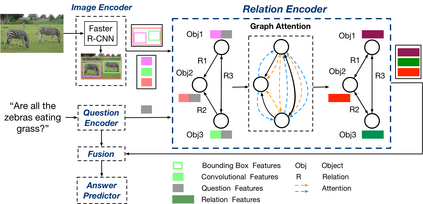
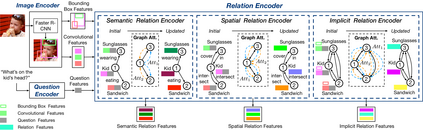
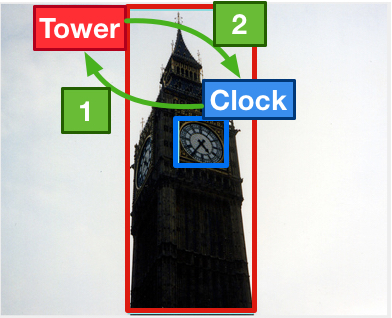
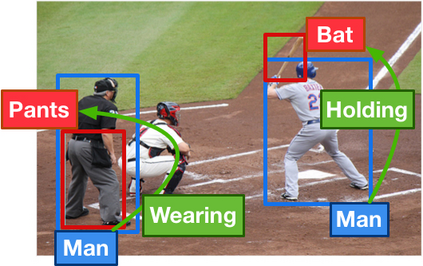
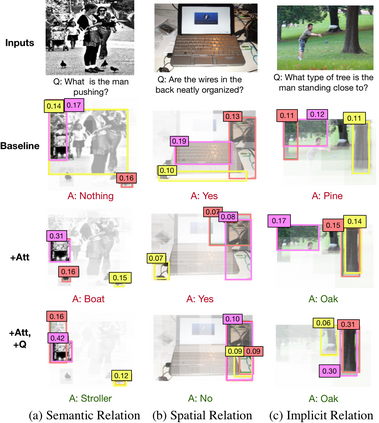
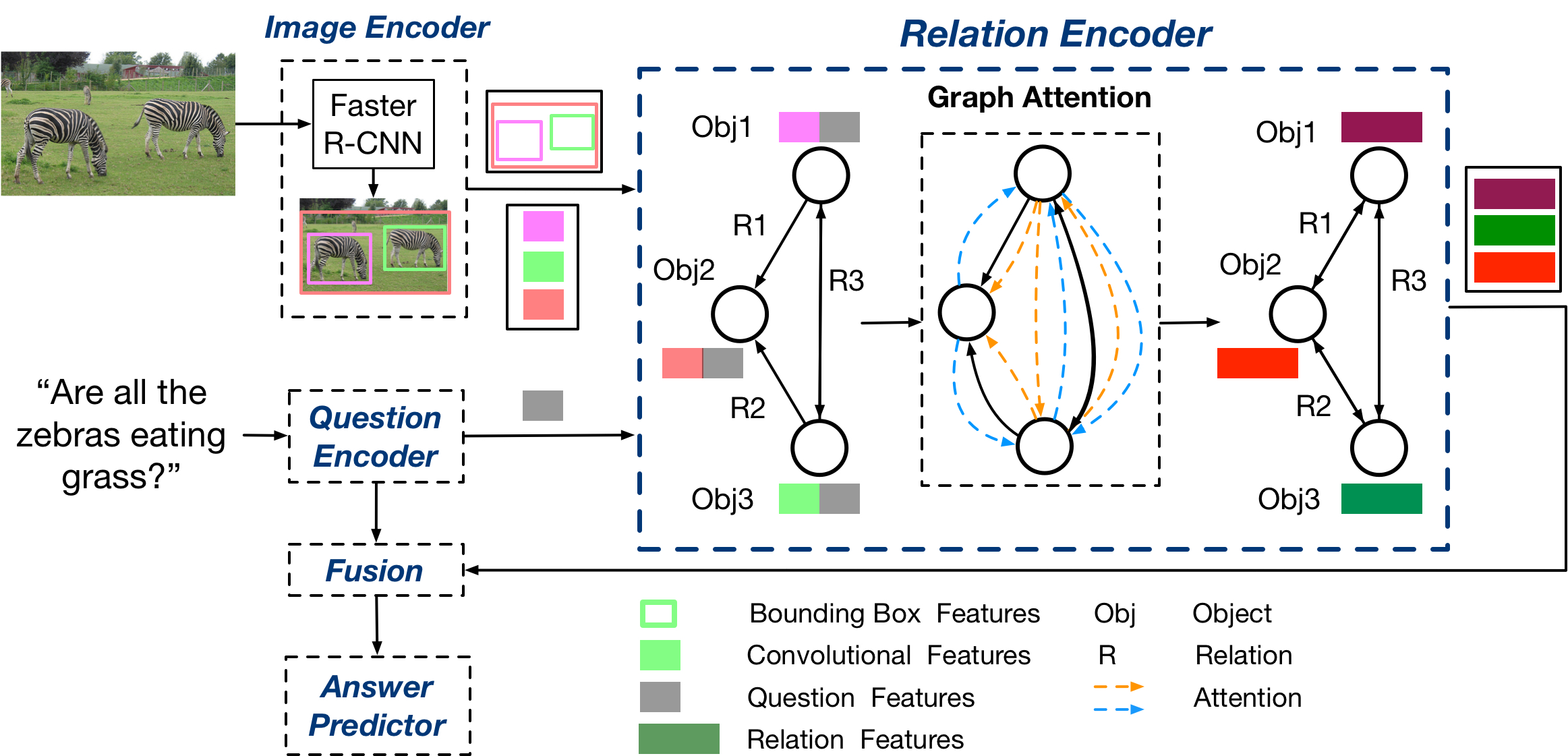
In order to answer semantically-complicated questions about an image, a Visual Question Answering (VQA) model needs to fully understand the visual scene in the image, especially the interactive dynamics between different objects. We propose a Relation-aware Graph Attention Network (ReGAT), which encodes each image into a graph and models multi-type inter-object relations via a graph attention mechanism, to learn question-adaptive relation representations. Two types of visual object relations are explored: (i) Explicit Relations that represent geometric positions and semantic interactions between objects; and (ii) Implicit Relations that capture the hidden dynamics between image regions. Experiments demonstrate that ReGAT outperforms prior state-of-the-art approaches on both VQA 2.0 and VQA-CP v2 datasets. We further show that ReGAT is compatible to existing VQA architectures, and can be used as a generic relation encoder to boost the model performance for VQA.
翻译:为了回答关于图像的语义复杂问题,视觉问答模型需要充分了解图像中的视觉场景,特别是不同对象之间的交互动态。我们建议建立一个图像注意网络(ReGAT),通过图形关注机制将每个图像编码成图表和模型多类型跨对象关系,学习问题适应关系表征。探索了两种类型的视觉对象关系:(一) 代表几何位置和对象间语义互动的外向关系;和(二) 捕捉图像区域之间隐藏动态的隐性关系。实验表明,RGAT在VQA 2.0和VQA-CP v2数据集上都比先前的状态方法更完善。我们进一步表明,ReGAT与现有的VQA结构相容,可以用作通用关系编码器,用以提升VQA的模型性能。