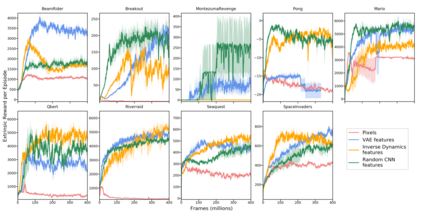
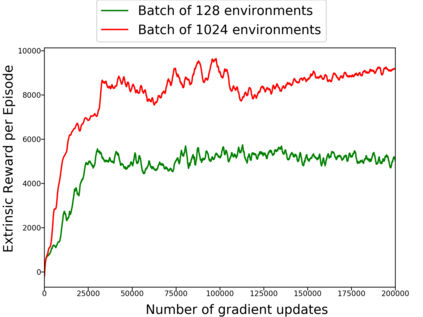
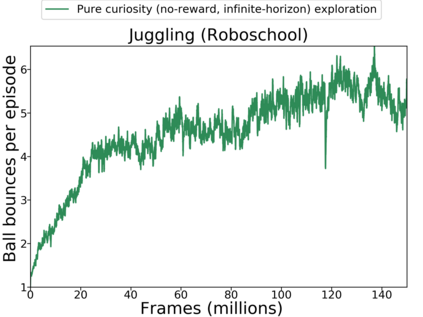
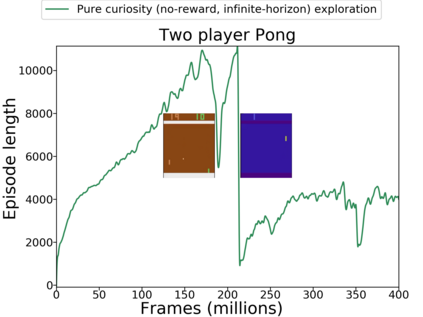
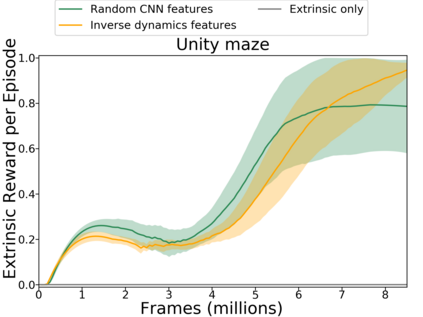
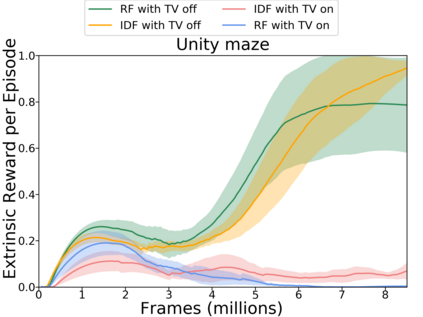
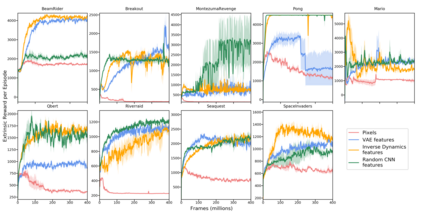
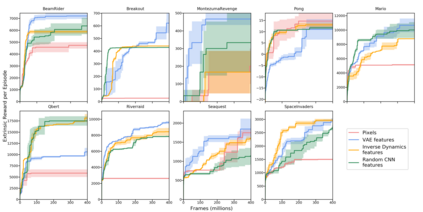
Reinforcement learning algorithms rely on carefully engineering environment rewards that are extrinsic to the agent. However, annotating each environment with hand-designed, dense rewards is not scalable, motivating the need for developing reward functions that are intrinsic to the agent. Curiosity is a type of intrinsic reward function which uses prediction error as reward signal. In this paper: (a) We perform the first large-scale study of purely curiosity-driven learning, i.e. without any extrinsic rewards, across 54 standard benchmark environments, including the Atari game suite. Our results show surprisingly good performance, and a high degree of alignment between the intrinsic curiosity objective and the hand-designed extrinsic rewards of many game environments. (b) We investigate the effect of using different feature spaces for computing prediction error and show that random features are sufficient for many popular RL game benchmarks, but learned features appear to generalize better (e.g. to novel game levels in Super Mario Bros.). (c) We demonstrate limitations of the prediction-based rewards in stochastic setups. Game-play videos and code are at https://pathak22.github.io/large-scale-curiosity/
翻译:强化学习算法依赖于对代理商来说属于外部性质的仔细工程环境奖励。 但是,用手工设计、密集的奖励来说明每个环境是无法伸缩的,因此需要开发代理商固有的奖赏功能。 好奇度是一种内在的奖赏功能,使用预测错误作为奖赏信号。 在本文中:(a) 我们对包括Atari游戏套件在内的54个标准基准环境进行首次大规模研究,对纯粹由好奇心驱动的学习进行大规模研究,即没有任何外观奖赏。我们的结果显示,内在好奇心目标与许多游戏环境的手工设计的外观奖赏之间表现得令人惊讶,而且高度一致。 (b) 我们调查使用不同功能空间计算预测错误的效果,并表明随机性功能对于许多流行的RL游戏基准已经足够,但学到的特征似乎比较概括化(例如,SupiMario Bros的新游戏级别)。 (c) 我们显示了基于预测的奖赏在随机配置中存在局限性。 游戏游戏视频视频和代码在 https://pathak-curity22. butios/masteralitycality.