李飞飞团队最新研究:识别真实场景中物体表面纹理!
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
现在,细微到物体表面的纹理,AI都可以识别。
这就是李飞飞团队新研究。
我们知道,卷积神经网络在识别视觉对象方面很出色,但还不能很好的识别出物体的具体属性,比如表面形状、纹理等。
而最近,李飞飞团队的最新研究——Learning Physical Graph Representations from Visual Scenes,就一举解决了这个问题。

还引入了物理场景图(Physical Scene Graphs,PSG)和对应的PSGNet网络架构。
PSG的概念概括了MONet/IODINE和3D-RelNet的工作思路,力求能够在几何上处理复杂的物体形状和纹理。
这样,在真实世界的视觉数据中学习,可以做到自监督,因而不需要大量和繁琐的场景组件标记。
具体研究是如何呢?我们一起来看看吧!
PSGNet的建构
简单来说,用一张图就可以表示。
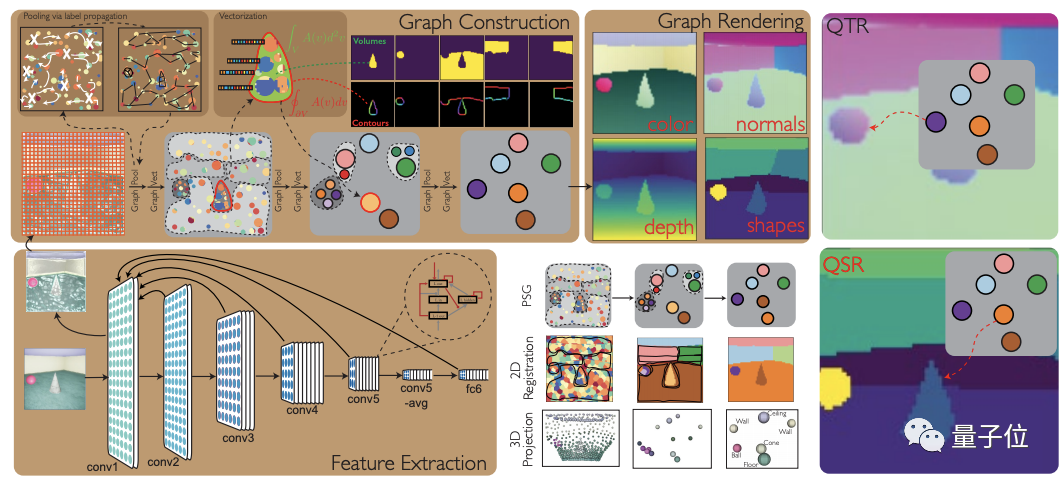
棕色方框表示PSGNet的三个阶段。
首先,特征提取。采用ConvRNN从输入中提取特征。
然后,构建图形,负责优化现有PSG级别。
最后,用于端到端训练的图形渲染。
其中,在构建图形这一阶段,由一对可学习的模块组成,即池化和向量化。
前者在现有图节点上动态的构建一个池化核的分区,作为学习的、成对的节点 affinities函数。
后者在与每个池化核相关联的图像区域及其边界上,聚合节点统计,来产生新节点的属性向量。这样便可以直观的表示出真实场景中的物体属性。
在「图形渲染阶段」,PSG相当于通过一个解码器。
在每个时间点将图节点属性,以及图节点顶层空间配准(SR),渲染成RGB、深度、段和RGB变化图z。
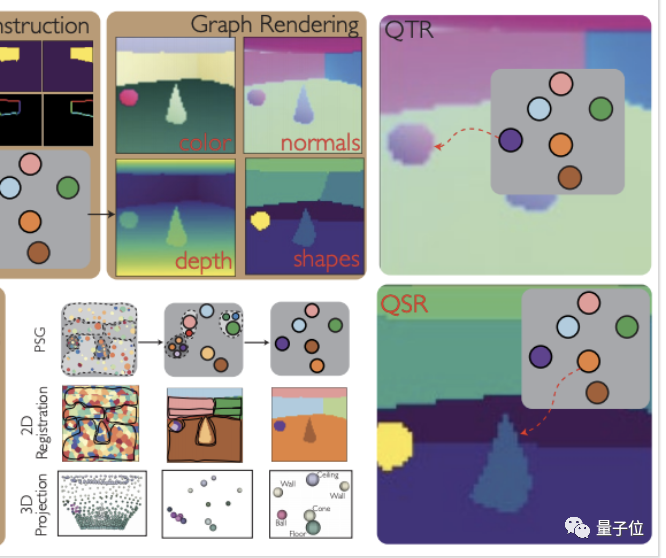
举个例子,除开棕色方框部分,就是一个PSG的三个层次以及与其纹理(QTR)和形状(QSR)渲染图。
实验结果
随后,将模型在 TDW-Primitives、TDW-Playroom 和 Gibson 测试集上训练,并与最近基于CNN场景分割方法进行性能比较。
首先说一说这三个数据集,为什么要选择这三个数据集呢?
Primitives和Playroom中的图像由ThreeDWorld (TDW)生成。其中,Primitives是在一个简单的3D房间中渲染的原始形状(如球体、圆锥体和立方体)的合成数据集。
Playroom是具有复杂形状和逼真纹理的物体的合成数据集,如动物、家具和工具,渲染为具有物体运动和碰撞的图形。
Gibson则是由斯坦福大学校园内部建筑物的RBG-D扫描组成。
这三个数据集都提供了用于模型监督的RGB、深度和表面法线图。
性能的比较结果如下:
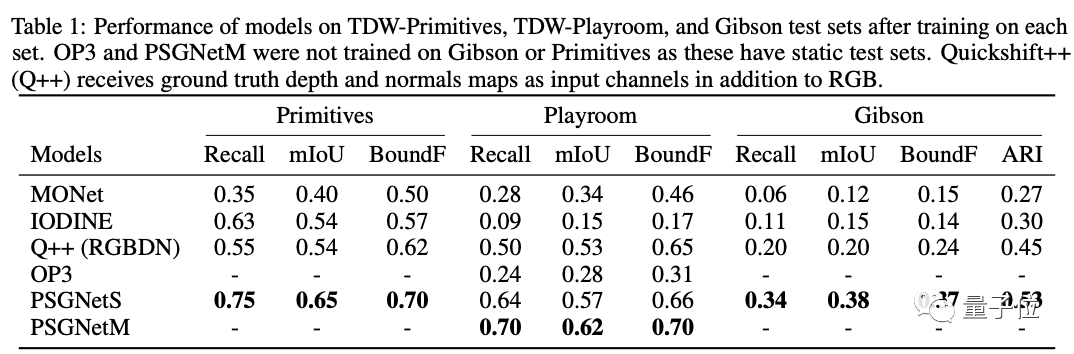
注意的是,OP3和PSGNetM没有在Gibson或Primitives上进行训练,因为它们有静态测试集。
可以看到与其他模型相比,PSGNet表现出了更优的性能。
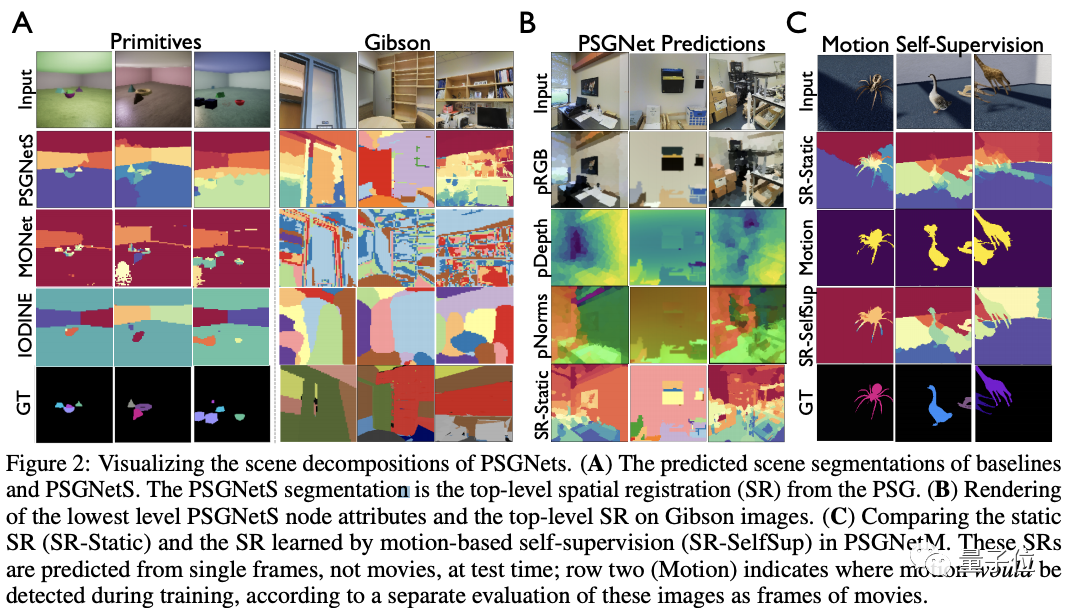
△PSGNets的场景分解
此外,文中还通过「手动编辑」PSG顶层的节点,观察其渲染效果,来说明PSG能够正确的将场景表示为离散的对象及其属性。
就像这样。

从图中删除一个节点(DeleteA或者B),将它们移动到新的3D位置(MoveB和Occlude),改变形状属性(Scale/Rot),或者交换两个节点的颜色(Swap RGB)。
结果,发现都会改变相对于原始(Full)预测的图形渲染。
研究团队
这篇论文的研究团队是由斯坦福大学和麻省理工大学多个团队共同合作完成的,其中就包括李飞飞团队和来自MIT CSAIL的团队。
第一作者名叫Daniel Bear,心理学系博士后研究员,来自斯坦福大学吴蔡神经科学研究所。

你可能想问,为何研究脑科学的会跟李飞飞团队一起合作呢?
看了这位作者的研究方向你就知道了。
他一直都在致力于研究动物是如何感知世界。
从一开始哈佛大学本科期间,就主要研究动物电信号,比如来自感官刺激的信号,如何诱导神经元基因表达。
接着在哈佛大学继续攻读博士时,就研究化学信号,比如动物遇到的气味分子,如何转化为嗅觉感知。
而现在博士后研究期间,他就把目光转向了采用计算模型来表示动物大脑中的表征。如果可以,给他进一步的研究提供了思路。
于是,他们就这样交织在了一起。
吴蔡神经科学研究所
也许有朋友会对这个研究所的名字有点陌生。
但这是斯坦福大学里以中国人命名的研究所,2018年10月,出于纪念蔡崇信、吴明华夫妇对该所慷慨捐赠,正式命名为吴蔡神经科学研究所。
蔡崇信,大家都不陌生了。阿里巴巴合伙人,最早慧眼识珠加入马云的阿里事业的那个人。
也是鲜有机会,其夫人也被关注到。

现在,他们捐赠的研究所,产出了新成果。
所以新论文到手,欢迎细致研读后分享你的“读后感”哦。
论文地址:
https://arxiv.org/abs/2006.12373
从0到1学习SLAM,戳↓
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life
PS:公众号最近更改了推送规则,不再按时间顺序推送,而是根据智能推荐算法有选择性向用户推送,有可能以后你无法看到计算机视觉life的文章推送了。
解决方法是看完文章后,顺手点下文末右下角的“在看” ,系统会认为我们的文章合你口味,以后发文章就会第一时间推送到你面前的,比心~




