未来“智能教育”的蓝图:大规模在线教育中的知识智能
大规模在线课程MOOC






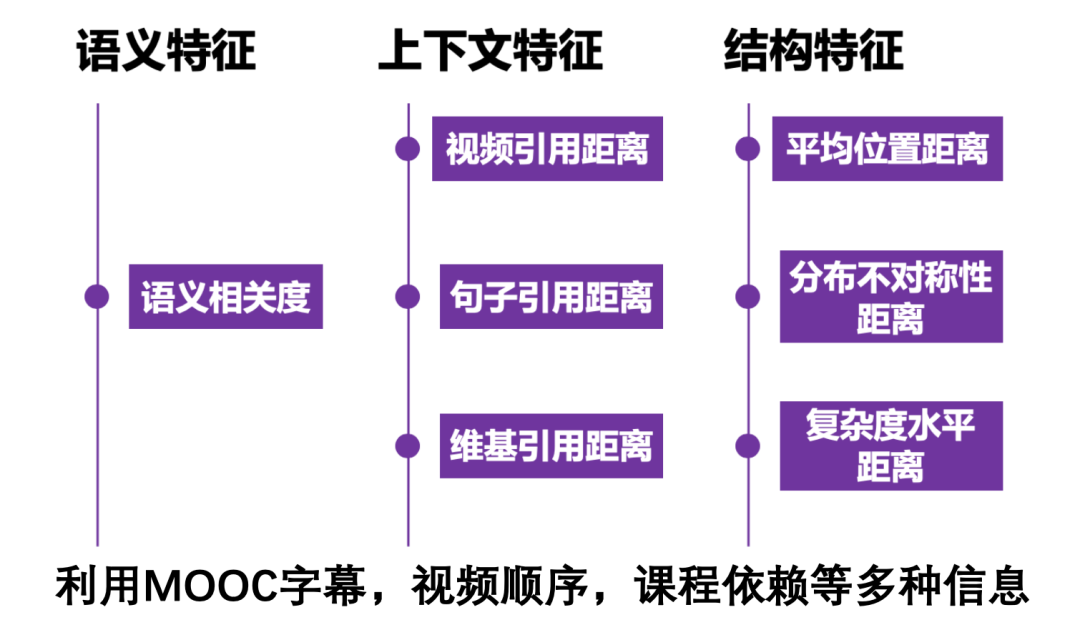

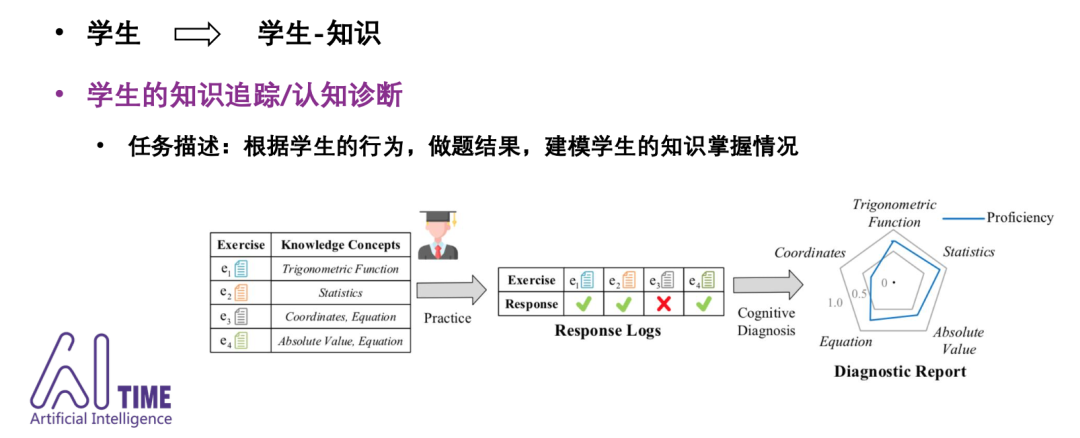
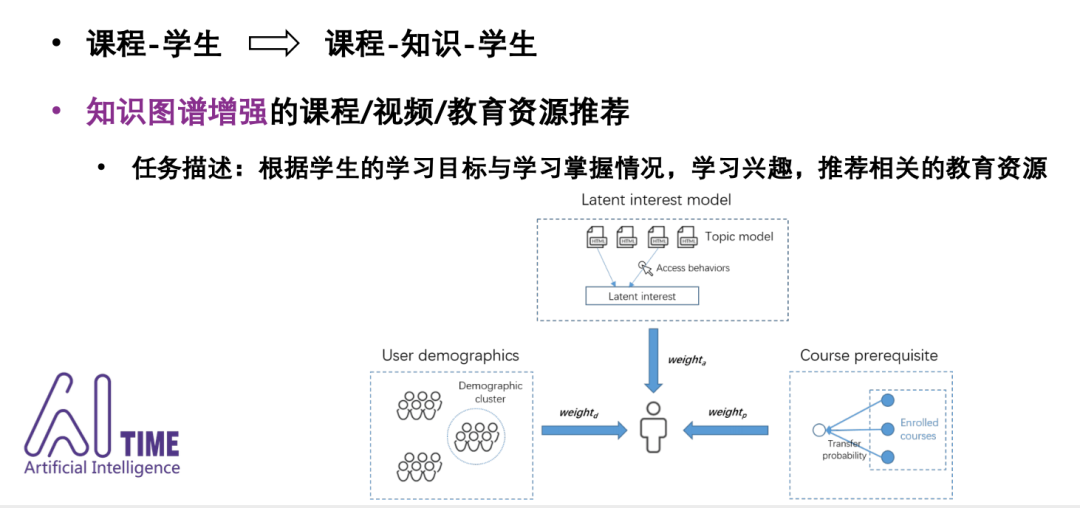
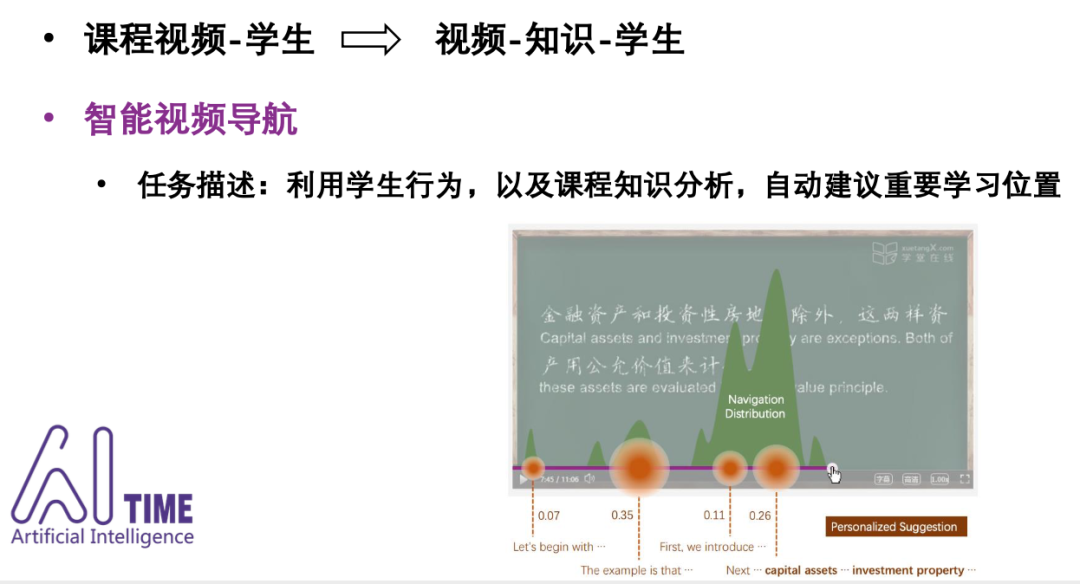
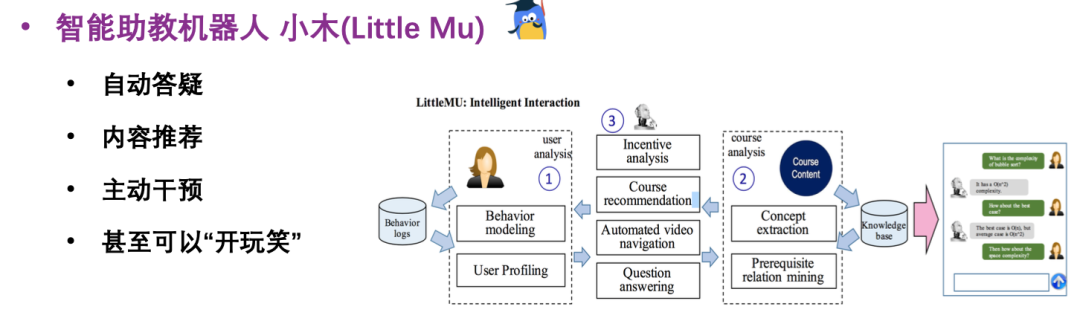
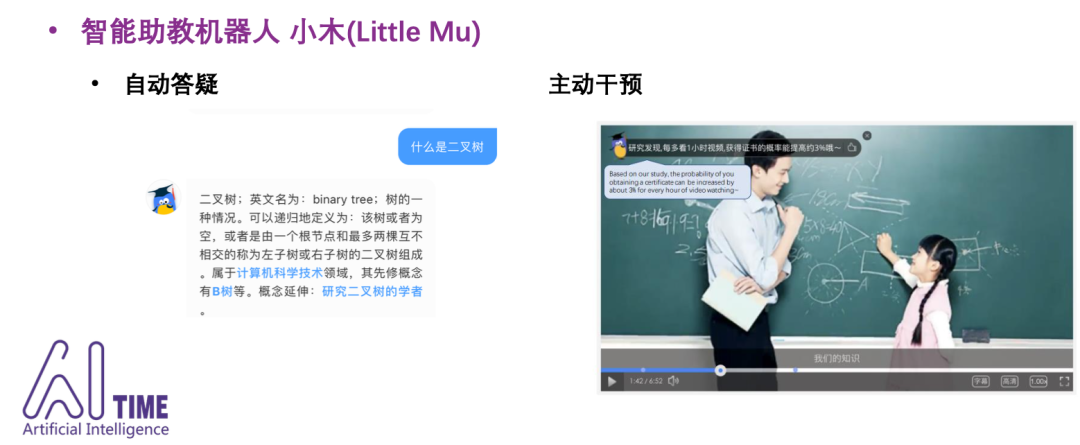
-
比如MOOC本身虽是一个独立的学习场景,但是能不能帮助学生找到志趣相投的同学,形成一个社交网络相关的研究呢? -
再比如通过知识在课程资源中的分布以及学生学习课程资源后的反馈学习结果,是否能够对于这些知识进行组织挖掘,为老师接下来改善课程或是补充内容提供建议呢? -
对于一个正在学习的用户是否在课前提供一些思考题,或者课后出一些重要的练习题,能够帮助他更好地掌握知识概念? -


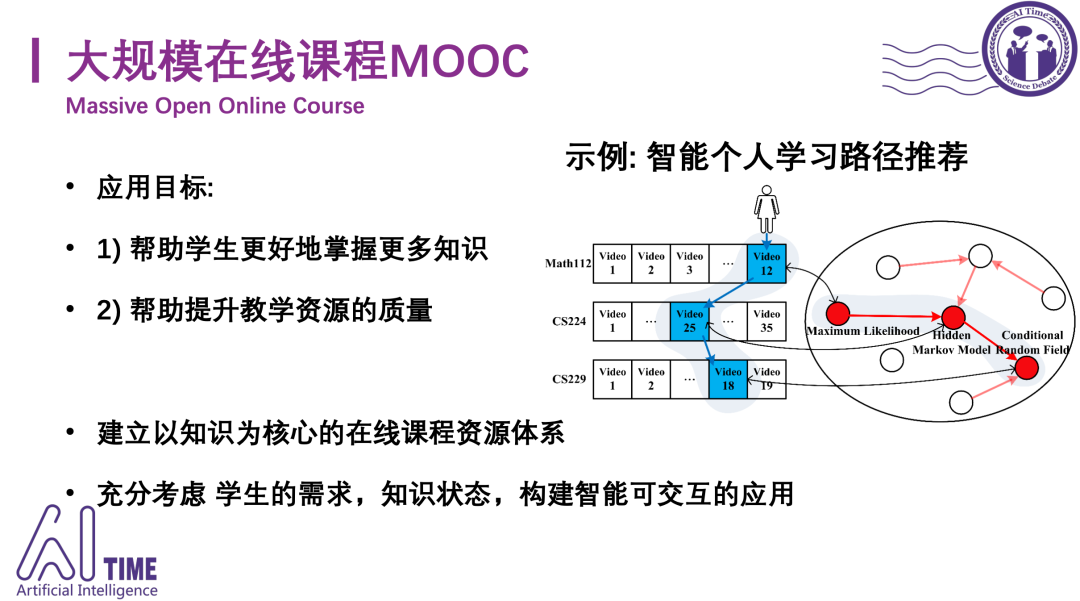
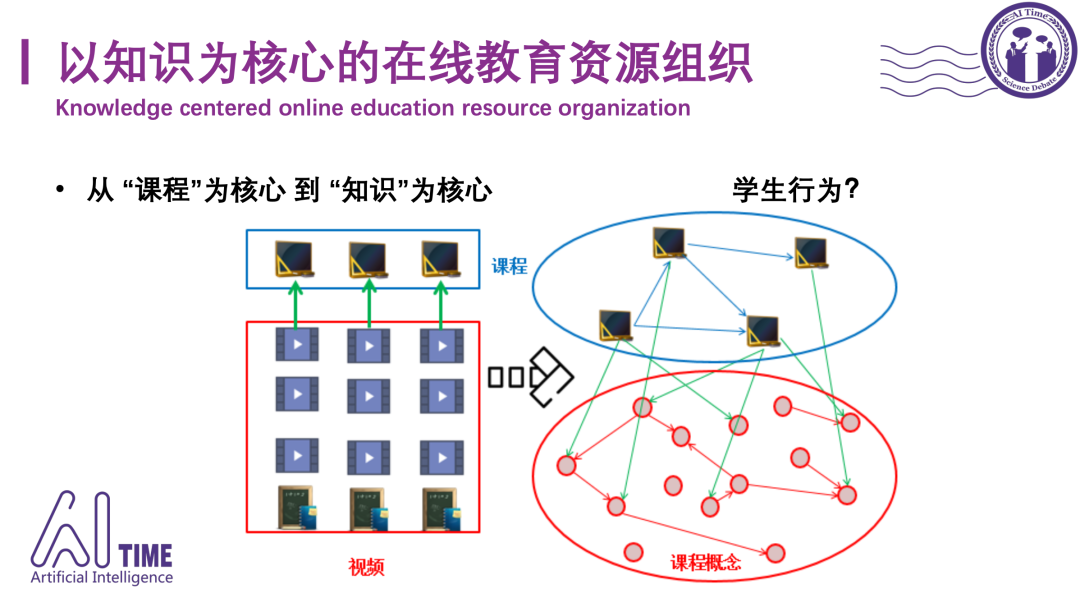
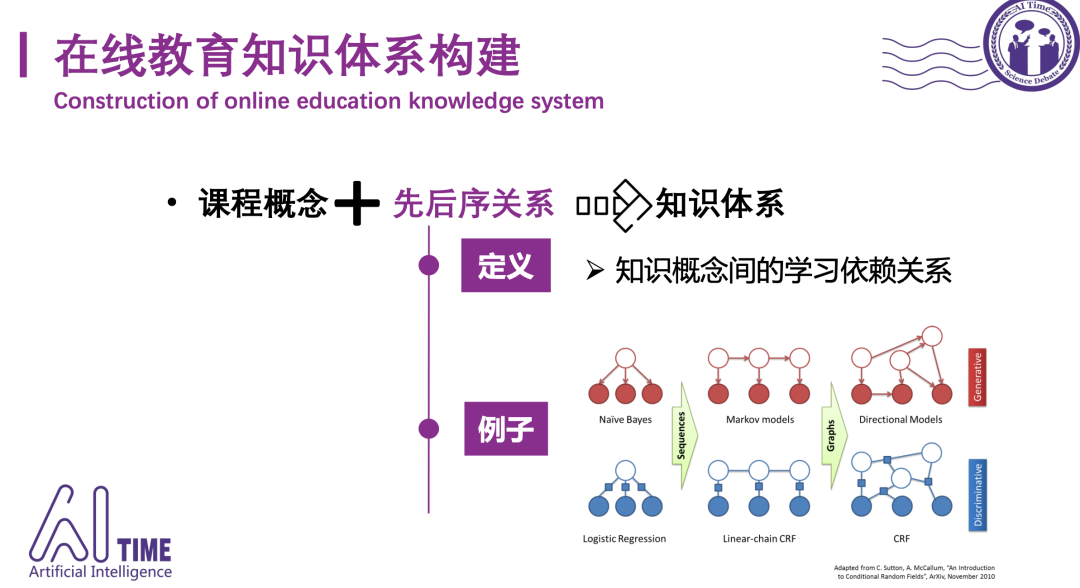
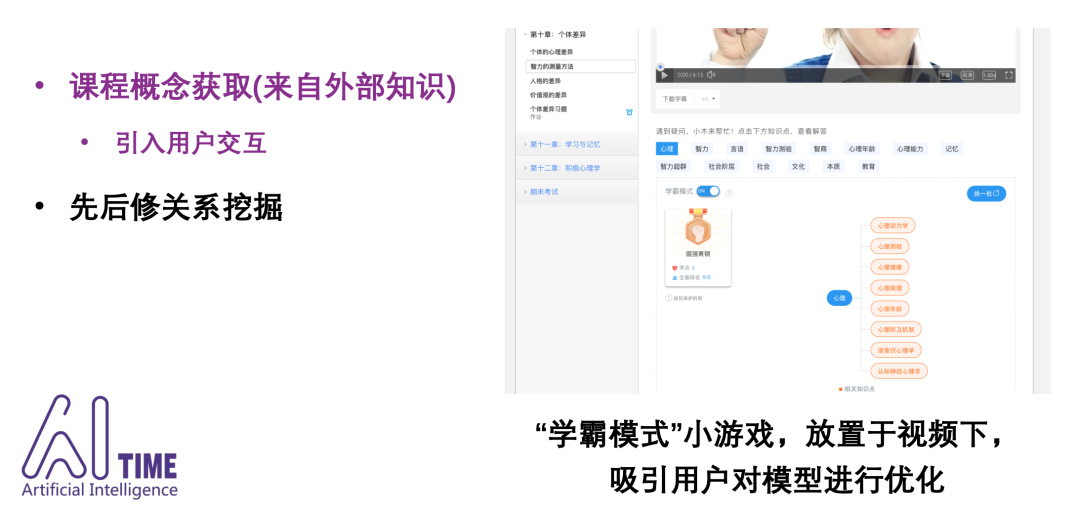
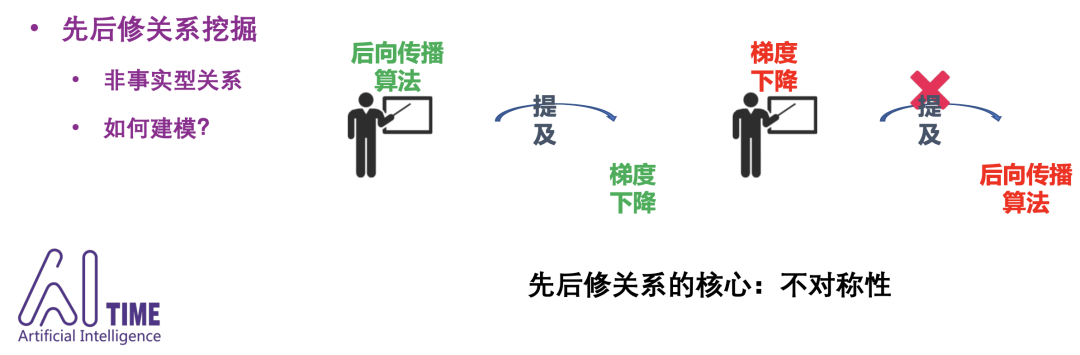
知识存在于课程之中,想让学生获取一个递进的学习路线,如何判断一个知识点的前置知识点是什么?

判断知识点的前置知识点,请参考“Prerequisite Relation Discovery”这个任务,专门做知识点之间的依赖,我们团队有一篇Prerequisite Relation Learning for Concepts in MOOCs. ACL17,可以follow和更新一下。

如何评估自己推荐的知识对用户来说,是有趣的或者有用的?
推荐的知识是否有用,最好的评测方法是通过对用户的最终表现进行追踪得到,但如果是实际使用,因为数据集是确定的,一个可行的思路是用Knowledge Tracing的模型来做,比如预测学生学了这个概念,对于某些重要的题目是否做对了。
对于中学比如数学科的知识图谱构建,目前有已经做好的可以参考么?
推荐我们实验室做的一个术语Taxonomy:http://moocdata.cn/mooc_knowledge_graph/MOOC%20Knowledge%20Graph,里面数学领域有7721个概念。以及http://www.edukg.cn/是一个非常大的基础教育知识图谱,主要面向中小学,是清华的许斌老师团队做的。
(直播回放:https://www.bilibili.com/video/BV14C4y1a7V7)
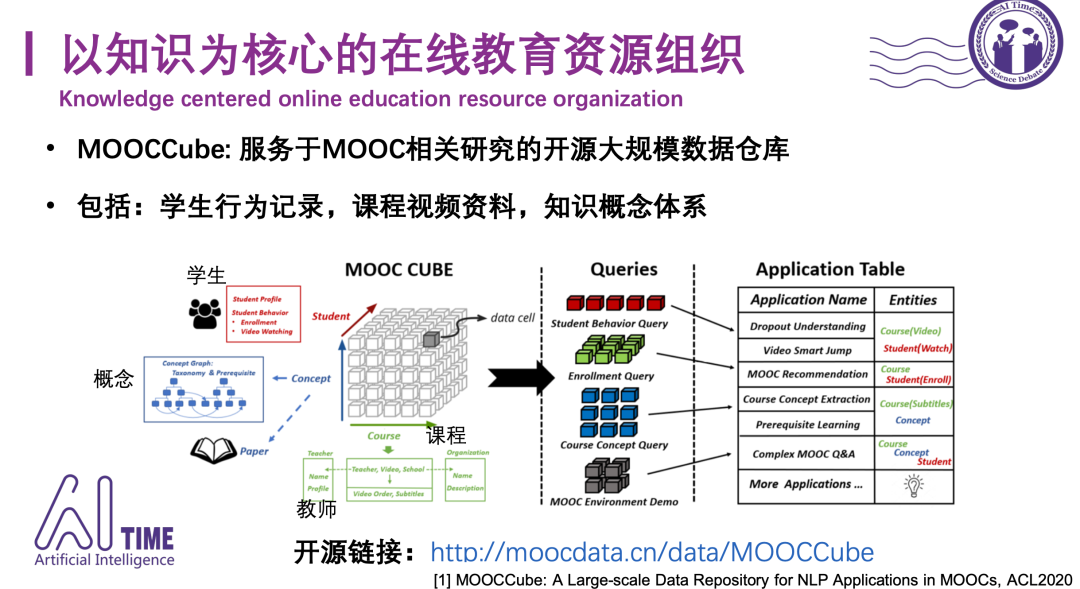
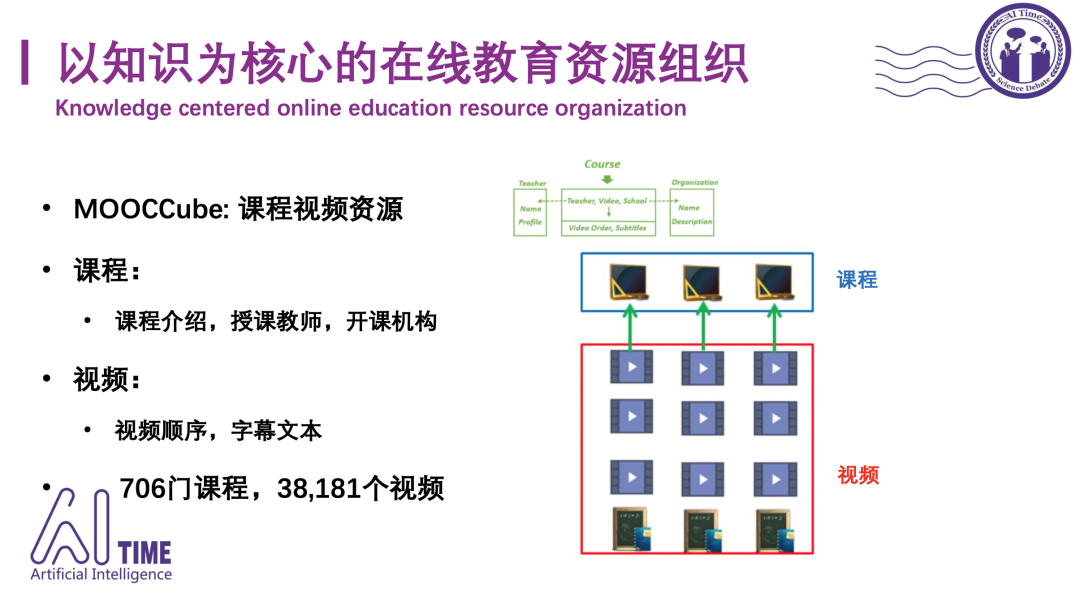
[2] MOOCCube开源链接:http://moocdata.cn/data/MOOCCube
MOOCCube: A Large-scale Data Repository for NLP Applications in MOOCs, ACL2020
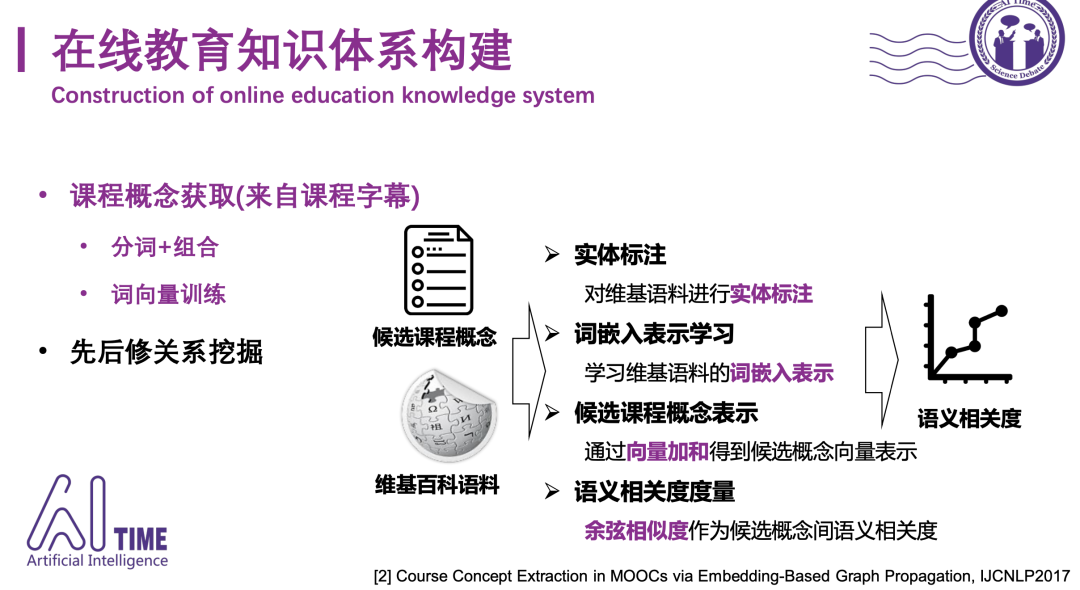
[3] Course Concept Extraction in MOOCs via Embedding-Based Graph Propagation, IJCNLP2017
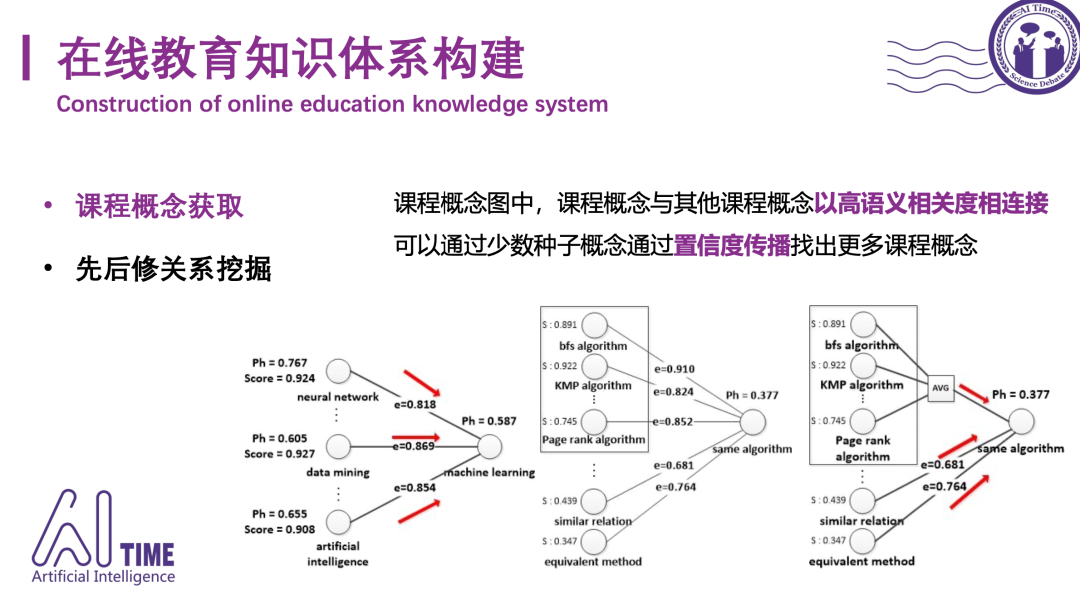
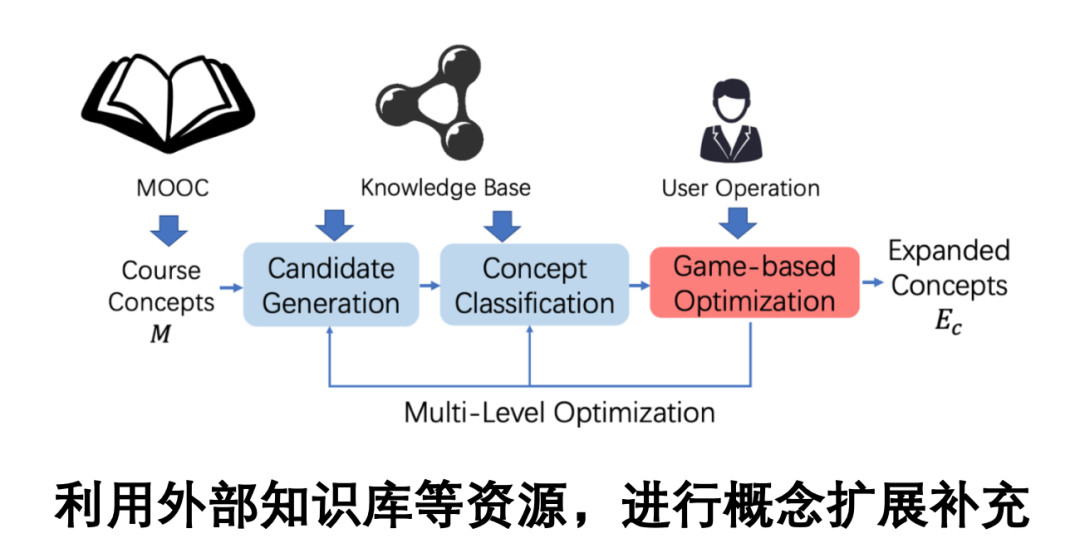
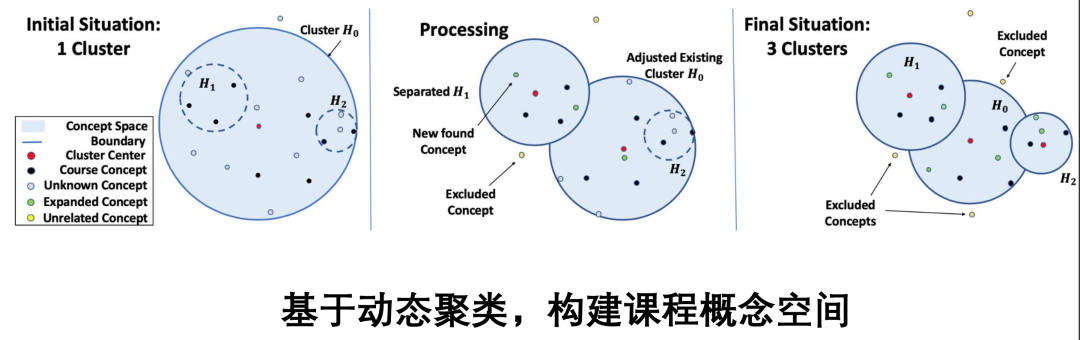
[4] Course Concept Expansion in MOOCs with External Knowledge and Interactive Game, ACL2019
[5] Prerequisite Relation Learning for Concepts in MOOCs. ACL2017





点击“阅读原文”下载本次报告PPT!

登录查看更多
相关内容

Arxiv
7+阅读 · 2019年2月8日





相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2019年2月8日