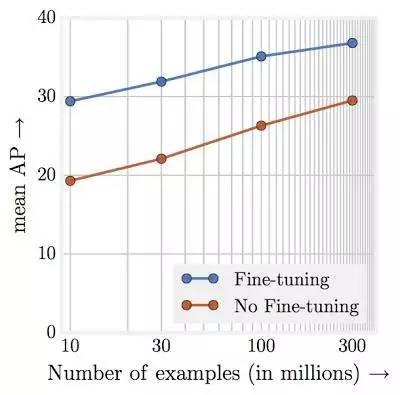
在 JFT-300M 不同子集上的预训练后,进行物体检测的性能。x 轴表示对数刻度的数据集大小,y 轴是 COCO-minival 子集中 mAP@[0.5,0.95]中的检测性能。
答案是可以。研究人员发现,随着数据增长,模型完成计算机视觉任务的性能直线上升。即使在 300 倍 ImageNet 这么大规模的情况下,性能都没有遭遇平台。谷歌研究人员表示,构建超大规模的数据集应当成为未来研究的重点,他们的目标是朝 10 亿+ 级别的数据进发。



