如何基于谷歌的最强 NLP 模型进行影评分析?

谷歌此前发布的NLP模型BERT,在知乎、Reddit上都引起了轰动。其模型效果极好,我们在论文里做的几个实验数据集都被轰平了。要做那几个数据集的人可以洗洗睡啦,直接被明明白白地安排了一波。

坊间流传BERT之于自然语言处理有如ResNet之于计算机视觉。谷歌还是谷歌呀,厉害!以后做NLP的实验就简单多了,可以先用BERT抽特征,再接几层客制化的神经网络后续实验,可以把BERT看作是类似于word to vector那样的工具。有人在知乎(https://www.zhihu.com/question/298203515/answer/509470502)上整理了跑一次BERT的成本:
For TPU pods:
4 TPUs * ~$2/h (preemptible) * 24 h/day * 4 days = $768 (base model)
16 TPUs = ~$3k (large model)
For TPU:
16 tpus * $8/hr * 24 h/day * 4 days = 12k
64 tpus * $8/hr * 24 h/day * 4 days = 50k
For GPU:
"BERT-Large is 24-layer, 1024-hidden and was trained for 40 epochs over a 3.3 billion word corpus. So maybe 1 year to train on 8 P100s? "
这还只是跑一次的时间,试想一下谷歌在调参、试不同神经网络结构时该需要多少时间与运算资源,太可怕了。
不禁让人感慨,深度学习已经变为大公司之间的军备竞赛,也只有谷歌这样的大公司才能做出这么伟大的模型,那是不是意味着我们普通人就没机会了呢?喜大普奔的是谷歌已经把训练好的模型公布出来,和大家分享他们的成果。我们可以运用大公司提前训练好的模型做迁移学习,用于客制化的应用。
本文想通过一个实际案例来检验一下提前训练好的BERT模型的威力,在已经训练好的BERT模型上再连几层神经网络做迁移学习。我们用的数据来源是Kaggle上的一个豆瓣影评分析数据集,目标是训练出一个模型,输入给模型一条影评的文字,模型能正确输出这条影评所对应的评分。

数据集
这个豆瓣电影短评数据集(https://www.kaggle.com/utmhikari/doubanmovieshortcomments/)里面一共有28部电影,总共200多万笔影评,每笔影评有对应的文字以及用户给电影的评分(最高5分,最低1分)。下面是一些简单的范例:
前处理的时候,我们先把每条影评的标点符号去掉,然后用Jieba断词,Jieba是一个很方便的中文断词函数库,安装也很方面直接用PIP安装就好。
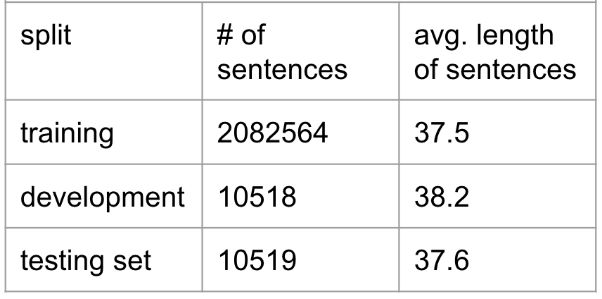
最后把数据切为training,testing和validation set三部分,下表是三个set的一些简单统计量:

模型结构
第一步,我们先用“Jieba”将影评断词,再把每个词用一个one-hot vector表示。
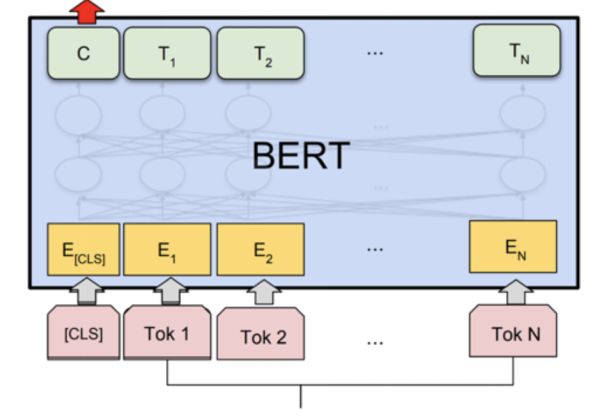
第二步,再把每条影评对应的one-hot vector丢到如下图的BERT模型抽出特征。
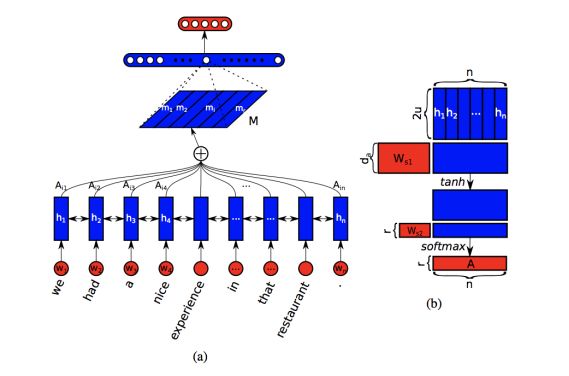
第三步,再把抽出的特征丢进我们客制化设计的神经网络,最后输出网络的预测。网络的预测是1-5分,我们分别做了回归和分类两个实验。分类的输出结果是1-5分5类当中的某一类,回归输出结果是介于1-5之间的一个数值。我们会用到如下图所示的Bengio在2017年提出的自注意力模型做一些语义分析。
第四步,定义损失函数,固定BERT的参数不变,再用梯度下降法更新我们客制化设计的网络。
PS:由于BERT和self-attention模型结构较为复杂,而且本文的目的是探讨如何用BERT做迁移学习,所以我们不会赘述模型结构,我们会在文末附上论文链接,感兴趣的小伙伴可以去看看。

实验结果
BERT 分类
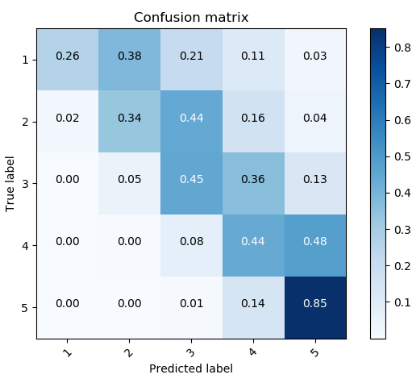
分类准确率:61%
混淆矩阵:
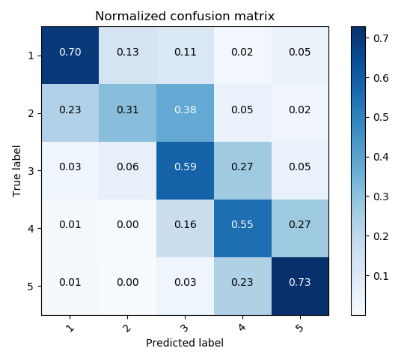
以第1行第二列的0.13为例:意思是真实标签是第一类,被分类为第二类的占总的第一类的个数的比例是0.13。可以看到1分,5分的大部分例子都能分类正确。大部分分类不正确的情况是被分到相邻的等级了,例如真实标签是2分的被分类为3分或是真实标签是3分的被分类为2分。这种情况是合理的,针对某一条特定的影评,就算是人去预测,也很难斩钉截铁地判定为是2分还是3分,所以也难怪机器分不出来。
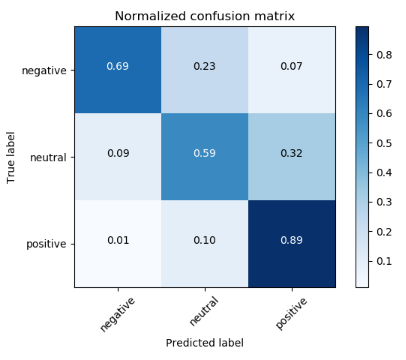
我们对评价标准做了一点修改,将误判为相邻评分的例子判别为正确,结果如下:
分类准确率:94.6%
混淆矩阵:
BERT 回归
同样的架构,我们修改了一下最后一层的输出,让模型预测相应影评的评分,输出一个实数值,重新训练了模型。如果是分类的实验,1分与5分这两个类别用数值表示的话都是一个one-hot的类别,体现在损失函数里没有差别,模型不会对二者区别对待。如果是回归的实验,模型的输出是一个实数值,实数值具有连续性,1分和5分二者分数的高低能在实数上得到体现。
下面来看看实验结果:
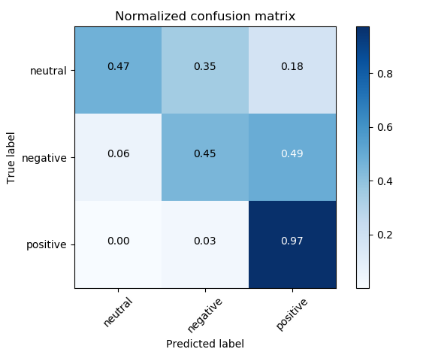
分类准确率:95.3%
混淆矩阵:
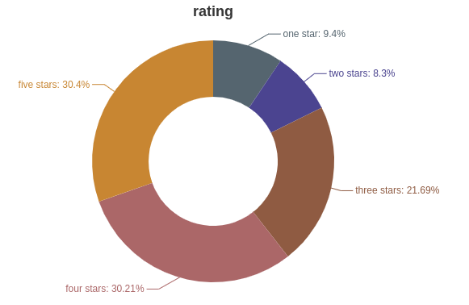
真实评分的分布:
模型预测评分的分布:
我们也对BERT出来的特征向量做了TSNE降维,可视化结果如下:
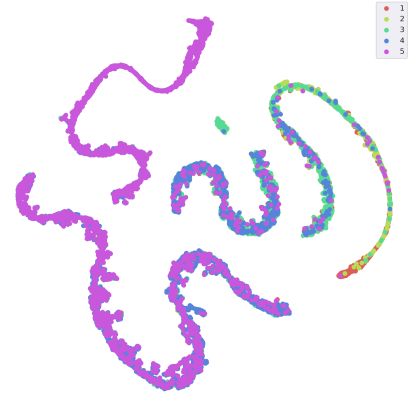
根据右上角的图例,不同的颜色代表不同的评分,比如紫色代表五分。每一个点都是一笔影评的高维特征降维后在二维平面上的体现。可以明显看出,不同评分的影评被归在了不同的群里。相近的评分,比如5分和4分、4分与3分会有一些重叠部分。
自注意力机制的一些可视化结果:


引入自注意力机制的模型在预测一句影评对应的评分的时候,能够先通过注意力机制抓取一句话中的重要部分,给重要部分很多的比重。上述几个例子就能看出来,再模型给一条影评5分的时候,会给“爆”、“动人”这样的字眼予以高亮。在给2分的时候,会给“一般”这样的字眼予以高亮。

案例分析
接下来我们针对疯狂动物城这部电影,做一些可视化分析,来呈现训练好之后的模型的效果。
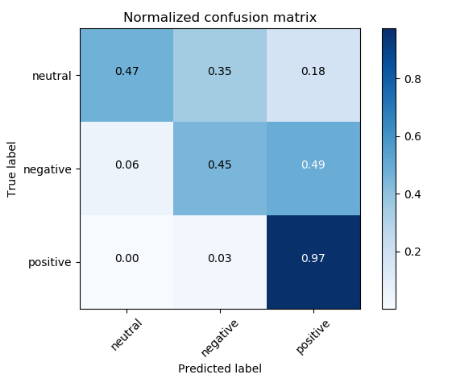
分类准确率:72.63%
混淆矩阵:
将误判为相邻评分的例子判别为正确的结果如下:
分类准确率:98.56%
混淆矩阵:
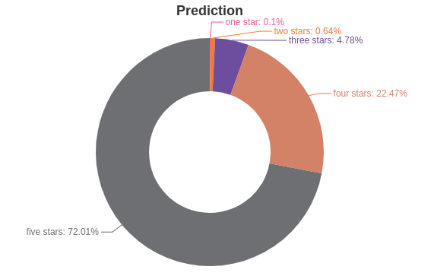
真实评分的分布:
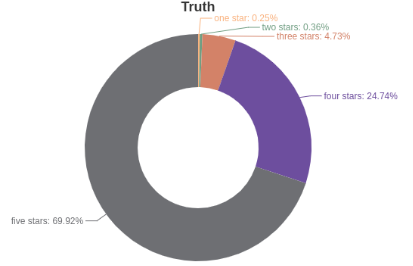
模型预测评分的分布:
TSNE降维后可视化结果:

自注意力机制可视化结果:

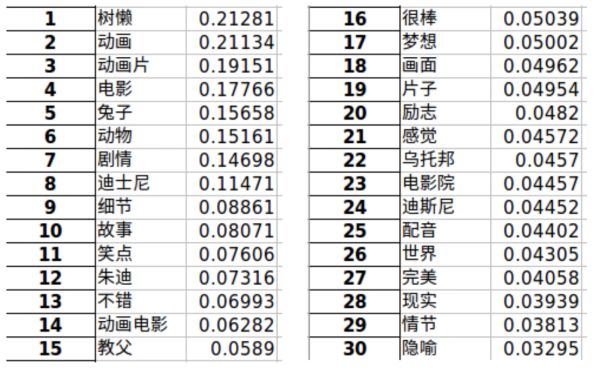
针对疯狂动物城这部电影,我们做了TF-IDF的词频分析。
词频前三十的词:
不同评分的高频词:
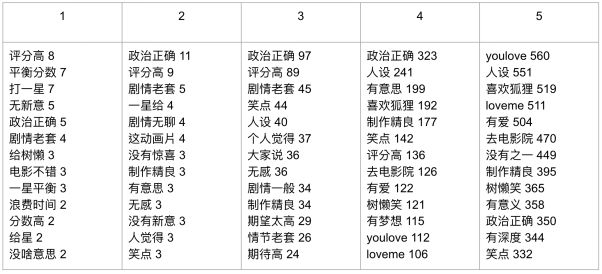
第一行的1-5是评分,下面的词后面的数字代表的是这个词的出现个数。
最后,用一张词云欢快地结束案例分析:


结论
本文用了目前自然语言界最强的模型BERT做迁移学习,效果看起来还挺okay的。
BERT模型可以很好地抽出文字的特征,用于后续的实验。如果小伙伴们有比较好的运算资源,可以把BERT当作是一个类似于word to vector的工具。
自注意力机制不光能提高模型的效能,同时引入此机制能大大加强模型的可解释性。
参考内容:
https://www.zhihu.com/question/298203515/answer/509470502
https://arxiv.org/abs/1810.04805
https://arxiv.org/abs/1703.03130
Github:https://github.com/Chung-I/Douban-Sentiment-Analysis
万水千山总是情,Github给颗星星行不行。我们想给大家提供可读性好、简单明了的代码,所以需要一点时间整理代码,但最近我们忙着准备期末考,等期末考一结束我们就把代码整理好再上传。感兴趣的小伙伴可以先收藏我们的Github,我们上传代码之后各位就可以直接下载参考咯。
作者:台湾大学网红教授李宏毅的三名爱徒,个人公众号井森堡,欢迎志同道合的小伙伴关注,本公众号会不定期更新机器学习技术文并附上质量佳且可读性高的代码。
声明:本文为作者投稿,版权归其个人所有,编辑郭芮。
热 文 推 荐
print_r('点个好看吧!');
var_dump('点个好看吧!');
NSLog(@"点个好看吧!");
System.out.println("点个好看吧!");
console.log("点个好看吧!");
print("点个好看吧!");
printf("点个好看吧!\n");
cout << "点个好看吧!" << endl;
Console.WriteLine("点个好看吧!");
fmt.Println("点个好看吧!");
Response.Write("点个好看吧!");
alert("点个好看吧!")
echo "点个好看吧!"
点击“阅读原文”,打开 CSDN App 阅读更贴心!





