谷歌可解释人工智能白皮书,27页pdf,Google AI Explainability Whitepaper
【导读】近几年,随着人工智能的迅速发展,人工智能对各行各业也产生了深远的影响。围绕人工智能建立的系统已经对医疗、交通、刑事司法、金融风险管理和社会的许多其他领域产生了巨大的价值。然而,人工智能系统仍然具有很多问题,为了保证人工智能系统的有效性和公平性,需要我们对人工智能具有深刻的理解和控制能力。所以,今天专知小编给大家带来的是Google可解释人工智能白皮书《AI Explainability Whitepaper》,总共27页pdf,主要介绍谷歌的AI平台上的AI的可解释性。
机器学习发展
人工智能的迅速发展导致现在我们现在所研究和使用的AI模型越来越复杂化,从手工规则和启发法到线性模型和决策树再到集成和深度模型,最后再到最近的元学习模型。
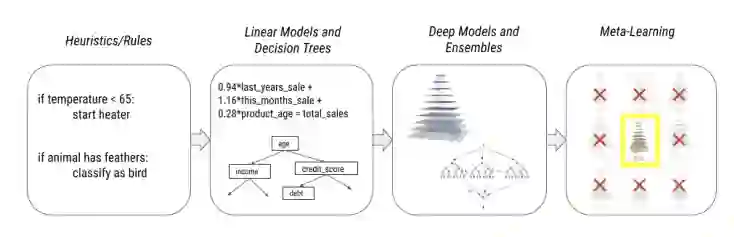
这些变化已经导致了多个维度上规范的变化:
可表达性(Expressiveness),使我们能够在越来越多的领域(如预测、排名、自主驾驶、粒子物理、药物发现等)拟合各种各样的功能。
通用性(Versatility),解锁数据模式(图像,音频,语音,文本,表格,时间序列等),并启用联合/多模式应用。
适应性(Adaptability ),通过迁移学习和多任务学习来适应小数据状态。
效率(Efficiency ),通过自定义优化硬件,如gpu和TPUs,使研究人员可以更快地训练更大更复杂更强大的模型。
然而,这些更复杂更强大的模型也变得越来越不透明,再加上这些模型基本上仍然是围绕相关性和关联建立的,这导致了以下几个挑战和问题:
虚假的关联性(Spurious correlations),这往往会妨碍模型的泛化能力,导致模型在现实场景下效果很差。
模型的调试性和透明性的缺失(Loss of debuggability and transparency),这会导致模型难以调试和改进,同时这种透明度的缺乏阻碍了这些模型的应用,尤其是在受到监管的行业,如银行和金融或医疗保健行业。
代理目标(Proxy objectives),这会导致模型在线下的效果与实际场景下的效果存在很大的出入。
模型的不可控(Loss of control)
不受欢迎的数据放大(Undesirable data amplification)
AI方法有:
简单(基于规则且可解释)
复杂的(不是可解释的)
根据应用不同,我们有明确的伦理、法律和商业理由来确保我们能够解释人工智能算法和模型如何工作。不幸的是,普通人可以解释的简单人工智能方法缺乏优化人工智能决策的准确性。许多提供最佳精度的方法,如ANN(人工神经网络),都是复杂的模型,其设计并不是为了便于解释。
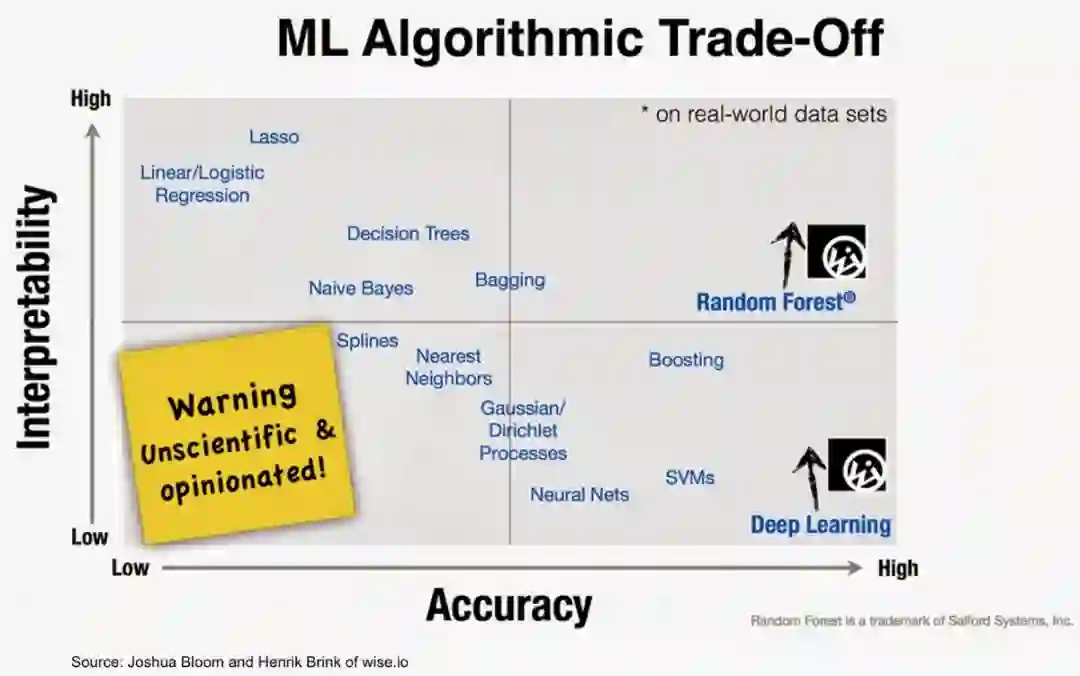
如图所示,人工智能方法的准确性和可解释性之间存在着一种相反的关系。两者之间的负相关关系如下: 解释性越大,准确性越低,反之亦然。
一些不太精确的模型仍然很受欢迎,因为它们具有可模拟性(因此人类可以重复它们)、完全可解释的计算过程(算法透明性)以及模型的每个部分都有一个直观的解释(可分解性)。
随着深度学习和强化学习的普及,对复杂神经网络的解释需求激增,推动了XAI工具的发展。最终目标: 实现负责任的、可追溯的、可理解的AIs。
可解释人工智能 XAI
这些挑战突出了对人工智能的可解释性的需求,以使人们可控的发展人工智能。
围绕人工智能建立的系统将影响并在许多情况下重新定义医疗干预、自动交通、刑事司法、金融风险管理和社会的许多其他领域。然而,考虑到上一节所强调的挑战,这些人工智能系统的有效性和公平性将取决于我们理解、解释和控制它们的能力。
自从几十年前专家系统出现以来,XAI(可解释的AI)领域已经复苏。本文对一种严谨的科学解释的机器学习,Doshi-Velez和Kim定义为“解释性或呈现在人类可以理解的术语的能力“利用韦氏字典的定义“解释”,它适应人类和智能代理之间的交互。
谷歌的人工智能可解释白皮书(AI Explainability Whitepaper)是谷歌云的人工智能解释产品的技术参考。它的目标用户是负责设计和交付ML模型的模型开发人员和数据科学家。谷歌云的可解释产品的目标是让他们利用对AI解释性来简化模型开发,并解释模型的行为。

白皮书的目录:
特征归因(Feature Attributions)
特征归因的限制和使用注意事项(Attribution Limitations and Usage Considerations)
解释模型元数据(Explanation Model Metadata)
使用What-if工具的可视化(Visualizations with the What-If Tool)
使用范例(Usage Examples)
参考链接:
https://cloud.google.com/ml-engine/docs/ai-explanations/overview
请关注专知公众号(点击上方蓝色专知关注)
后台回复“GXAI” 就可以获取27页《谷歌可解释人工智能白皮书》pdf的下载链接索引~