CMU、谷歌提出Transformer-XL:学习超长上下文关系
选自 arxiv
作者:Zihang Dai 等
机器之心编译
参与:李诗萌、王淑婷
以往的 Transformer 网络由于受到上下文长度固定的限制,学习长期以来关系的潜力有限。本文提出的新神经架构 Transformer-XL 可以在不引起时间混乱的前提下,可以超越固定长度去学习依赖性,同时还能解决上下文碎片化问题。
语言建模需要对长期依赖性进行建模,它成功应用了无监督的预训练方法 (Peters et al., 2018; Devlin et al., 2018)。但要让神经网络对序列数据的长期依赖性建模一直都是一项挑战。
近期,Al-Rfou 等人(2018)设计了一组辅助损失来训练深度 Transformer 网络进行字符级语言建模,其结果远超 LSTM。虽然已经取得成功,但是 Al-Rfou 等人(2018)的 LM 是在长度固定的几百个字符片段上独立训练的,没有任何跨片段的信息流。由于上下文的长度是固定的,因此模型无法捕获任何超过预定义上下文长度的长期依赖性。此外,长度固定的片段都是在不考虑句子或其它语义边界的情况下通过选择连续的符号块来创建的。因此,模型缺乏必要的上下文信息来很好地预测前几个符号,这就导致模型的优化效率和性能低下。我们将这个问题称为上下文碎片化。
为了解决上文提到的上下文固定长度的限制,本文提出了一种叫做 Transformer-XL(超长)的新架构。我们将循环概念引入了深度自注意力网络。我们不再从头计算每个新片段的隐藏状态,而是重复使用从之前的片段中获得的隐藏状态。我们把重复使用的隐藏状态作为当前片段的内存,这就在片段之间建立了循环连接。因此,对超长期依赖性建模成为了可能,因为信息可以通过循环连接来传播。同时,从之前的片段传递信息也可以解决上下文碎片化的问题。更重要的是,我们展示了使用相对位置而不是用绝对位置进行编码的必要性,因为这样做可以在不造成时间混乱的情况下实现状态的重复使用。因此,作为额外的技术贡献,我们引入了简单但有效的相对位置编码公式,它可以泛化至比在训练过程中观察到的长度更长的注意力长度。
Transformer-XL 对从单词级到字符集的五个语言数据集上建模,都获得了很好的结果。Transformer-XL 提升了当前最佳(SoTA)的结果,它在 enwiki8 上将 bpc 从 1.06 提升到 0.99,在 text8 上将 bpc 从 1.13 提升到 1.08,在 WikiText-103 上将困惑度从 20.5 提升到 18.3,在 One Billion Word 上将困惑度从 23.7 提升到 21.8。TransformerXL 在宾州树库数据集上在没有经过微调的情况下也得到了 54.5 的困惑度,在同等配置下这是当前最佳的结果。
我们用了两种方法来定量研究 Transformer-XL 的有效长度和基线。和 Khandelwat 等人(2018)所做的研究相似,我们在测试时逐渐增加注意力长度,直到观察不到显著改善(相对增益小于 0.1%)为止。在这个配置下,我们的最佳模型在 WikeText-103 和 enwiki8 中用的注意力长度分别是 1600 和 3800。此外,我们还设计了一个叫做 Relative Effective Context Length (RECL) 的指标,该指标可以公平比较增加上下文长度对不同模型带来的收益。在这个配置下,Transformer-XL 在 WikiText-103 中学到 900 个词的 RECL,而循环网络和 Transformer 分别只学到了 500 和 128 个词。
论文:TRANSFORMER-XL: ATTENTIVE LANGUAGE MODELS BEYOND A FIXED-LENGTH CONTEXT

论文地址:https://arxiv.org/abs/1901.02860
摘要:Transformer 网络具有学习更长期依赖性的潜力,但这种潜力往往会受到语言建模中上下文长度固定的限制。因此,我们提出了一种叫做 Transformer-XL 的新神经架构来解决这一问题,它可以在不破坏时间一致性的情况下,让 Transformer 超越固定长度学习依赖性。具体来说,它是由片段级的循环机制和全新的位置编码策略组成的。我们的方法不仅可以捕获更长的依赖关系,还可以解决上下文碎片化的问题。Transformer-XL 学习到的依赖性比 RNN 学习到的长 80%,比标准 Transformer 学到的长 450%,无论在长序列还是短序列中都得到了更好的结果,而且在评估时比标准 Transformer 快 1800+ 倍。此外,我们还提升了 bpc 和困惑度的当前最佳结果,在 enwiki8 上 bpc 从 1.06 提升至 0.99,在 text8 上从 1.13 提升至 1.08,在 WikiText-103 上困惑度从 20.5 提升到 18.3,在 One Billion Word 上从 23.7 提升到 21.8,在宾州树库(不经过微调的情况下)上从 55.3 提升到 54.5。我们的代码、预训练模型以及超参数在 TensorFlow 和 PyTorch 中都可以使用。
3 模型
用 Transformer 或自注意力机制进行语言建模的核心问题在于,如何将 Transformer 训练为可以把任意长度的上下文有效编码为长度固定的表征。在给定无限内存和计算资源的情况下,一种简单的方法是用无条件的 Transformer 解码器处理整个上下文序列,这和前馈神经网络相似。但在实践中资源都是有限的,因此这种方法不可行。
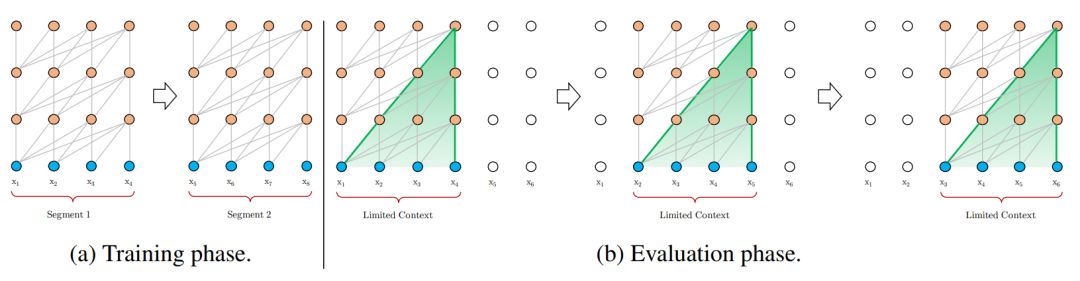
图 1:片段长度为 4 的标准模型图示。
为了解决使用固定长度上下文的局限性,我们在 Transformer 架构中引入了循环机制。在训练过程中,为之前的片段计算的隐藏状态序列是固定的,将其缓存起来,并在模型处理后面的新片段时作为扩展上下文重复使用,如图 2a 所示。
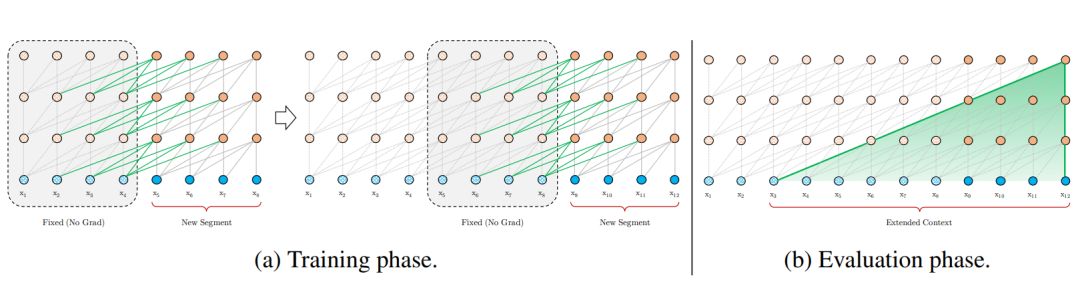
图 2:片段长度为 4 的 Transformer-XL 图示。
尽管在上一小节中提出的想法极具吸引力,但为了重复使用隐藏状态,我们还有一个尚未解决的重要技术问题。那就是,当我们重复使用隐藏状态时,要如何保证位置信息的一致性呢?
解决这个问题的基本思想是只编码隐藏状态中的相对位置信息。对相对位置进行编码的想法已经在机器翻译(Shaw et al.,2018)和音乐生成(Huang et al.,2018)中探索过。我们在此进行了不同的推导,得到了相对位置编码的新形式,它不仅与绝对位置编码有一对一的对应关系,而且从经验上讲它的泛化效果更好。
4 实验
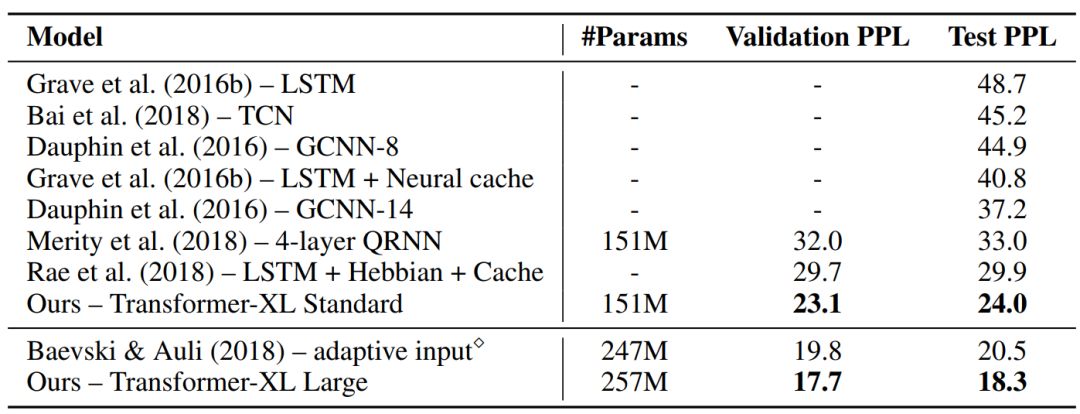
表 1:与在 WikiText-103 上得到的当前最佳结果进行对比。
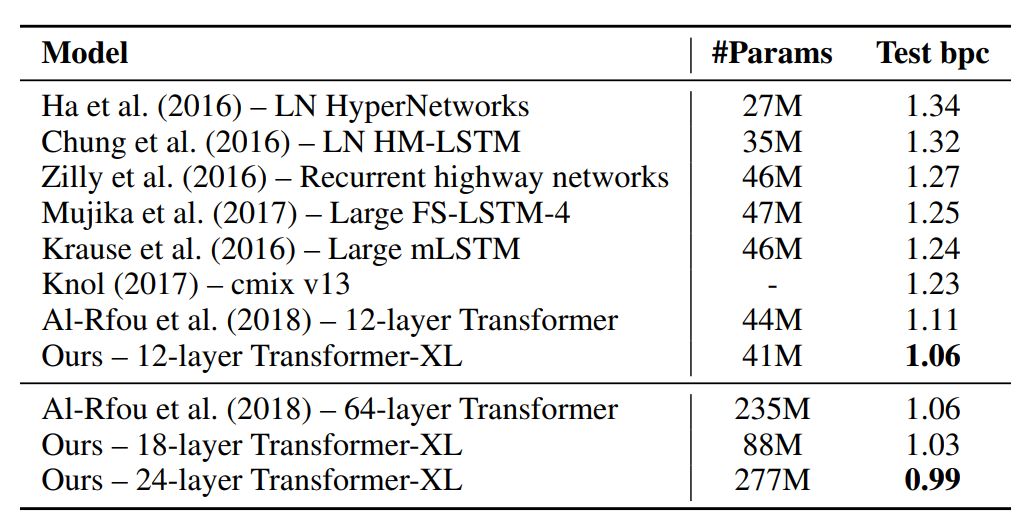
表 2:与在 enwiki8 上得到的当前最佳结果进行对比。

表 3:与在 text8 上得到的当前最佳结果进行对比。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


