【斯坦福CS224N硬核课】Transformers模型详解,50页ppt

注意力(Attention)机制[2]由Bengio团队与2014年提出并在近年广泛的应用在深度学习中的各个领域,例如在计算机视觉方向用于捕捉图像上的感受野,或者NLP中用于定位关键token或者特征。谷歌团队近期提出的用于生成词向量的BERT[3]算法在NLP的11项任务中取得了效果的大幅提升,堪称2018年深度学习领域最振奋人心的消息。而BERT算法的最重要的部分便是本文中提出的Transformer的概念。
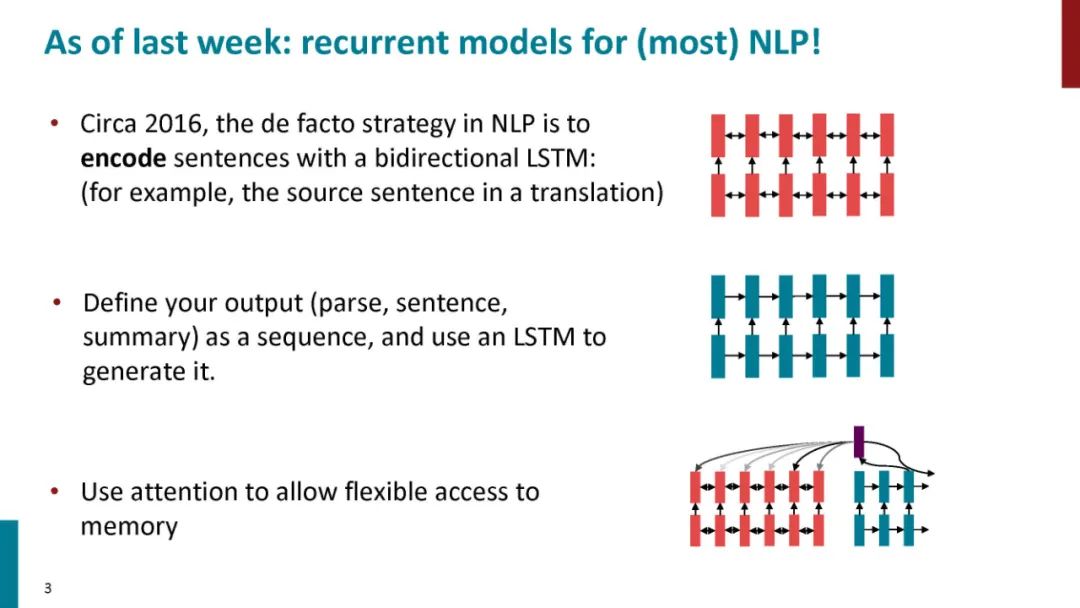
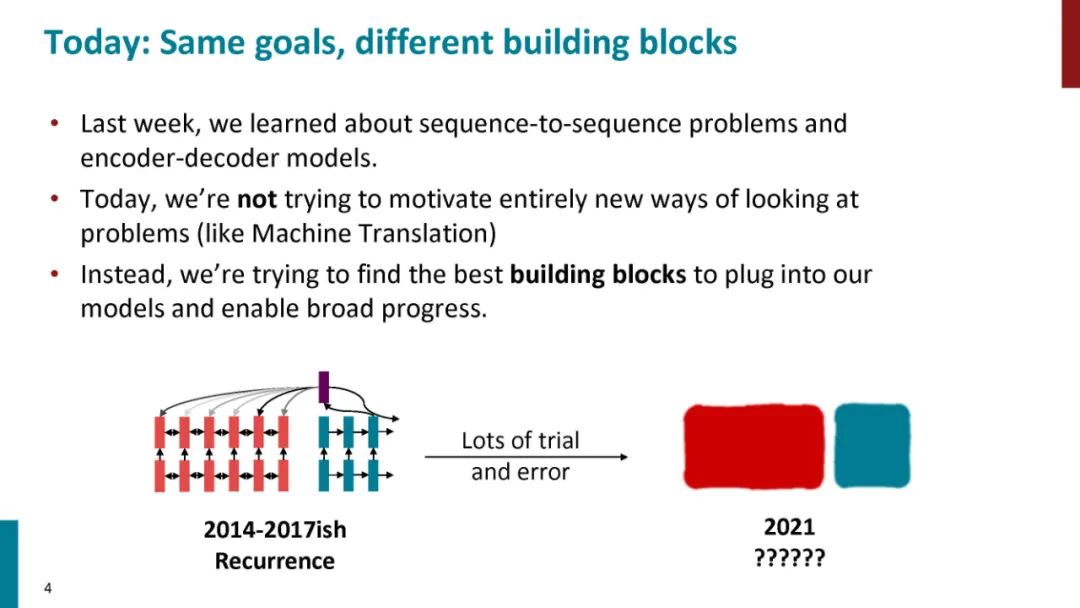
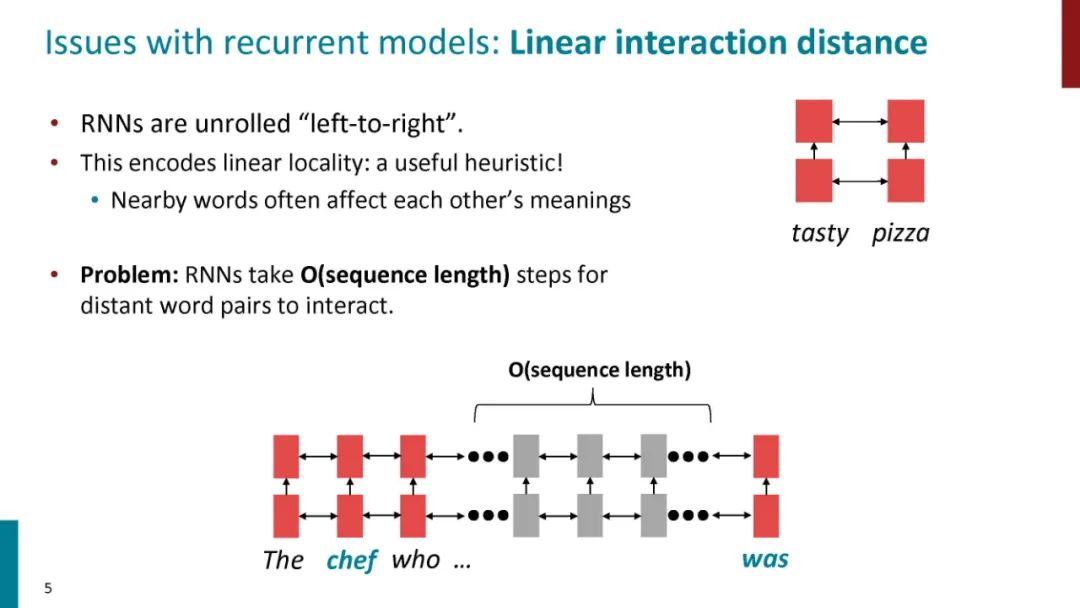
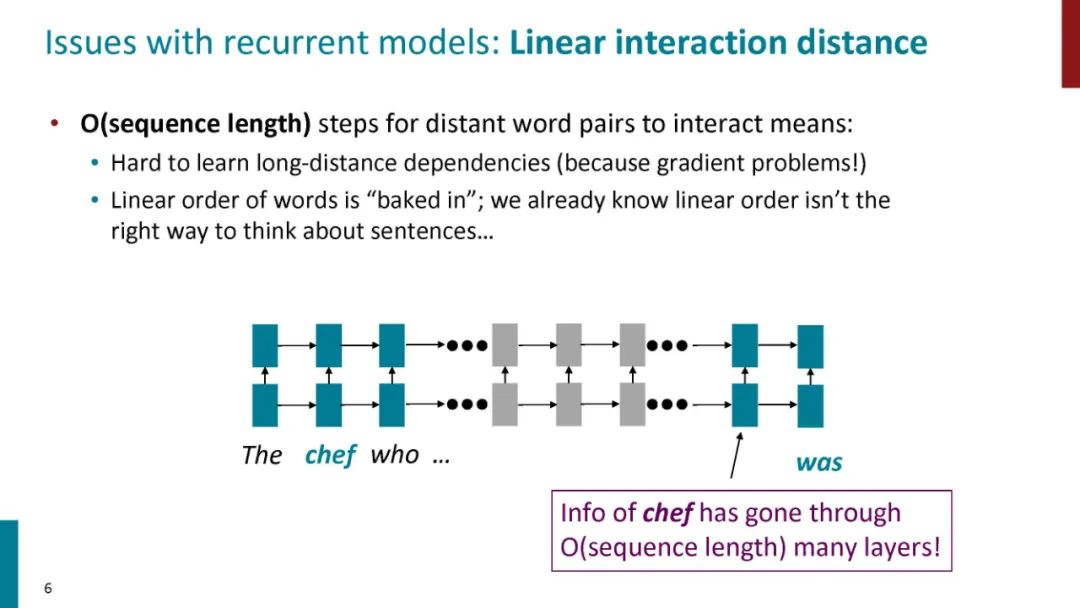
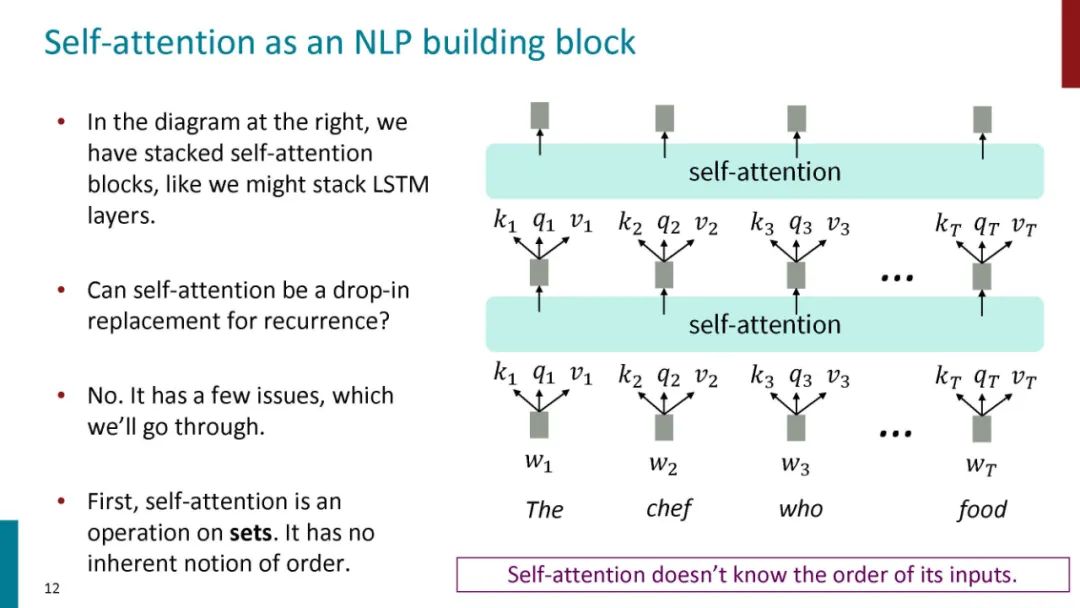
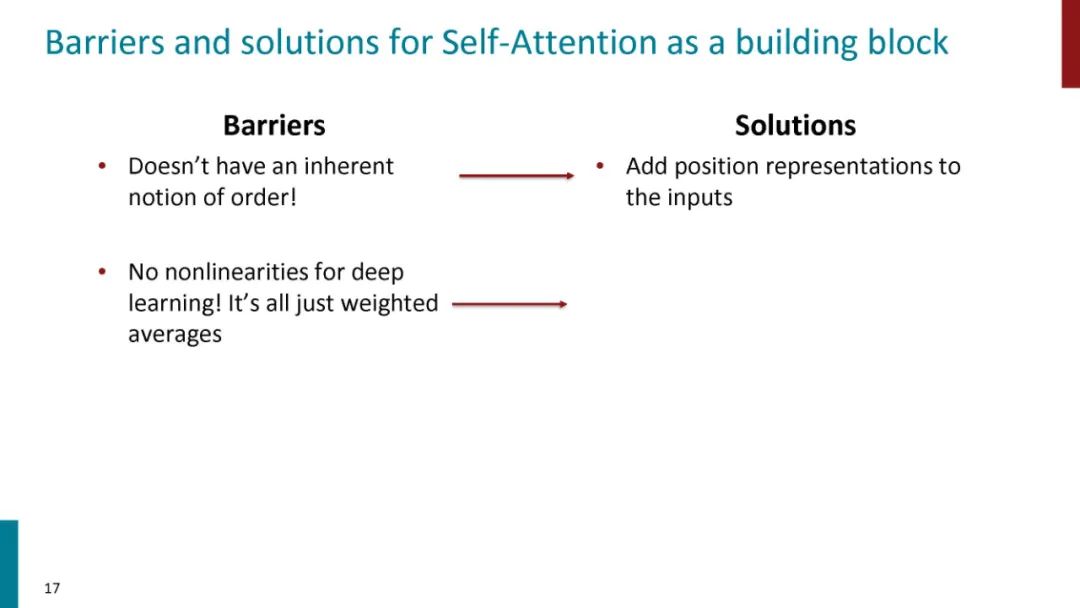
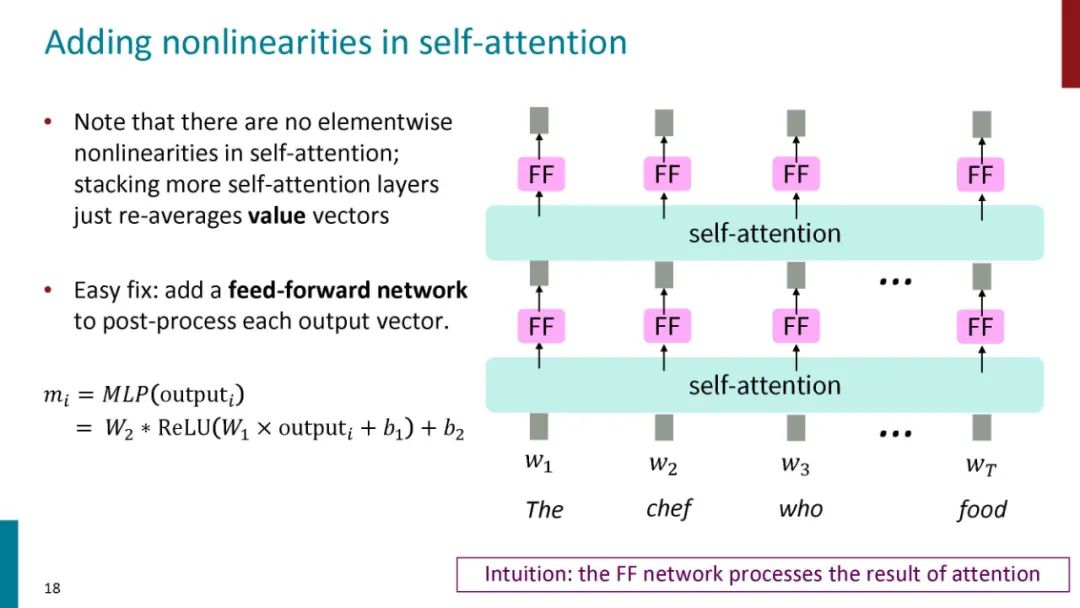
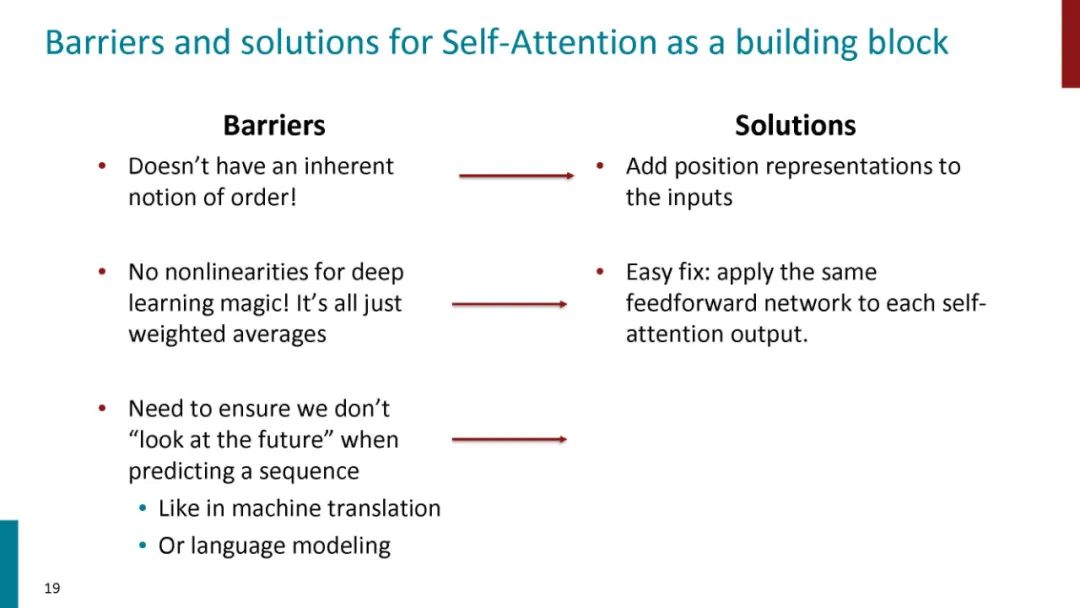
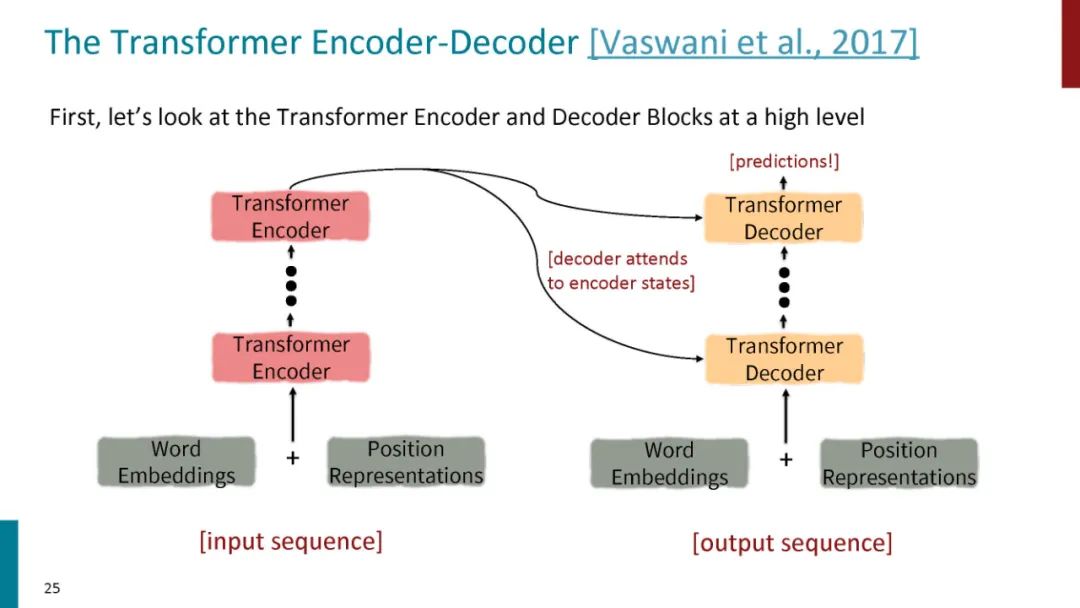
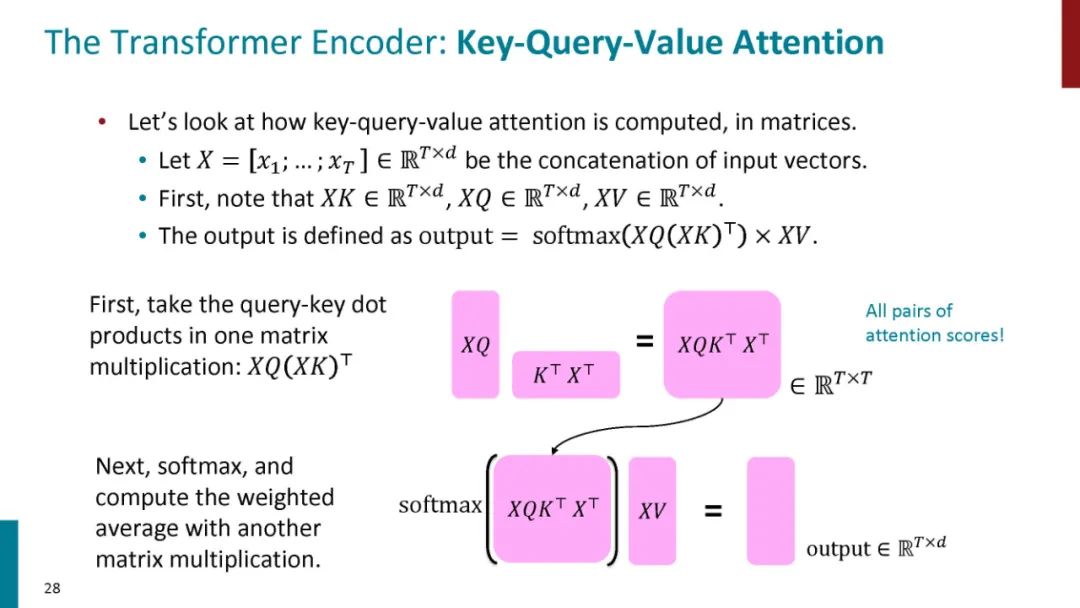
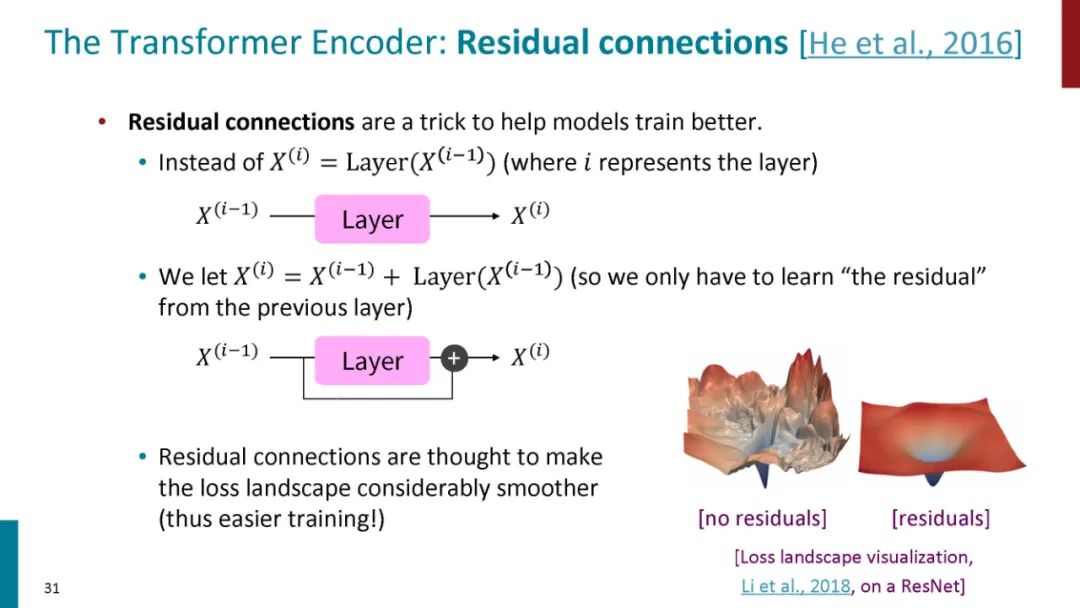
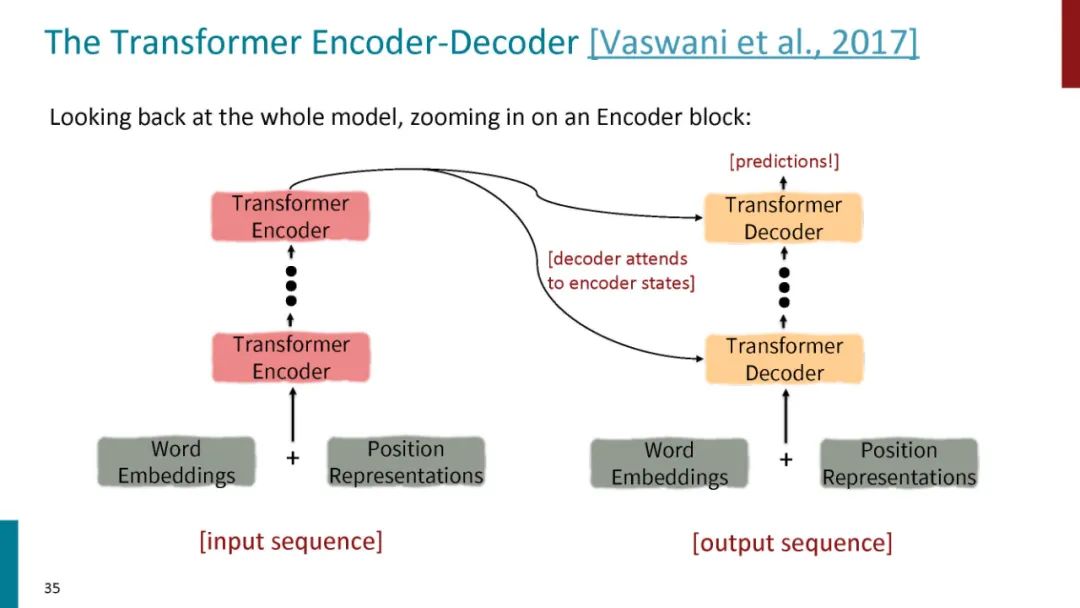
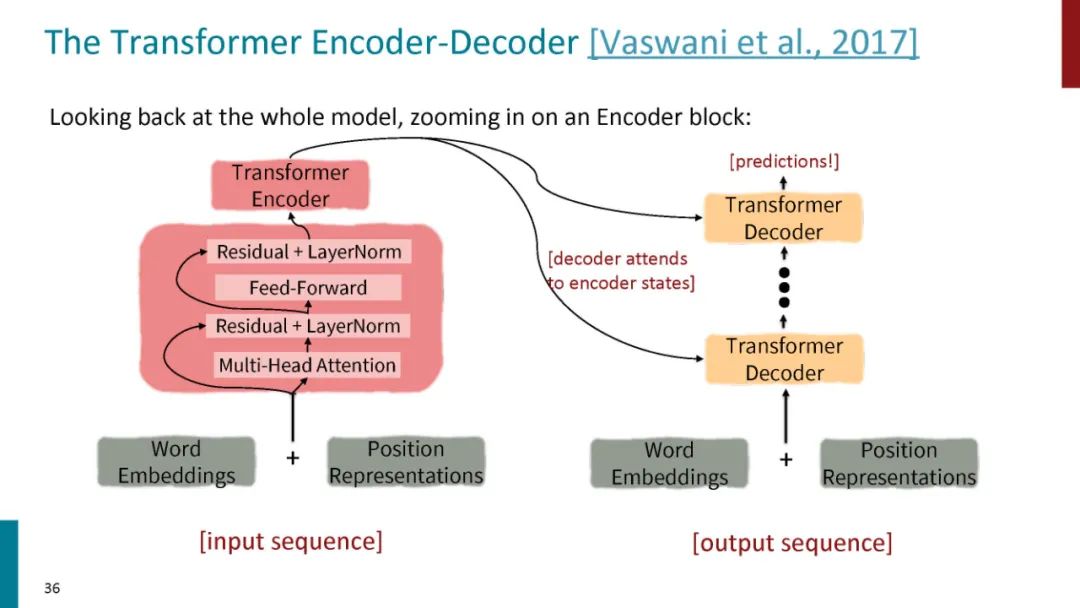
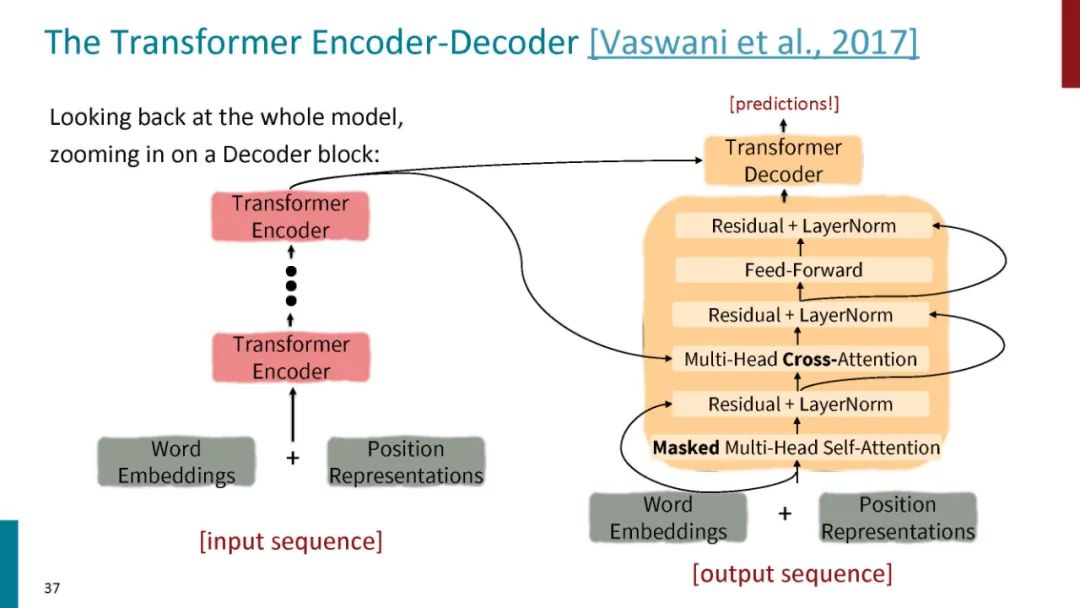
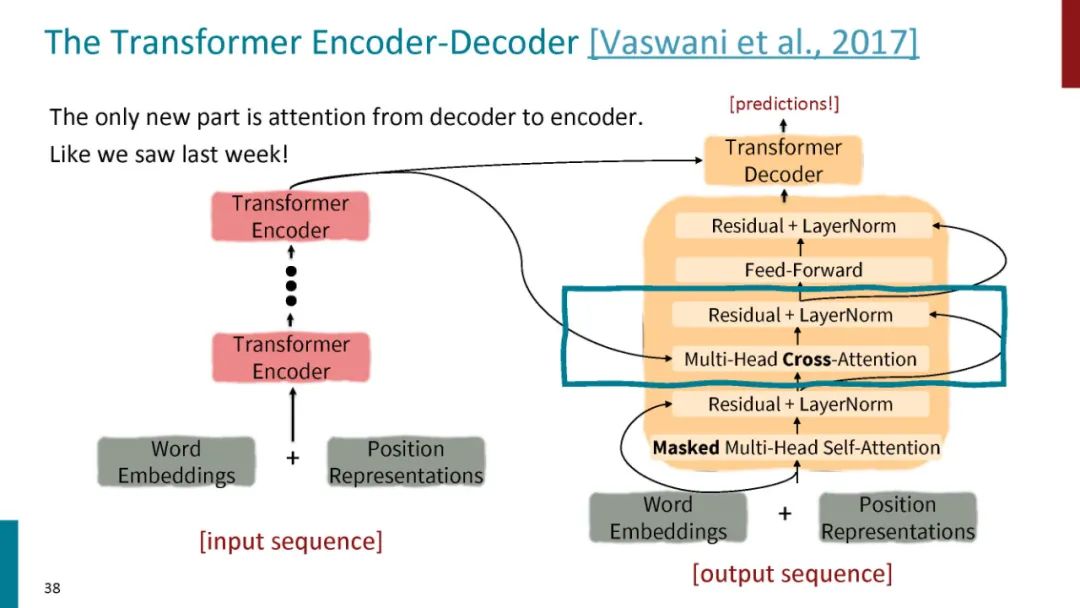
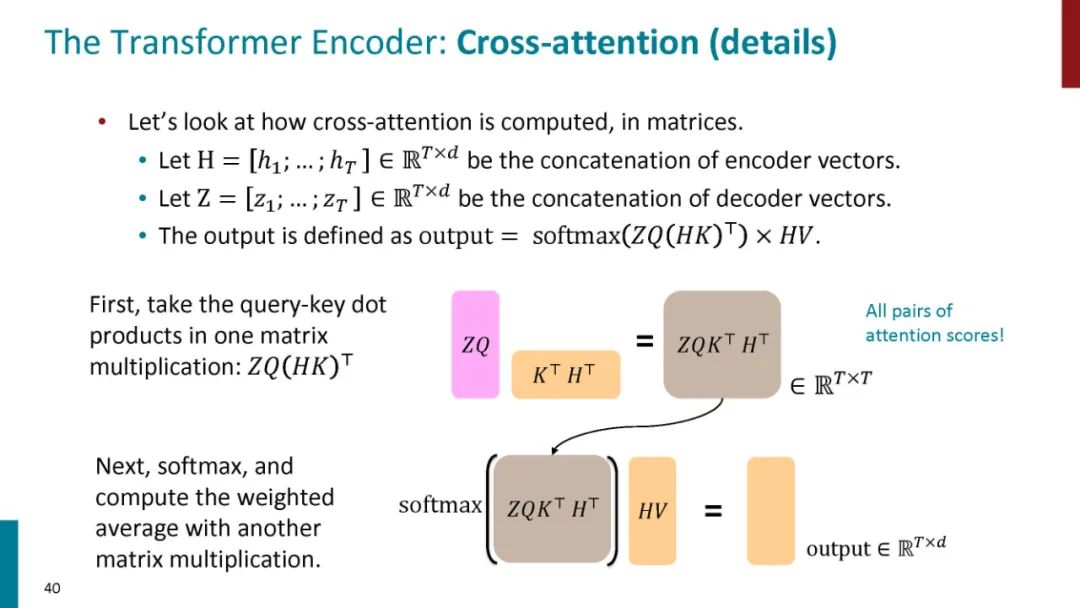
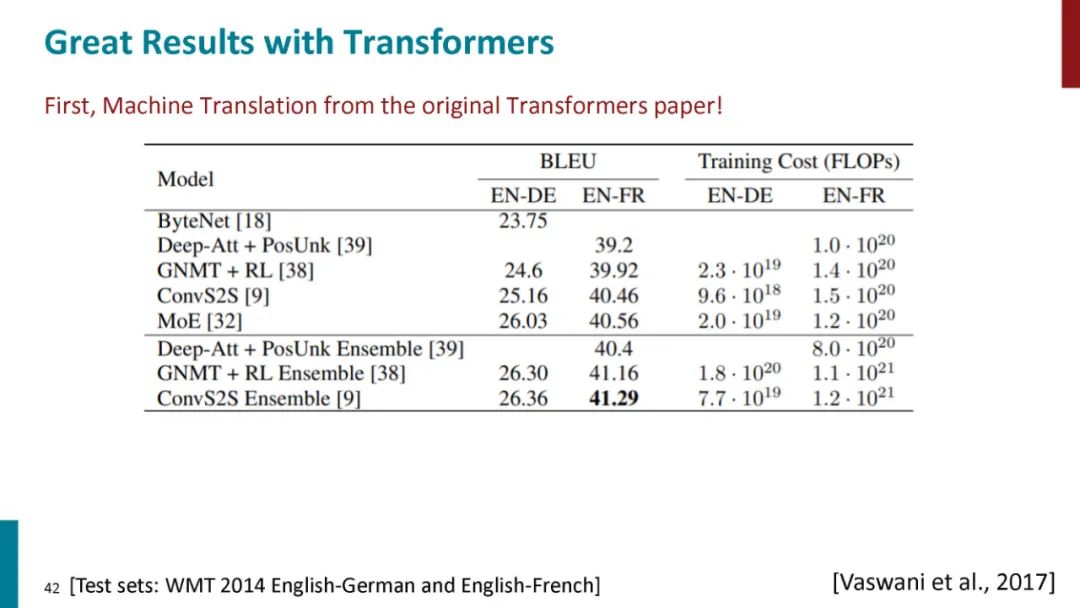
正如论文的题目所说的,Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder,并在机器翻译中取得了BLEU值得新高。
http://web.stanford.edu/class/cs224n/index.html#schedule























专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“T50” 可以获取《【斯坦福CS224N硬核课】Transformers模型详解,50页ppt》专知下载链接索引



登录查看更多
相关内容





相关VIP内容
相关资讯
相关论文