加速RL探索效率,CMU、谷歌、斯坦福提出以弱监督学习解纠缠表征
选自arXiv
作者:Lisa Lee等
机器之心编译
机器之心编辑部
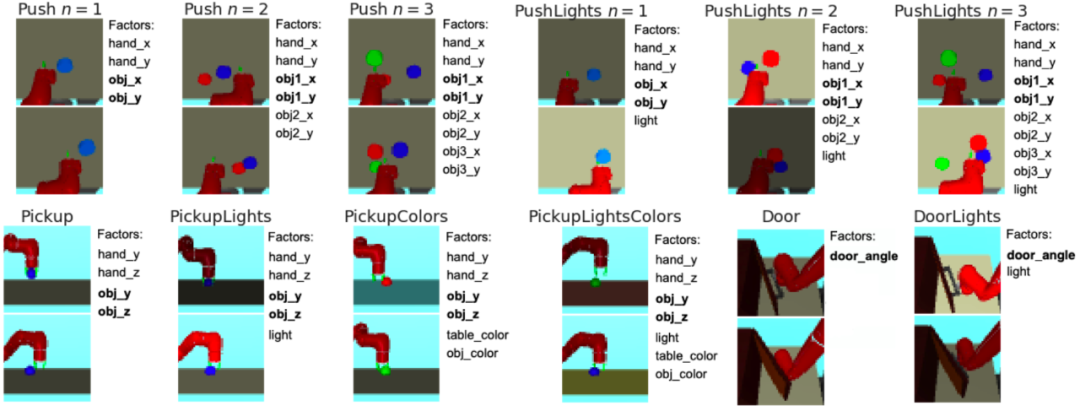
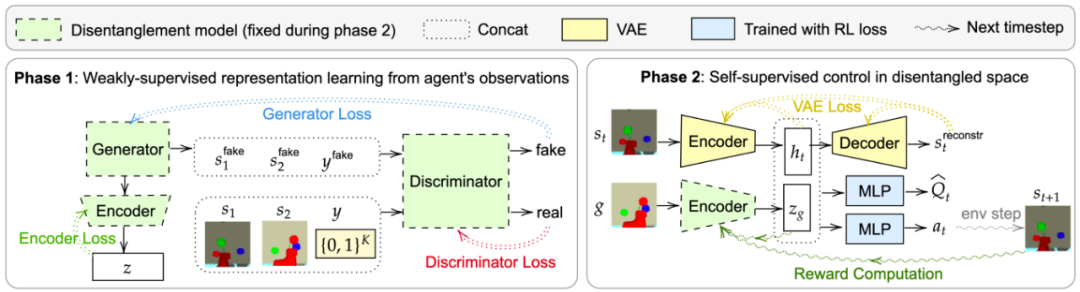
巨大的探索空间阻碍了强化学习(RL)的发挥,这篇论文通过弱监督学习从广泛的目标空间中分离出有语义意义的表征空间,从而增强 RL 的学习速度与泛化性能。

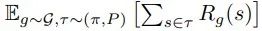 来训练策略 π_θ (a_t | s_t, g),从而在目标空间中达到目标 g〜G,其中 R_g(s) 是由目标 g ∈ G 和观测值 s ∈ S 之间的距离度量定义的奖励函数。
来训练策略 π_θ (a_t | s_t, g),从而在目标空间中达到目标 g〜G,其中 R_g(s) 是由目标 g ∈ G 和观测值 s ∈ S 之间的距离度量定义的奖励函数。
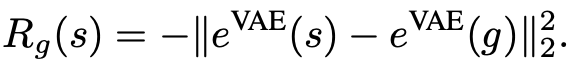
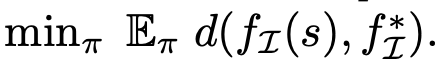
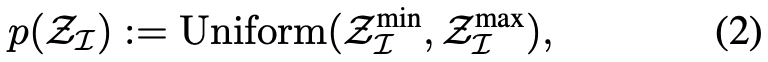
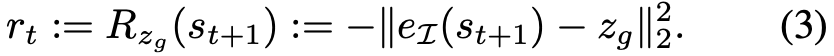

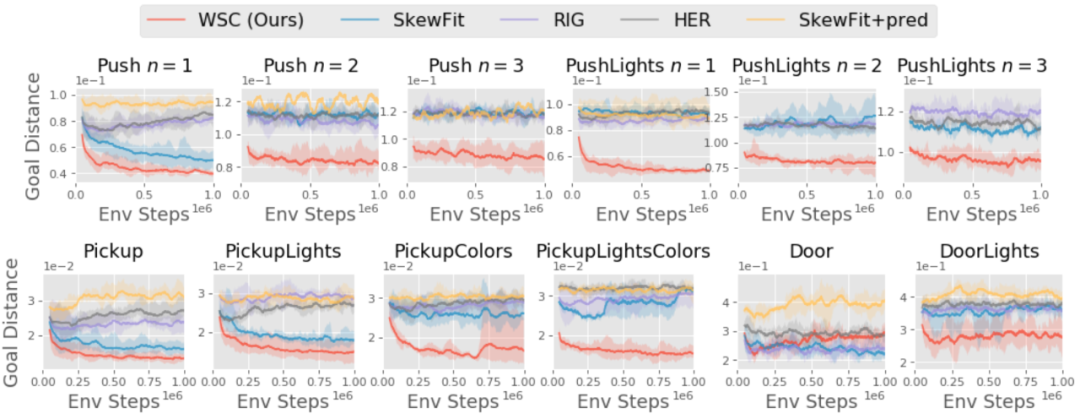
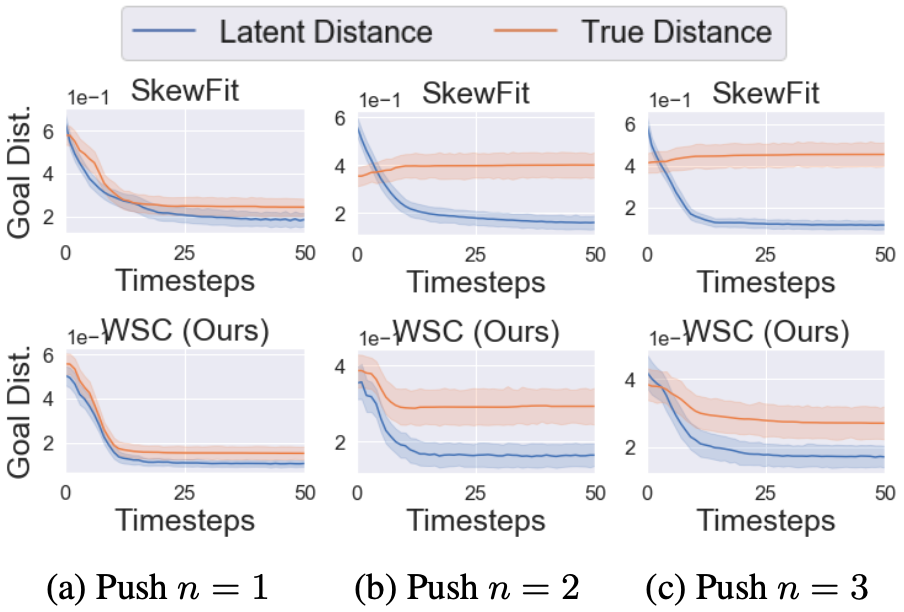
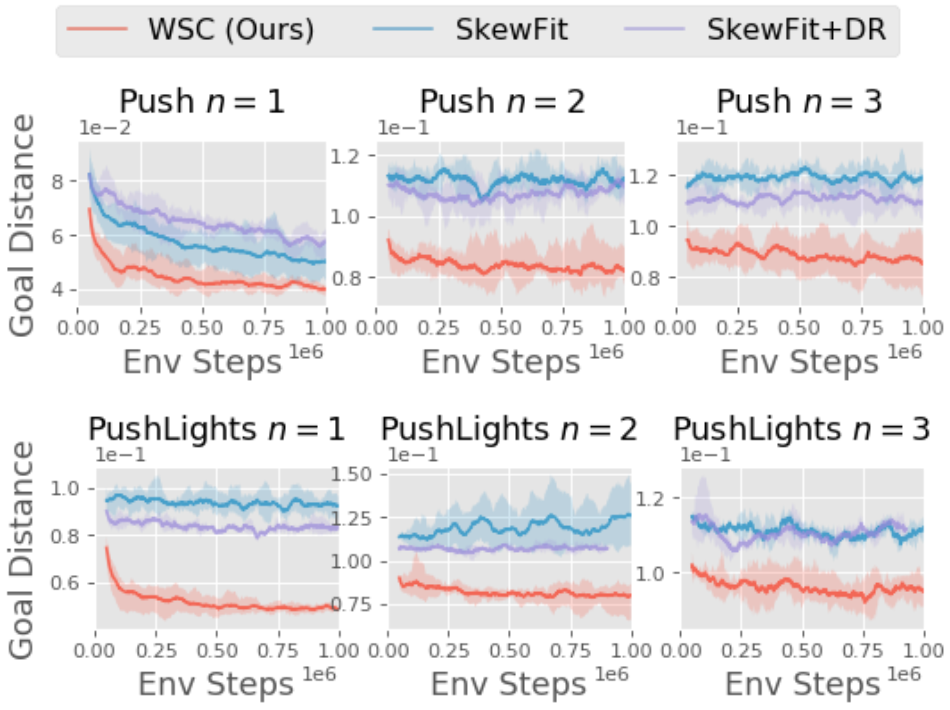

登录查看更多
相关内容

Arxiv
5+阅读 · 2018年4月3日
Arxiv
3+阅读 · 2018年1月30日
Arxiv
4+阅读 · 2017年10月26日



相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2018年4月3日
Arxiv
3+阅读 · 2018年1月30日
Arxiv
4+阅读 · 2017年10月26日