
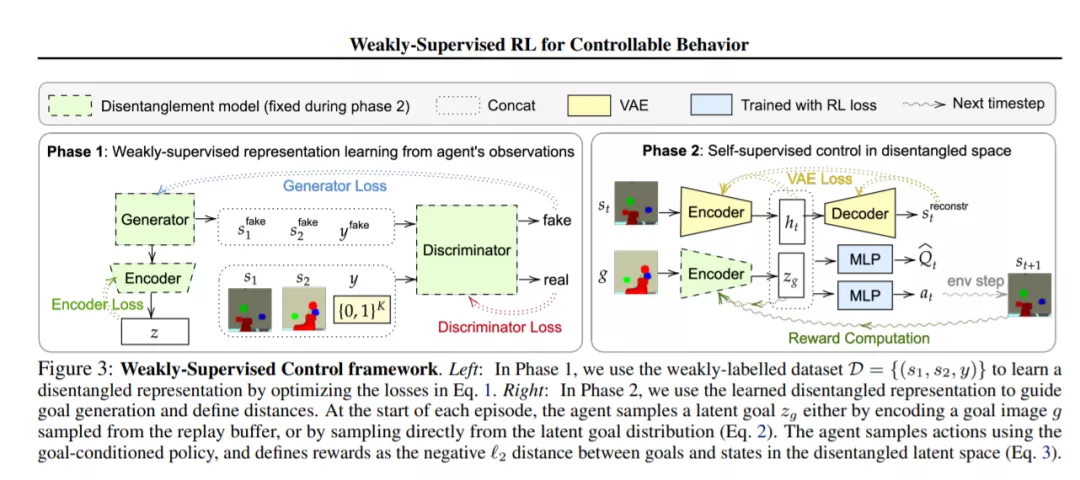
强化学习(RL)是学习采取行动解决任务的强大框架。然而,在许多情况下,一个代理必须将所有可能的任务的大得令人难以置信的空间缩小到当前要求它解决的单个任务。我们是否可以将任务的空间限制在语义上有意义的范围内呢?在这项工作中,我们介绍了一个使用弱监督的框架来自动地把这个语义上有意义的子空间的任务从巨大的无意义的“杂碎”任务中分离出来。我们证明了这个学习得的子空间能够进行有效的探索,并提供了捕获状态之间距离的表示。对于各种具有挑战性的、基于视觉的连续控制问题,我们的方法带来了大量的性能收益,特别是随着环境的复杂性的增长。
成为VIP会员查看完整内容

相关内容
专知会员服务
69+阅读 · 2020年6月19日
专知会员服务
20+阅读 · 2020年2月12日
Arxiv
5+阅读 · 2019年9月26日
相关VIP内容
专知会员服务
69+阅读 · 2020年6月19日
专知会员服务
20+阅读 · 2020年2月12日
相关资讯
相关论文
Arxiv
5+阅读 · 2019年9月26日