HawkEye:一种高效率的精细化大页管理方案

概要
随着现代硬件的内存越来越大,地址转换的开销变得不可忽视,大页(Hugepage)方案可以有效的减轻MMU压力,但是如何设计高效的大页管理方案,对于开发者而言仍然属于比较头疼的问题;近期的研究论文Ingens通过分析内核的页面访问模式和硬件性能计数器中>的数据,发现linux的大页管理策略在地址转换性能、缺页时延及内存膨胀(memory bloat)等方面都存在着较大的缺陷。
今年的ASPLOS 19提出的一篇新论文《HawkEye: Efficient Fine-grained
OS Support for Huge Pages》,提出了一种新型的大页管理方案HawkEye,HawkEye管理算法的主要思想包括:异步页面预清零、全零页面去重、页访问精细化跟踪以及通过硬件性能计数器的地址转换开销测量,研究数据表明,HawkEye拥有更高的性能以及更健全的功能,在各种工作负载下的表现都比linux更加优秀。
论文背景
随着应用程序使用到的内存范围越来越大,地址转换带来的开销变得不可忽视,多级TLB、多级cache等技术及现代架构已经支持了多种不同尺寸的大页,但是这更加需要OS在不同的工作负载之下,谨慎的选择大页的使用策略,特别是对于拥有两层地址转换的虚拟化场景,MMU的开销问题会变得格外严重。
尽管硬件提供了大量的支持,但是大页在一些重要应用程序上的性能表现仍然不能让人满意,主要原因来自于软件层面的大页管理算法。linux大页管理算法需要在地址转换开销、缺页时延、内存膨胀、算法本身的开销以及公平性之间做复杂的平衡,HawkEye暴露了当前大页管理方案的一些问题,并提出一套新的方案来解决它们。
首先简要介绍三种具有代表性的大页方案:Linux、FreeBSD以及Kwon等人的研究论文Ingens。
Linux
linux的透明大页通过以下两种方式来申请大页:
当系统存在足够的连续内存时,通过缺页异常直接分配大页给应用程序
通过khugepaged后台线程选择性的将4k小页合并为大页
linux只有在系统内存碎片化较高、缺页异常很难直接分配到大页时才会启动后台线程的合并功能,启动后khugepaged会按照FCFS(first-come-first-serve)策略选择进程进行合并,只有合并完一个进程后才会选择下一进程
FreeBSD
Freebsd支持多种size的大页,与linux不同的是,freebsd预留了一块连续的物理内存区域给缺页异常,但是只有当一个连续2M(以2M大页为例)中的所有4k页均被分配出去后,freebsd才将其合并为大页,并且在内存压力过大时,还会将大页中被释放的小页拆分出来还给os(同时也就不能再以大页管理),因此freebsd的方案拥有较高的内存使用率,但是会导致更多的缺页异常以及MMU开销
Ingens
从Ingens的论文来看,Ingens的作者指出了linux及freebsd大页管理方案中的缺陷,并且声明Ingens可以针对这些问题做出平衡,总的来说,Ingens拥有以下特点:
Ingens通过一种自适应的方案来平衡内存膨胀及地址转换的开销:在系统内存压力较小时,尽可能的给应用程序分配大页来提升性能;在系统压力较大时,则采用比较保守的大页合并阈值来避免出现大量的内存膨胀
为了避免由于同步页面清零带来过高的缺页时延,Ingens采用了专门的内核线程来异步完成大页分配
为了保证进程间公平性,Ingens将连续内存视为一种系统资源,使用共享分配的原则公平的为各个进程提供分配服务
HawkEye
作为一种操作系统级别的新型大页解决方案,HawkEye基于达成以下几个目标,提出了一种简洁且有效的算法:
在地址转换开销、内存膨胀、缺页异常时延中找到最佳平衡
尽可能的将大页分配给那些能够得到最大性能提升的应用程序在虚拟化场景下改进共享内存的行为机制
通过对各种典型应用进行测试(尽量挑选对大页诉求不同的应用),HawkEye的数据表明其与现有方案相比性能得到了显著的改善,同时增加的开销可以忽略不计(最坏情况下每核增加3.4%的cpu开销)
大页的常见问题
通常在设计大页管理方案时,会面临到以下几个问题之间的抉择和平衡,而相对于已有的操作系统解决方案,HawkEye在这些问题上采取的方式会显得更为有效
地址转换开销和内存膨胀
设计大页管理方案最大的问题在于如何权衡地址转换开销和内存膨胀,linux采用的同步大页分配策略能最大限度的减少MMU开销,但是往往当应用程序仅使用大页中的一小部分内存时,会导致大量的内存膨胀;freebsd的保守做法(只有当小页全部使用才合并为大页>)解决了内存膨胀问题,但却是以牺牲整体性能为代价。
Ingens的方案比较折中,它提出了一个概念用于测量系统的内存压力,称之为FMFI -- Free Memory Fragmentation Index(空闲内存碎片指数),当FMFI < 0.5 (内存碎片低)时,Ingens行为类似于linux,尽可能的给应用程序分配大页来提升性能,当FMFI > 0.5>(内存碎片高)时,Ingens转换为比较保守的策略,只有当90%的小页均被分配时,才会将其合并为大页,以此来缓解系统内存膨胀问题。
但是Ingens并不是最佳方案,因为其在内存碎片较低的激进模式下分配出去的大页,造成的内存膨胀并没有被回收回来。通过以下一个简单的Redis key-value store测试可以证明这个问题:
在一个内存为48G的系统上使用Redis做下述测试:
insert key-value 内存数据条目,使进程的内存占用(RSS)达到45G
delete 80%的数据条目
等待一段时间后,再次insert数据,使内存占用再次达到45G
测试结果如下:

如图所示,当执行P2阶段删除操作后,进程RSS迅速降低到约11GB左右,这个时候khugepaged内核线程会将很多空闲页面合并为大页,当在P3阶段进行分配时,RSS达到32G之前Ingens与linux一样都在尽可能的分配新的大页给应用程序,随后Ingens进入保守状态避免内存进一步膨胀,但最终Ingens与linux都触发了系统的oom异常,此时检查有效的数据条目可以发现,linux产生了28G的内存膨胀(只有20G的有效数据),而Ingens产生了20G的内存膨胀(有28G的有效数据),可以发现虽然Ingens试图减少内存膨胀,但是在前期造成>的内存浪费并不能回收。
如果将Ingens完全配置成保守模式,可以解决内存膨胀的问题,但是这种模式在低内存压力下性能损耗比较严重,一个理想的策略应该如图中的HawkEye所示,在低压力下尽可能的满足应用程序的高性能,而在内存压力过大时又能够从内存膨胀中有效的恢复回来。
缺页时延和缺页次数
操作系统在把页面分配给应用程序时,通常要将页面内容清零(部分场景除外),页面清零操作的耗时在缺页异常中占的比重非常大,特别是在使用大页时。测试发现清零一个4k页占整个缺页异常时长的25%,但是清零一个2M页需要占整个缺页异常时长的97%!过高的缺页时延会导致用户可感知的延迟,从而对交互式应用带来极为糟糕的体验。
Ingens为了解决这个问题,在缺页异常时只给应用分配4k小页,而将合并大页的操作全部交给后台线程khugepaged异步完成,但是这样做会失去使用大页的一个重要优点,即可以减少缺页次数。
通过一个小的benchmark测试,申请100G内存并且在每个4k页上写一个字节,然后把内存释放掉,下表显示了各种大页方案下的数据对比:
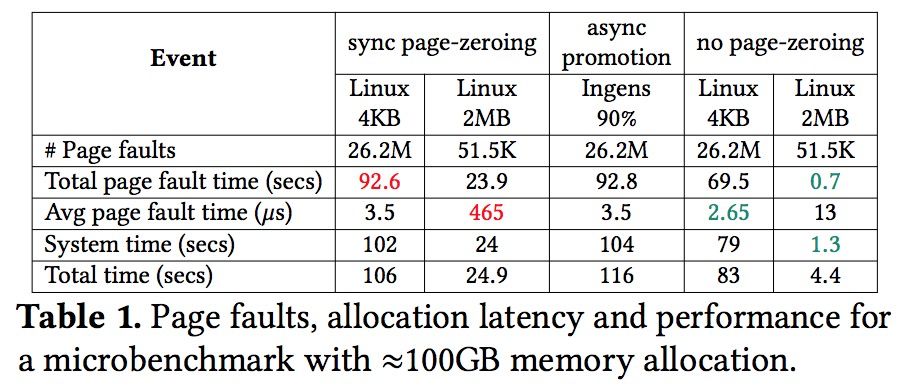
如上表所示,支持透明大页的linux系统(linux 2MB)相比只使用4k页的linux系统,缺页次数减少了大约500倍,最终在这个测试上带来了约4倍的性能提升,但是单次缺页异常的平均时延也上升了约133倍(465µs vs. 3.5µs),而Ingens在该场景下与linux 4k>表现基本一致。
可以猜想,如果在大页缺页时不需要进行页面清零,那么就可以让缺页异常的时延变短且缺页次数变少,HawkEye通过实现一个异步页面归零线程达到了这个目的。
多进程间的大页分配
由于存在内存碎片化,操作系统需要能在多个进程间公平的分配大页。Ingens的作者把连续物理内存作为一种系统资源,把进程内部的大页合并比例作为公平性指标,来评估并保证各个进程的公平性。Ingens的公平性策略有一个比较大的缺陷是如果两个进程P1和P2拥有相同比例的大页百分比,但P1进程的TLB压力远高于P2(比如P1的访问分散在多个4k小页中,但p2的访问集中在一个或某几个4k小页),此时P1更需要进行大页合并,但Ingens会平等对待这两个进程。
HawkEye提出的方案认为通过MMU开销来考量整个系统的压力更为有效,因此它认为公平算法应该尝试去平衡各个进程的MMU开销,让各进程的MMU开销保持相当。比如进程P1和P2的MMU开销分别为30%和10%,这时应该将更多的大页分配给P1,将其MMU开销降低到10%为止>,这样的策略能够让整个系统达到最优的性能。
最后,在单个进程内部,linux和Ingens目前都是采用从虚拟地址的低地址往高地址顺序扫描进行大页合并,这种方式对于热点在高地址区间的应用并不公平,由于通常应用的热点都分布在不同的vma区间内,因此当前的做法在实践上很容易出现不平等的现象。
如何测量地址转换的开销
目前估算地址转换开销的常用方法是通过WSS(workingset size):WSS更大的任务通常被认为拥有更高的MMU及性能开销,但是测试发现实际应用并不都是这样,如下图所示
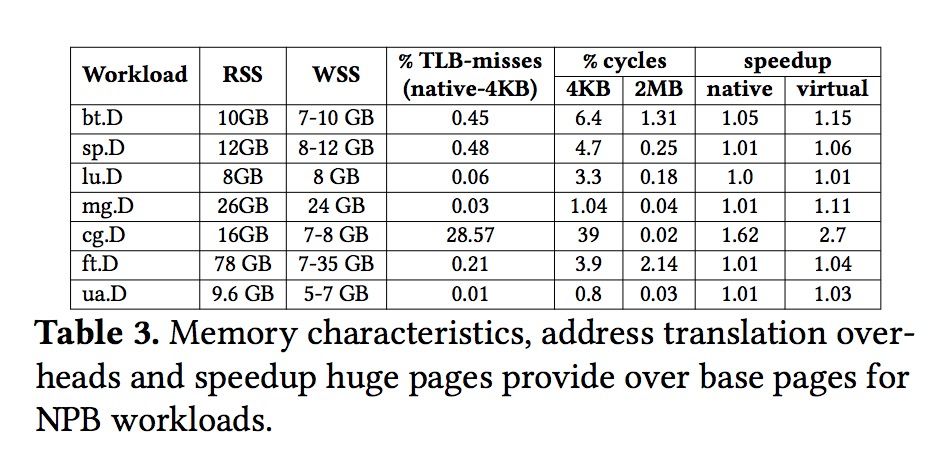
拥有高WSS的任务(如mg.D)比低WSS任务(如cg.D)的MMU开销小得多,这跟进程的内存访问模型有较大的关系。
我们并不清楚操作系统是如何测量MMU开销的,这依赖于应用程序与底层硬件的复杂关互关系,不过根据上述实验,我们知道这种开销可能与进程占用的内存大小并不直接成比例,因此在有条件的情况下,直接使用硬件性能计数器来统计TLB的开销更为有效,HawkEye>提出了如下算法来计算MMU overhead:

但由于部分情况下无法使用上述的性能计数器(比如在虚拟化场景,大部分hypervisor并没有虚拟TLB相关的硬件计数器),为了应对这种状况,HawkEye提出了两种算法:
基于硬件性能计数器来测量MMU开销的HawkEye-PMU算法,以及基于内存访问模型来估算MMU开销的HawkEye-G算法
设计与实现
上图显示了HawkEye的主要设计思路,HawkEye的整体解决方案基于四个关键因素:
(1)使用异步页面预清零方案来解决大页缺页时的时延过高问题
(2)识别并删除已分配大页中未使用的重复小页来解决内存膨胀问题
(3)基于对大页区域细粒度的访问跟踪,来选择更优的内存范围进行大页合并,跟踪的指标包括新近度、频率和访问覆盖范围(即在大页内访问过多少小页)
(4)基于对MMU开销来平衡进程间的公平性
异步页面预清零
异步页面预清零是一种较为常见的机制,通常是通过创建一个cpu使用受限的后台线程来实现,这种方式早在2000年左右就被提出来了,但是linux的开发人员认为这种方案并不能带来性能提升,主要基于以下两个理由:
异步预清零会对cache造成很大的污染,特别是容易造成多次cache misses,因为它在两个进程空间对连续的大片内存进行两次远距离的访问,第一次是后台线程中的预清零,然后是在应用程序中的实际访问,这种额外的cache miss会导致系统整体性能的下降。但是现在大部分硬件已支持non-temporal指令,预清零通过non-temporal方式进行写入,可以跳过cache直接 写到内存中,可以解决cache污染的问题
没有实际的经验或数据表明预清零可以带来明显的性能收益。但是如表1中的测试数据表明,尽管预清零对于4k页的收益不够明显,但是对于大页而言,清零的耗时占了缺页异常97%的时长,而目前大页已经在各种操作系统中都被广泛应用,预清零的收益会得到显>著的提升
为了实现异步预清零,HawkEye通过两个链表来管理伙伴系统中的空闲页面:zero and no-zero , 优先从zero链表分配大页,后台线程会周期性的将no-zero链表中的页面清零,清零时采用 non-temporal 方式写入,以避免对cache造成污染;而对于page cache和写时拷贝的页面,不需要进行预先清零,这类内存申请可以优先从no-zero链表中分配。
总之, HawkEye认为在新型硬件和当前工作负载的要求下,页面预清零是一个值得关注的话题,他们的测试数据证实了该方案的有效性。
内存膨胀
一般应用的内存主要来自以传统方法(如malloc)申请的全零页,剩下的就是文件缓存或写时拷贝申请的页面,而透明大页通常也只用于匿名页中。HawkEye在第一次缺页异常时优先给进程分配大页,但当系统内存压力过大时,会扫描每个大页中的全零小页,如果全>零小页超过一定的比例,就将该大页拆分成为小页,并且利用写时拷贝技术将所有的全零页面合并为一个。部分场景下这的确会导致缺页异常次数变多,但这种做法对减轻内存膨胀的收益更为明显。
为了从内存膨胀中恢复,HawkEye使用了两个内存分配水线,当系统内存申请量超过某个阈值(比如85%)时,会激活后台恢复线程,周期性的执行直到系统内存使用量降低到70%以下。每次执行时,恢复线程优先选择MMU开销最小的线程进行扫描,这个策略保证了最不需要大页的进程优先被处理,与HawkEye的大页分配策略(MMU开销最大的进程优先分配大页)保持一致。对于每一个小页来说,每次扫描到非0字节即可跳过,对于全零页需要扫描4096字节,这样扫描线程的开销就与整个系统的总内存无关,只与可回收的内存相关,>对于超大内存的系统也可适用。
全零小页合并的机制与linux内核当前的ksm机制比较类似,但是linux内核中的ksm与大页管理目前属于两个独立的系统,HawkEye借鉴了ksm中的部分技术来快速的找到全零页面并进行高效的合并。
精细化大页合并
当前系统的大页合并机制都是从进程的低地址空间扫描到高地址空间,这种方式效率很低,因为进程的热点内存区域不会都在低地址范围内。
HawkEye 定义一个叫access-coverage的指标,通过定期对大页中各小页的页表访问位进行扫描统计,可以判断在一定时间范围内其中有多少个小页被访问过,从而选择出hot regison进行合并,这样可以显著提高合并后带来的TLB收益。
HawkEye 通过一个per进程的数据结构access_map来管理 access-coverage,access_map是一个数组,每个数组成员称之为一个桶(每个桶内实际是一个链表)。拿x86的2M大页举例,每个大页由512个小页组成,根据大页中每个小页页表上面的访问次数总和 0-512,>将该大页放入对应的桶中中,访问次数为0-49的放在桶0,50-99的放在桶1,以此类推,下图显示了三个进程A、B、C的access_map状况:
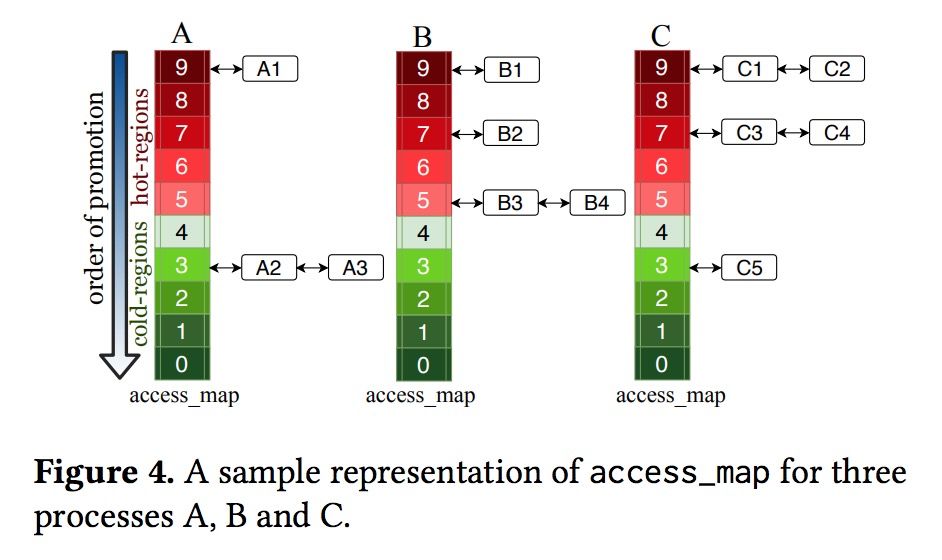
当某一次扫描时,某个大页的访问范围增加,比如从30个小页被访问增加到55个小页被访问,则需要将其从桶0移动到桶1(升级),此次会把它移到对应桶的链表头部,反之从桶1移到到桶0(降级)时会移到桶的链表尾部>,而大页合并是从链表头部遍历到尾部,这样可以确保每次合并时优先合并最近访问过的区域。可以注意到HawkEye 的方案兼顾了访问频率和新近度,最近未访问或访问范围较低的大页会被移到更低级的桶中或是当前桶的链表尾部。
多进程间的大页分配
在 access-coverage 策略里面,具有最高MMU压力的页面会优先被合并为大页,这与之前讨论的公平性一致,即优先合并TLB压力最大的进程;access-coverage总是挑选所有进程中访问范围最广的那一个桶(如上图桶9)来优先回收,如果多个进程含有相同最高等级>,则采用循环的方式保证公平,如上图,在进程A、B、C中的合并顺序为 A1,B1,C1,C2,B2,C3,C4,B3,B4,A2,C5,A3。
但是,MMU开销可能并不一定与上述基于访问的覆盖范围完全一致,因此在HawkEye-PMU算法中,会优先选择硬件计数器测量出的具有最高MMU开销的进程,然后再按照上述各桶的顺序进行大页合并。如果有多个进程的MMU开销相近,则采用循环的方式逐个处理。
限制与讨论
HawkEye算法当前存在以下几个没有解决的问题:
(1)内存压力的阈值如何选定,当前都是采用静态的固定阈值,如系统内存的85%和70%,如果内存压力一直波动,那么静态的阈值可能会偏保守或是激进,理想的状态是能够根据系统状态,动态的调整这些阈值
(2)第二个问题是大页饿死,虽然HawkEye算法基于mmu开销,但确实有可能造成部分进程没办法使用大页(因为MMU压力不够),这个问题可以通过linux的cgroup等机制限制进程的大页使用数来解决
(3)其它算法,部分没有讨论过的管理算法,像khugepaged的合并/拆分机制本身的开销,能够将页表项跟踪开销最小化的合并算法等,HawkEye在这些领域暂时没有太深入的研究
测试数据对比
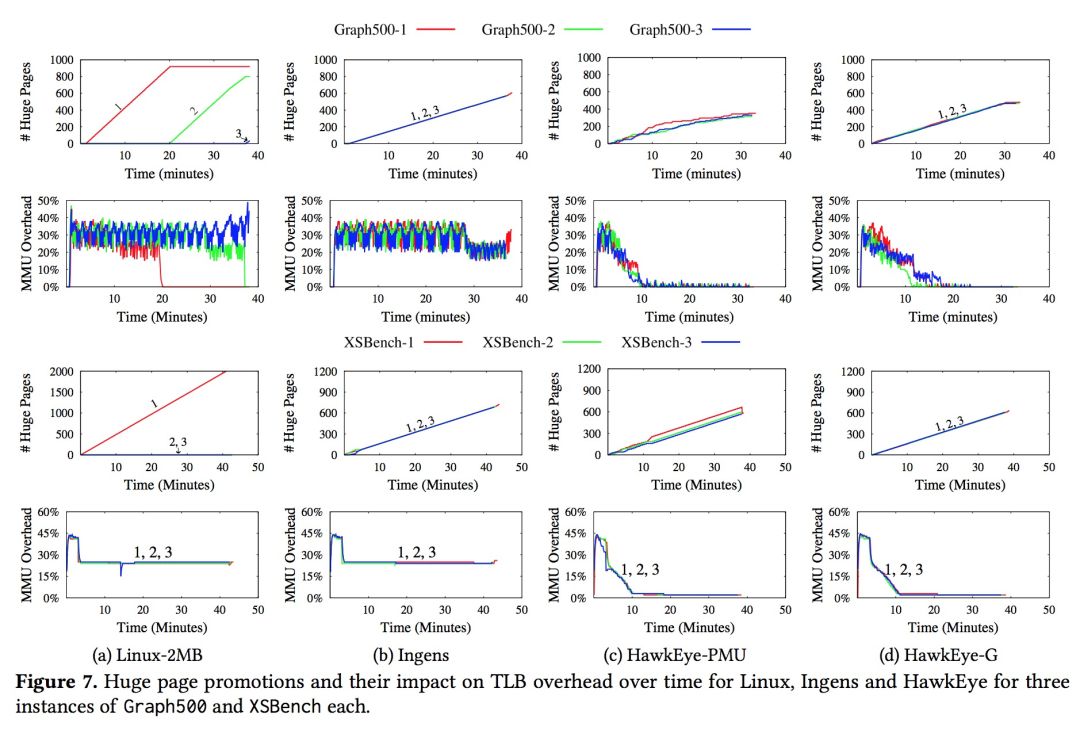
精细化大页合并效果
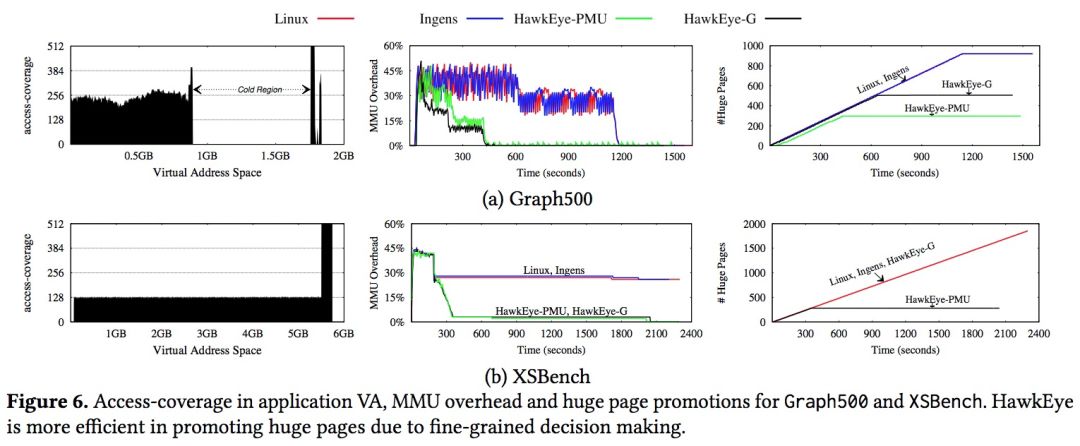
上图显示了单个Graph500 和 XSBench应用在不同算法下的执行效果,从第一列可以看到,应用的热点内存区域不是总在低地址空间,第二列和第三列显示了大页合并的效果,Linux和Ingens都花了接近1000s才将mmu overhead降下来,而HawkEye只使用了约300s就有了显著的效果。
多进程公平性效果
同时运行三个Graph500 和三个 XSBench应用,下表显示了整体的运行时长,在HawkEye算法下的运行时长比linux及Ingens更短,性能更高
下图则展示了上述测试运行过程中,每个进程的大页占用数及mmu开销,从图中可以明显看出,linux的大页占用数对各个进程很不公平,随机性较大,Ingens和HawkEye则对各个进程更为公平,而在MMU开销上的表现HawkEye占据绝对优势
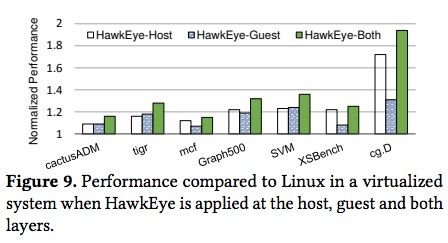
虚拟化场景效果
下图显示了在虚拟化场景下,HawkEye比Linux提升了约18–90% 的性能,可以看到在部分应用(如cg.D)下,HawkEye在虚拟化场景的性能提升比祼机更明显,原因是在处理guest TLB miss时,涉及到多层MMU开销,这给了HawkEye的算法更多的发挥空间
测试配置

测试效果
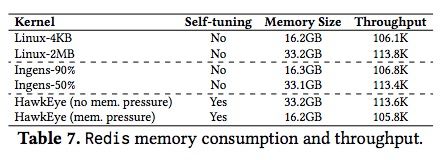
内存膨胀恢复效果
下表显示了Redis场景下的内存膨胀与性能之间的平衡效果,在内存压力较小的时候下,HawkEye占用较大的内存(与linux-2M相当)以带来更高的性能,而当内存压力变大时,HawkEye能消除Redis的内存膨胀,降低到linux仅使用4k小页(无内存膨胀)时的水平
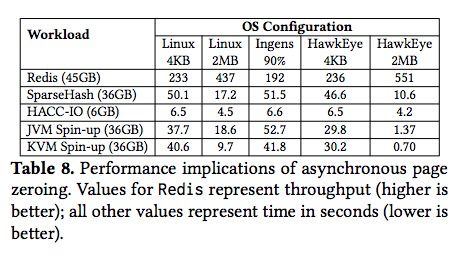
缺页异常加速效果
HawkEye在4k场景下对缺页异常的加速效果并不明显,这是因为页清零占据缺页的比例太小。
下表第一行显示的是Redis的吞吐量,可以看到HawkEye在2M大页场景下比linux-2M提升了约1.26倍。
其它行显示的数据是执行时间,HawkEye-2M比linux-2M在SparseHash测试上提升了约1.62倍。
而虚拟化场景下spin-up运行时长与缺页异常强相关,可以看到大页场景下HawkEye可以比linux提升约13倍,但在4k页场景下提升只有1.2倍左右
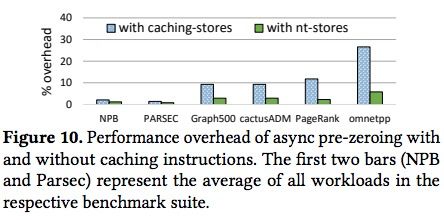
异步预清零线程开销
下表显示了在多个测试套下异步预清零线程带来的性能开销,可以看到使用non-temporal指令(无cache)可以明显的降低该开销,在omnetpp测试下,使用nt-stores可以将overhead从27%降低到6%,而普通场景下的平均开销都在5%以下
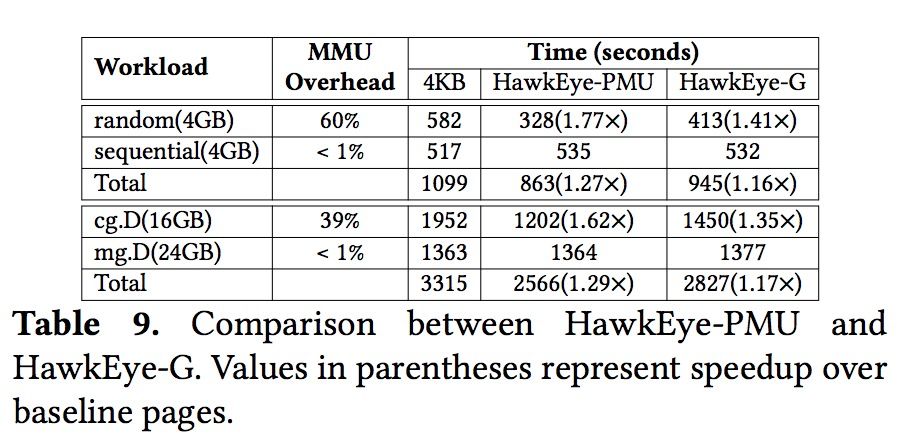
HawkEye-PMU与HawkEye-G对比
HawkEye-PMU基于硬件性能计数器计算MMU开销,相比HawkEye-G的软件估算会更精确,HawkEye-G的估算是基于页面的访问覆盖率,但相同覆盖率的应用也会存在TLB敏感与不敏感之分,如下在一个系统中同时运行两个任务:TLB敏感任务(如cg.D)与TLB不敏感任务(>如mg.D),可以看到HawkEye-PMU可以精确识别出MMU开销更高的任务,而HawkEye-G基于页面访问的估算可能会出现偏差,最坏情况下HawkEye-PMU会比HawkEye-G好36%,如何通过软件的方式消除这两种算法的差异需要留给未来的工作
更多精彩

2019阿里云618大促主会场全攻略


对话阿里云智能数据库事业部总负责人李飞飞:云数据库战争已经进入下半场

如果觉得本文还不错,点击在看一下!
点此进入阿里云618主会场撰写故事赢6.18万大奖!




