图片语义分割深度学习算法要点回顾

本文为 AI 研习社编译的技术博客,原标题 :
Review of Deep Learning Algorithms for Image Semantic Segmentation
作者 | Arthur Ouaknine
翻译 | dongburen、akizya、chesc、lydmom、我期待
校对 | 酱番梨 整理 | 菠萝妹
原文链接:
https://medium.com/@arthur_ouaknine/review-of-deep-learning-algorithms-for-image-semantic-segmentation-509a600f7b57
注:本文的相关链接请点击文末【阅读原文】进行访问

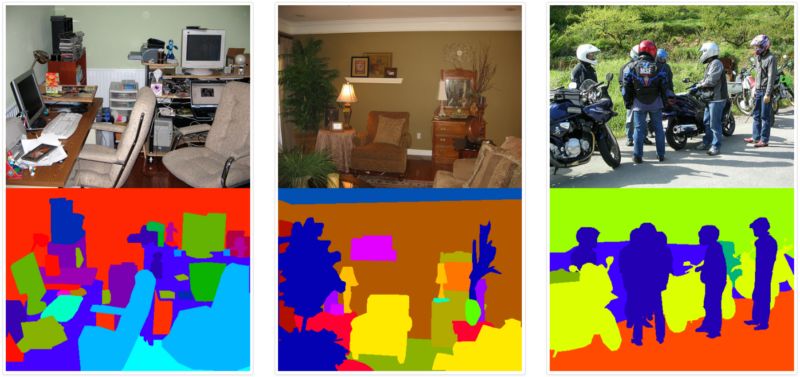
样本来自目标分割数据集COCO。
资源链接: http://cocodataset.org/
深度学习算法解决了数个难度级别逐渐上升的计算机视觉任务。在我先前的博文中,我已详细阐述了广为人知的两个任务:图像分类和目标检测。图像语义分割的难点在于将各个像素点分类到某一实例,再将各个实例(分类结果)与实体(大象,人,道路,天空等)一一对应。这任务即场景理解的一部分:深度学习模型怎样能更好地学习视觉内容的全局语境?
目标检测在复杂度方面超过图像分类。它在目标的边缘建立边框并分类。大多数目标检测模型利用anchor boxes并建议在目标附近检测边框。遗憾的是,仅有少数模型考虑了图像的全局语境,但其也仅分类了图像的一小部分信息。因此,现有的算法模形在场景理解上还不算好。
为了能够更好理解场景,在考虑空间信息时,任何视觉信息都必须与实体相联结。少数其它挑战出现在真实地理解图像或视频的动作:关键点检测,动作识别,视频字幕,视觉问题回答等。更好场情理解能力在很多领域有帮助。例如,自动驾驶汽车为了使自身移动,需要高精度地划定路边。在机器人学,生产机器需要划定目标物的精确形状,从而将抓取,转动,拼接两个部件。
在这篇博文中,将详细介绍了一些关于图像语义分割挑战的最新模型。注意,研究人员使用不同的数据集(PASCAL VOC、PASCAL Context、COCO、Cityscapes)测试他们的算法,这些数据集在不同年份之间不同,并且使用不同的评估度量。因此,新模型的性能不能与之前的模型直接对比。此外,结果取决于预训练的顶层网络(骨干),本文中的实验结果来自对应论文中关于测试数据集的最优实验结果。
数据集与矩阵
PASCAL Visual Object Classes (PASCAL VOC)
PASCAL VOC 数据集(2012)是常用于目标检测与图像分割的数据集。训练集与验证集有超过11k张图片,而测试集有10张。
图像分割使用平均交并比(mLoU)评估模型算法的性能。交并比(LoU)这种测度同样用于目标检测中评估预测位置的相关性。交并比(LoU)其实就是真实区域与预测区域的交集面积与并集面积的比值。而平均交并比(mLoU)就是整个数据集中图像的交并比的平均值。

PASCAL-Context
PASCAL-Context 数据集(2014)是PASCAL VOC 数据集(2010)的扩展。它包括了10k张训练图片,10k张验证图片,以及10k张测试图片。新版数据集的特别之处在于整个情景被分成超过400个分类。注意,这些图像由6名内部标注师花了六个月标注完成。
PASCAL-Context官方评估标准仍然是mloU。也有少数研究者在发表的时候采用像素准确度 (pixAcc)做为评估测度。这篇博文使用的mloU。
COntext中的常见物体(COCO)
图像语义分析(目标检测和物体分割)领域有过两场COCO比赛(2017,2018年)。“目标检测”任务包括将目标分割以及将其分类为80个类别中的一类。“物体分割”任务使用具有大的分割部分图像(天空,墙壁,草)的数据,它们几乎包含整个视觉信息。 在这篇博客文章中,只会比较“目标检测”任务的结果,因为在引用的研究论文中很少有人给出“物体分割”任务的结果。
用于物体分割的COCO数据集由超过200k个图像组成,具有超过500k个对象实例被分割。它包含一个训练数据集,一个验证数据集,一个用于研究者的测试数据集(test-dev)和一个用于挑战的测试数据集(test-challenge)。两个测试数据集的真实标签都不可知。这些数据集包含80个类别,只有相对应的目标被分割了。此比赛使用与目标检测比赛相同的指标:平均精度(AP)和平均召回(AR)均使用联合交叉(IoU)。
有关IoU和AP指标的详细信息,请参阅我之前的博客文章。例如AP,使用具有特定范围的重叠值的多个IoU来计算平均召回。对于固定的IoU,保留具有相应测试/真实事实重叠的对象。然后为检测到的对象计算Recall。最终AR度量是所有IoU范围值的Recall的平均值。基本上,用于分割的AP和AR度量对于目标检测具有相同的工作原理,除了IoU以像素方式计算,使用非矩形形状作语义分割。

COCO数据集上的物体分割实例。
来源:http://cocodataset.org/
Cityscapes
Cityscapes数据集已于2016年发布,包含来自50个城市的复杂的城市场景分割图。 它由23.5k张图像组成,用于训练和验证(详细和粗略的注释)和1.5个图像用于测试(仅详细注释)。 图像是完全分割的,例如具有29个类别的PASCAL-Context数据集(在8个超级类别中:平面,人类,车辆,建筑,物体,自然,天空,虚空)。 由于其复杂性,它通常用于评估语义分割模型。 它也因其与自动驾驶应用中的真实城市场景相似而众所周知。 诸如PASCAL数据集使用mIoU度量来评估语义分割模型的性能。
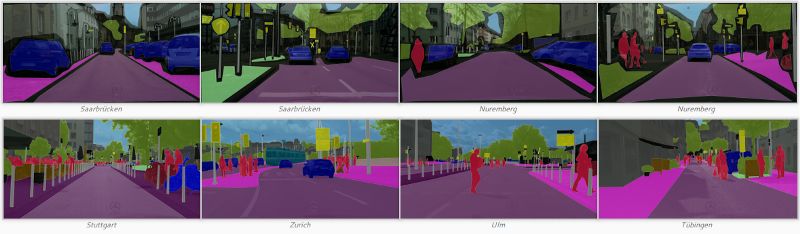
Cityscapes数据集的样例。上:粗略的标注。下:详细的标注。
来源:https://www.cityscapes-dataset.com/
全卷积神经网络
J. Long et al. (2015) 首次提出了端到端训练的全卷积神经网络(FCN)(仅包含卷积层),用于图像分割。
FCN以任意尺寸的图像作为输入,并生成具有相同尺寸的分割图像。作者首先修改了众所周知的网络架构(AlexNet,VGG16,GoogLeNet),使其具有非固定尺寸的输入,同时用卷积层替换所有的全连接层。由于网络生成的多个特征图具有小尺寸和密集表示的特点,因此需要进行上采样以创建与输入相同尺寸的输出。基本上,它包含一个步长低于1的卷积层。它通常被称为反卷积,因为它创建的输出尺寸大于输入。这样,使用像素级损失来训练网络。此外,他们在网络中添加了skip connections,以将更具体的高级特征图表示与网络顶部的密集表示相结合。
在2012年PASCAL VOC分割挑战中,作者使用2012年ImageNet数据集上的预训练模型,获得了62.2%的mIoU分数。对于2012年PASCAL VOC目标检测挑战,名为Faster R-CNN的基准模型已达到78.8%mIoU。即使我们不能直接比较两个结果(不同的模型,不同的数据集和不同的挑战),似乎语义分割任务比目标检测任务更难解决。
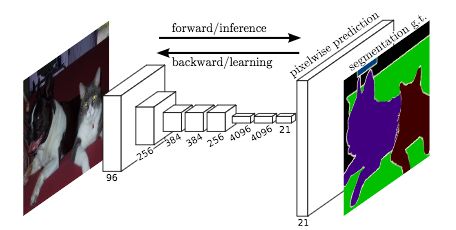
FCN的体系结构。请注意,此处未绘制skip connections。
来源: J. Long et al. (2015)
ParseNet
W. Liu et al. (2015) 发表了一篇论文,解释了J. Long et al. (2015)的FCN模型的改进。这组作者说,FCN模型通过专注于生成的特征图,在其深层中丢失了图像的全局背景。ParseNet是一个端到端的卷积网络,可同时预测所有像素的值,避免将区域作为输入来保持全局信息。作者使用一个模块将特征图作为输入。第一步使用模型生成特征图,用池化层把这些特征图缩减为单个全局特征向量。使用L2欧几里德范数对该全局向量进行归一化,并且将其unpool(输出是输入的扩展版本)以生成具有与初始尺寸相同的新特征图。第二步使用L2欧几里德范数对整个初始特征图进行归一化。最后一步是连接前两个步骤生成的特征图。归一化有助于对连接的特征图的值进行缩放,从而获得更好的性能。基本上,ParseNet是一个FCN的变体,用该模块取代了卷积层。它在PASCAL-Context挑战中获得了40.4%的mIoU分数,并且在2012年PASCAL VOC分割挑战中获得了69.8%的mIoU分数。
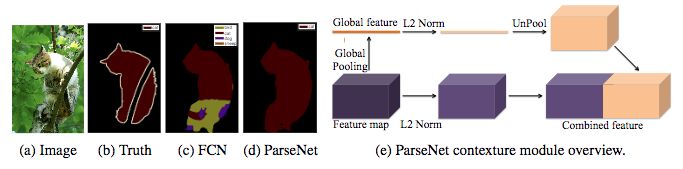
FCN与ParseNet的分割效果比较,和ParseNet模块的架构。
来源: W. Liu et al. (2015)
卷积与反卷积网络
H. Noh et al. 在2015年的时候发布了一种由两个相连部分组成的端到端模型。第一个部分是一个VGG16架构的卷积网络。在这一部分里,以instance proposal作为输入,比如从一个目标检测模型输出的边界框。之后,卷积网络会对输入进行处理、转换得到一个关于特征的向量。第二部分则是一个以第一部分得到的特征向量为输入的反卷积网络,最后的输出结果是一张像素级的概率映射图,表示每个像素属于每一类别的概率为多少。反卷积网络使用反池化来找到激活程度最大的点来保留映射图中信息的位置信息不丢失。第二个网络同时也使用单输入,经过反卷积后输出多张特征图。这样,反卷积在保留原来信息的密集性同时也扩展了特征图。
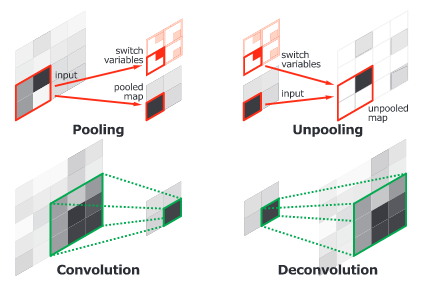
卷积网络层(池化和卷积)和反卷积网络层(反池化和反卷积)的比较。
来源:H. Noh et al. (2015)
作者们分析反卷积特征图后表明,低级别的特征图主要是包含了形状的信息,而高级的特征图有助于模型作分类。最后当整个网络处理完一张图片的所有proposal时,特征图将被合并得到完全分割的图像。这个网络在2012年PASCAL VOC分割比赛中获得了72.5%的MIoU.
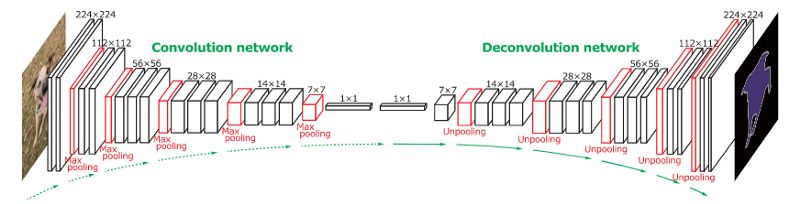
整个网络的架构
卷积网络部分基于VGG16的架构。反卷积部分使用反池化和反卷积层。
来源: H. Noh et al. (2015)
U-Net
O. Ronneberger et al. 在2015年扩展了J. Long et al. (2015)的FCN模型用于生物显微镜图像。作者们创造了一种叫U-net的网络,由两部分组成:计算生成特征的收缩部分,以及在图片上空间定位特征模式的扩展部分。下采样或者说收缩部分有一个类FCN的架构,用3x3的卷积核来提取特征。而上采样或者扩展部分则时通过用上卷积(或反卷积)来减少特征图的数量但是增加了特征图的高和宽。经过下采样得到的特征图在上采样时会被复制,意在避免丢失有关特征模式的信息。最后,再使用1x1的卷积核做一次卷积产生一张分割图,也就得到了输入图像中每个像素的分类情况。从那之后,U-net就被广泛地使用、拓展,在一些最近的研究里都可以看到它的身影(FPN, PSPNet, DeepLabv3等等)。需注明的是U-net里没有使用任何全接连层。因此,模型参数的数量被大大减少,可以用来训练只有少量有标签的数据集(通过使用适合的数据增强)。举例来说,作者在实验部分就使用了一个只有30张图片的公开数据集来训练模型。
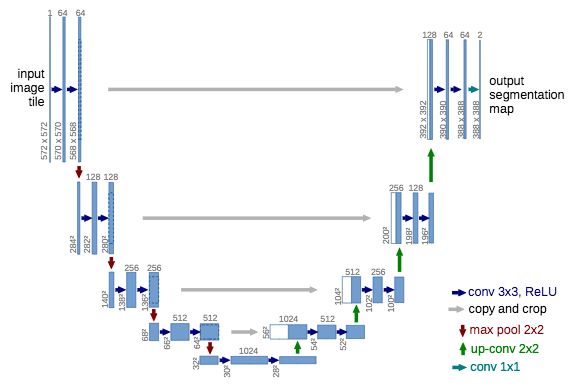
给定一张输入图像的U-net架构。蓝色框对应于具有其表示形状的特征映射块。白色框对应于复制和剪裁后的特征图。
来源:O. Ronneberger et al. (2015)
特征金字塔网络(FPN)
特征金字塔网络(FPN)由T.-Y. Lin等人开发(2016),并且它用于对象检测或图像分割框架。 其架构由自下而上的通道,自上而下的通道横向连接组成,以便连接低分辨率和高分辨率的特征。 自下而上的路径采用任意大小的图像作为输入。 它使用卷积层处理,并通过池化层进行下采样。请注意,每组具有相同大小的特征图称为一个阶段,每个阶段的最后一层的输出是用于金字塔等级的特征。 自上而下的路径包括对最后一个特征图进行上采样反池化,同时使用横向连接在自下而上路径的同一阶段使用特征图增强它们。 这些连接包括将经过1x1卷积(以减小其维度)的自下而上路径的特征图与自上而下路径的特征图合并。
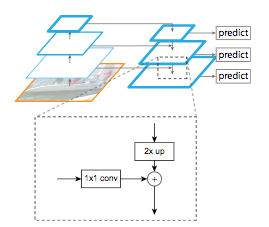
具有横向连接和特征映射之和的自上而下的块过程的细节。
来源:T.-Y. Lin et al (2016)
然后,通过3x3卷积处理合并的特征图以产生该阶段的输出。 最后,自上而下路径的每个阶段生成被检测对象的预测。 对于图像分割,作者使用两个多层感知器(MLP)在对象上生成两个不同大小的掩码。 它类似于具有锚箱的Region Proposal Networks(R-CNN R. Girshick等人(2014),Fast R-CNN R. Girshick等人(2015),Faster R-CNN S. Ren等人(2016) ) 等等)。 这种方法很有效,因为它可以更好地将信息量不足的信息传播到网络中。 基于DeepMask(P. 0. Pinheiro等人(2015))和SharpMask(P. 0. Pinheiro等人(2016))框架的FPN在2016年COCO分割挑战中获得了48.1%的平均召回(AR)分数。
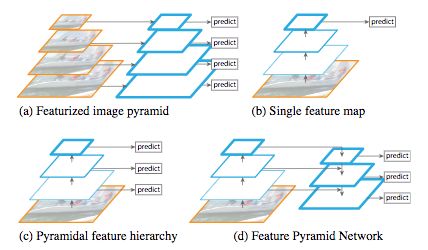
架构比较。
(a):图像用几种尺寸缩放,每一种都用卷积处理,以提供计算上可扩展的预测。
(b):只有单个尺寸的图像由具有卷积层和池化层CNN处理。
(c):CNN的每一步都用于提供预测。
(d):FPN的体系结构,左边为自下到上部分,右边为自上而下部分。
来源:T.-Y. Lin et al (2016)
金字塔场景解析网络
为了更好地了解场景的全局环境表征,H.Zhao等人编写的论文(2016)开发了金字塔场景解析网络(PSPNet)。使用扩张网络策略的特征提取器可以从输入图像中提取模式patterns(何凯明等人发明的ResNet(2015))¹。特征映射(feature maps)提供了一个金字塔池化模块(Pyramid Pooling Module)来区分不同规模的patterns。这些特征映射由4个不同规模的结构组成,每个结构对应于一个金字塔层,并由1x1卷积层处理以减少它们的维数。用这种方法,每个金字塔层分析不同位置图像的子区域。金字塔层的输出被向上采样,并连接到初始特征映射,最终包含本地和全局环境信息。然后,由卷积层处理它们,生成像素级别的预测。使用了pretrained ResNet(使用COCO数据集)的最佳PSPNet在2012 PASCAL VOC分割挑战中获得了85.4%的mIoU评分。
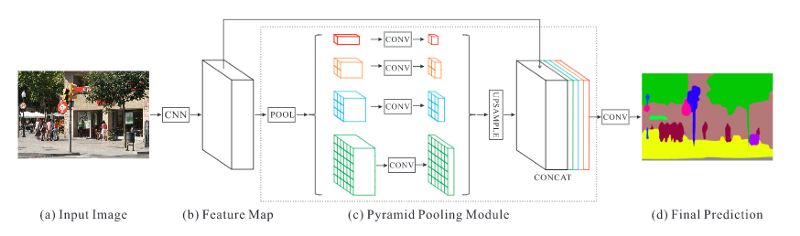
(a)输入图像 (b)特征映射 (c)金字塔池化模块 (d)最终的预测
PSPNet结构
输入图像(a)是由CNN处理生成的特征映射(b)。他们提供了一个金字塔池模块 (c) ,并生成了一个像素级别的预测。
来源:H.Zhao等人编写的论文(2016)
Mask R-CNN
何凯明等人于2017年发布的Mask R-CNN模型击败了COCO挑战先前的所有基准成绩。我在之前的博客中已经提供了关于 Mask R-CNN 用于目标检测的细节。需要提醒的是,Faster R-CNN (S. Ren et al. (2015))结构对象检测中,使用区域建议网络(Region Proposal Network,RPN)来提出边界框候选。RPN提取感兴趣的区域(Region of Interest,RoI), RoI池化层从这些建议中计算特征,以推断出边界框候选和对象的类别。Mask R-CNN是一个有3个输出分支的 Faster R-CNN :第一个计算边界框坐标,第二个计算相关的类别和最后一个计算二元mask³来分割目标。二分的mask的大小是固定的,它是由FCN为给定的RoI生成的。它还使用RoIAlign层代替RoIPool,以避免由于RoI坐标的量化造成的失调。Mask R-CNN模型的特殊性在于它结合了包围框坐标的丢失、预测类的丢失和分割掩码的丢失,从而实现了多任务丢失的结合。最好的Mask R-CNN使用ResNeXt (S. Xie et al. (2016))提取特征和FPN架构。2016年COCO分隔挑战AP得分为37.1%,2017年COCO分割挑战AP得分为41.8%。
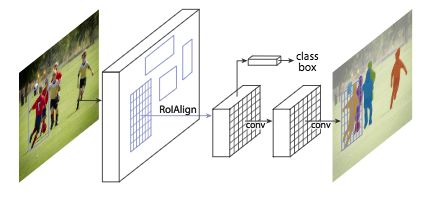
Mask R-CNN结构
第一层是RPN提取RoI。第二层处理RoI,生成特征映射。它们直接用于计算边界框坐标和预测的类别。特征映射也由FCN(第三层)处理以生成二元mask。
来源:K. He et al. (2017)
DeepLab, DeepLabv3 以及 DeepLabv3+
DeepLab
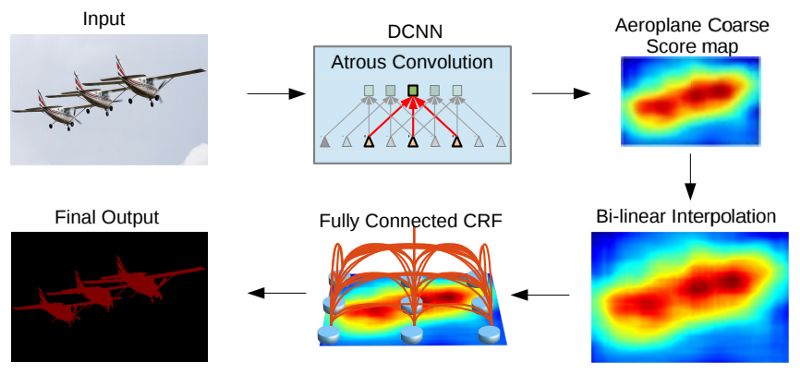
由lin等人的FPN模型受到启发,chen 等人结合了带孔卷积核,空间金字塔池化和全连接的CRFs提出了DeepLab。这篇文章提出的模型也叫做DeepLabv2,因为这个模型是原始的DeepLab的一个调整(为了避免信息冗余,不会提供原始的模型信息),根据作者的意思,连续的最大池化和跨度减少了深度神经网络中特征图的分辨率,他们介绍了以zhao等人的空洞卷积为基础的带孔卷积核,它由以固定采样率瞄准稀疏像素的滤波器组成。例如,如果采样率等于2,滤波从瞄准原图中的一个像素到瞄准两个像素,如果采样率为1,带孔卷积就是一个普通的卷积。带孔卷积保证获取目标的不同尺度。当在没有最大池化的情况下使用它时,它会增加最终输出的分辨率而不会增加权重数。
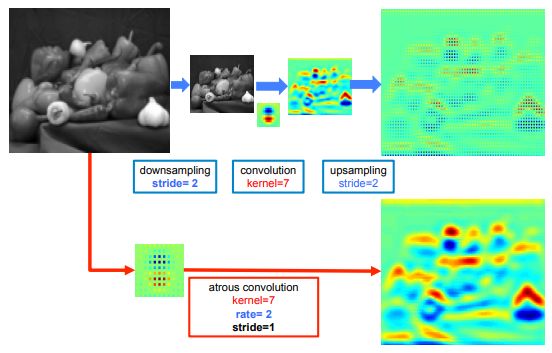
标准卷积用于低分辨率输入(顶端)与采样率为2的带孔卷子用于高分辨率输入的提取特征对比(底部)。
来源:chen等人(2017)。
带孔空间金字塔池化由具有不同的采样率的带孔卷积对相同的输入卷积组成,用于检测空间模式。特征图在不同的批次中处理,并使用双线性插值连接以恢复输入的原始大小。输出由全连接的条件随机场计算特征和长期依赖性之间的边缘以产生语义分割。
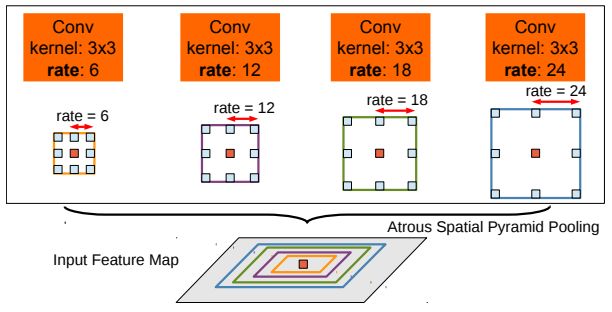
带孔空间金字塔池化利用了目标的多尺度对中心的像素进行分类。
来源:chen等人(2017年)
使用ResNet-101作为主干的最佳DeepLab在2012年PASCAL VOC挑战中达到了79.7%的mIoU分数,在PASCAL-Context挑战中获得了45.7%的mIoU分数,在Cityscapes挑战中获得了70.4%的mIoU分数。
DeepLabv3
chen等人在DeepLab框架的基础上,创建了DeepLabv3,结合了带孔卷积的级联和并行模块。作者修改了ResNet架构,使用空洞卷积将深度块中的高分辨率特征映射保留下来。
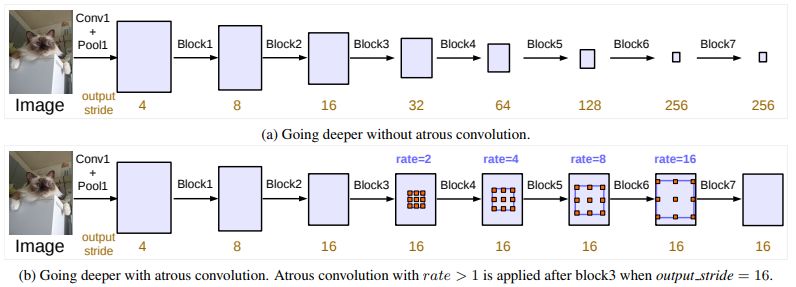
ResNet架构中的级联模块。
来源:chen等人(2017)
并行空洞卷积模型在空洞空间金字塔池化(ASPP)中被分组。一个1*1卷积和批规范化都被加入ASPP.所有输出由另一个1x1卷积连接和处理,以创建具有每个像素的逻辑的最终输出。
Deeplabv3框架中的空洞空间金字塔池。 资料来源:chen等人(2017)
在2012年PASCAL VOC挑战中,使用ResNet-101在ImageNet和JFT-300M数据集上预训练的最佳DeepLabv3模型已达到86.9%mIoU分数。 它还通过仅使用相关训练数据集训练的模型在Cityscapes挑战中获得81.3%的mIoU分数。
DeepLabv3+
chen等人(2018)最终发布了结合了编码器 - 解码器结构框架的Deeplabv3。作者引入了空洞可分离卷积,它包含深度卷积(将输入的每一个通道进行卷积)和逐点卷积(1*1的卷积和深度卷积作为输入)。
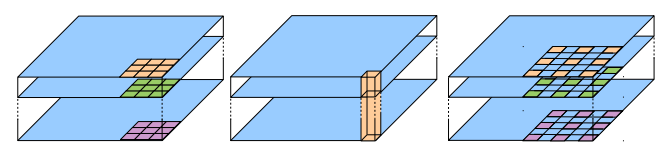
深度卷积(a)与逐点卷积(b)的结合产生空洞可分离卷积(采样率为2)。
来源:chen等人(2018)
他们使用DeepLabv3框架为编码器。最高性能的模型具有修改的Xception(F.Chollet(2017))主干,空洞深度可分离卷积层代替了最大池层和批量标准化。 ASPP的输出由1x1卷积处理并且以4倍进行上采样。编码器主干CNN的输出也由另一个1x1卷积处理并连接到先前的卷积。 特征映射提供两个3x3卷积层,输出按4倍上采样以得到最终的分割图像。
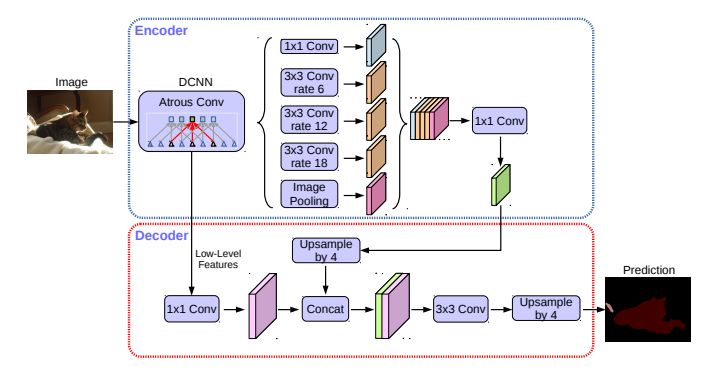
DeepLabv3 +框架:一个具有基本的CNN和一个ASPP的编码器产生特征表示,具有3x3卷积的解码器接收特征表示,产生最终预测图像。
来源:chen等人。(2018)
在COCO和JFT数据集上预训练获得的最佳DeepLabv3 +在2012年PASCAL VOC挑战中获得了89.0%的mIoU分数。 在Cityscapes数据集上训练的模型已达到相关挑战的82.1%mIoU分数。
路径聚合网络(PANet)
S. Liu et al. (2018) 最近提出了路径聚合网络(PANET)。该网络基于Mask R-CNN和FPN框架,同时增强了信息传播。网络的特征提取器使用了改进的FPN架构,其添加了自底向上的增强路径,从而改善了低层特征的传播。新增的第三路径的每个阶段都将前一阶段的特征图作为输入,并用3×3卷积层处理它们。使用横向连接将卷积的输出添加到自顶向下路径的相同阶段特征图中,然后把这些特征图送到下一阶段。
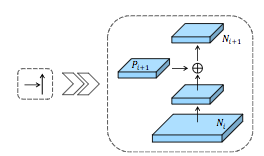
自上而下的路径和增强的自下而上路径之间的横向连接。
来源:S. Liu et al. (2018)
用RoIAlign层对增强的自下而上路径的特征图进行池化,以从所有级别特征中提取区域提议。自适应特征池化层使用全连接层处理每个阶段的特征图,并把所有输出连接起来。
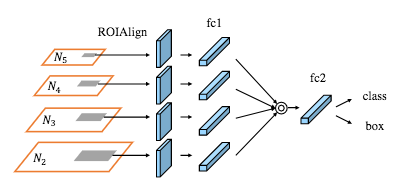
自适应特征池化层。
来源: S. Liu et al. (2018)
与Mask R-CNN类似,自适应特征池化层的输出送到三个分支。前两个分支用全连接层来生成边界框坐标和相关目标类别的预测。第三个分支使用FCN处理RoI,以预测检测到的目标的二进制像素级掩码。作者添加了一条处理FCN卷积层输出的路径,该路径用全连接层来提高预测像素的位置。最后,并行路径的输出被调整尺寸,并连接到FCN生成的二进制掩码输出。
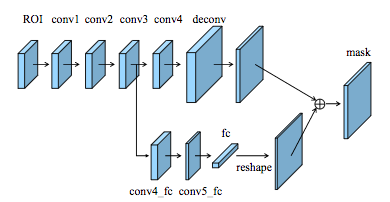
PANet的分支使用FCN和有全连接层的新路径预测二进制掩码。
来源:https://arxiv.org/pdf/1803.01534.pdf
使用ResNeXt作为特征提取器,PANet在2016年COCO分割挑战中获得了42.0%的平均精度分数。他们还使用七个特征提取器的集合进行了2017年COCO分割挑战,平均精度为46.7%:ResNet (K. He et al. (2015), ResNeXt (S. Xie et al. (2016)) and SENet (J. Hu et al.(2017))。
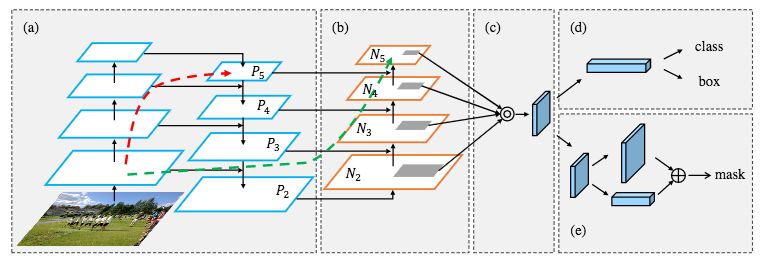
PANet Achitecture。
(a):使用FPN架构的特征提取器。
(b):新增加的自下而上的路径被添加到FPN架构中。
(c):自适应特征池化层。
(d):两个分支分别预测边界框坐标和目标类别。
(e):预测目标的二进制掩码的分支。虚线对应于低级和高级模式之间的链接,红色部分是在FPN中,并且其包含的层数超过100;绿色部分是在PANet中的捷径,包含的层数少于10。
来源:S. Liu et al. (2018)
环境编码网络 (EncNet)
H. Zhang et al. (2018)创造了一种环境编码网络(EncNet) 捕捉一张图像中的全局信息,以提高场景分割性能。这个模型开始时使用一个基础的特征提取器(ResNet),并向环境编码模块提供特征映射,这个模块是由H.Zhang等人提出的(2016)编码层激发的。本质上,它学习视觉中心和平滑因子来创建一个嵌入,同时突出依赖类的特征映射,同时考虑环境信息。在该模块之上,利用特征映射注意层(全连接层)学习环境信息的缩放因子。与此同时,对应于二元交叉熵损失的语义编码损失(SE-Loss)通过检测对象类的存在(不同于像素级别的损失)来规范模块的训练。 环境编码模块的输出通过扩展卷积策略进行重构和处理,同时最小化两个语义编码损失SE-Loss和一个最后的像素级别的损耗。在PASCAL-Context挑战中,最好的EncNet达到了52.6%mIoU和81.2% pixAcc得分。在2012 PASCAL VOC分割挑战赛中,也取得了85.9%mIoU的高分。
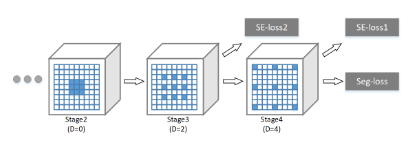
扩展卷积策略
蓝色的是卷积滤波器,D是膨胀率。在第三和第四阶段之后,应用 SE-Loss (语义编码损失)来检测对象类。一个最后的seg-loss(像素丢失)用于改进分割性能。
来源:H. Zhang et al. (2018)
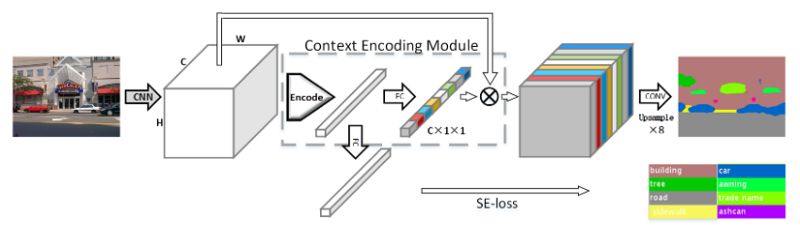
EncNet结构
特征提取器生成特征映射,特征映射作为环境编码模块的输入。使用语义编码损失对模块进行正则化训练。模块的输出由一个膨胀的卷积策略处理以产生最终的分割。
来源:[H. Zhang et al. (2018)
结论
图像语义分割是近年来端到端深度神经网络所面临的挑战。各体系结构之间的主要问题之一是考虑输入图像的全局视觉环境,以提高分割的预测能力。最先进的模型使用架构试图连接图像的不同部分,以便理解对象之间的关系。
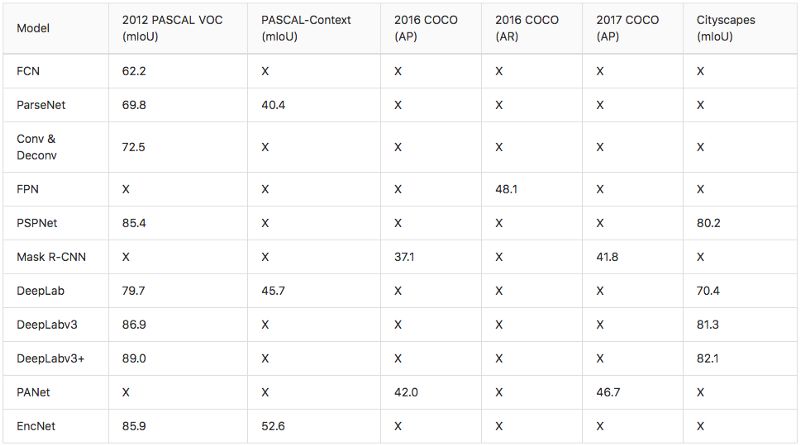
各个模型在2012 PASCAL VOC (mIoU), PASCAL-Context (mIoU), 2016 / 2017 COCO (AP and AR)和 Cityscapes (mIoU)数据集的得分综述。
对整幅图像进行像素预测,可以更准确地理解环境,得到更高的精度。场景理解还涉及到关键点检测、动作识别、视频字幕或视觉问题回答。在我看来,分割任务结合这些其他问题使用多任务损失应该有助于更好地理解场景的全局环境。
最后,我想感谢Long Do Cao在我所有的帖子上对我的帮助,如果你在寻找一个伟大的高级数据科学家,你应该查看他的个人资料。
扩展的卷积层已经由[F. Yu and V. Koltun (2015)]发布。它是一个带扩展滤波器的卷积层(滤波器的神经元不再是并排的)。膨胀率修正了两个神经元之间的像素差距。DeepLab部分提供了更多细节。
目标检测,目标分割和关键点检测
Mask R-CNN模型对目标计算二元掩码时,使用目标类别预测(实例第一策略)代替把每一个像素都划分类别的策略(分割第一策略)。
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【阅读原文】:
https://ai.yanxishe.com/page/TextTranslation/1339
AI研习社每日更新精彩内容,观看更多精彩内容:
五个很厉害的 CNN 架构
深度强化学习中的好奇心
用Pytorch做深度学习(第一部分)
手把手:用PyTorch实现图像分类器(第二部分)
等你来译:
对混乱的数据进行聚类
初学者怎样使用Keras进行迁移学习
强化学习:通往基于情感的行为系统
如果你想学数据科学,这 7 类资源千万不能错过
【AI求职百题斩】已经悄咪咪上线啦,还不赶紧来答题?!

想知道正确答案?
回公众号聊天界面并发送“1224挑战”即可获取!
点击 阅读原文 查看本文更多内容↙


