文本数据增强:撬动深度少样本学习模型的性能

本人主要关注NLP与深度学习这个交叉领域,因此本文从NLP领域涉及的目标场景出发,介绍文本数据增强的概念、相关技术手段以及展望。
本文目录:
1.文本数据增强理论介绍
1.1数据增强是什么
1.2 数据增强的应用场景
2.典型技术方案
2.1 通用EDA
2.2 基于TF-IDF的非核心词替换
2.3 回译
2.4 上下文文本生成
3.总结与展望
1.文本数据增强理论介绍
1.1 数据增强是什么
数据增强,是指对(有限)训练数据通过某种变换操作,从而生成新数据的过程。而文本数据增强则是针对文本数据进行操作。简而言之,就是利用数据增强这种手段扩大数据规模。
数据增强技术大体可分为以下两类:
• 句子层面增强:即在保持语义不变的情况下,变换文本的表达形式,例如回译、文本复述等手段;
• 词层面增强:即按照某种策略对文本局部进行调整,例如同义词替换、随机删除等。
1.2 数据增强的应用场景
(1)少样本学习场景
利用深度学习训练模型有时会遇到训练样本的数据量不能满足模型训练需求的情形,这就是少样本学习场景,这种场景较大概率会导致模型欠拟合。针对这种场景问题,研究学者和工程师自然而然想到了利用数据增强技术生成新样本进而扩充训练集,在有效降低人工成本的基础上促进模型性能的提升。近几年来也有许多研究验证了这种方法的有效性。
(2)半监督学习场景
从上一篇‘解决少样本学习的半监督学习方案’一文已经提过UDA技术,从这个技术可以看出:文本数据增强技术可以基于无标签样本来构建出新的样本,进而生成半监督训练所需要的数据,通过这种方式让模型在训练过程中从无标签数据中获取到优化所需的梯度知识。
(3)分类任务中各类别样本分布不均衡场景
在处理文本分类任务时,大家都会接触到各类别样本数据不均衡的场景,甚至有些类别的样本数目是别的类别样本数目的2-3倍。面对这种场景,如果直接将数据用于训练模型的话,很大的概率会导致训练好的模型对于样本数目少的类别处于欠拟合状态,实际预测时,预测类别往往会偏向于样本数目较多的类别标签。
(4)鲁棒性场景
利用文本数据增强技术可以让训练好的模型更加关注文本全局所表达的语义信息,对于其局部的噪声不再敏感。例如句子A“自然语言处理是人工智能的掌上明珠”,经过数据增强后变成句子B“自然处理语言是人工智能的明珠掌上”,将句子A和B输入到模型后得到的预测标签如果一致,则说明模型对于文本局部的噪声是不敏感的,这样的模型就是鲁棒性好的。事实上,文本数据增强技术对于少样本场景和多语料场景的模型鲁棒性都有进一步的促进作用,可以提高模型的泛化能力。
2.典型技术方案
2.1 通用EDA
这一个方法其实是来源19年一个研究团队提出的Easy Data Augmentation文本增强方法,具体可见这篇论文EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks。
EDA主要包含四种操作:
• 同义词替换(SR, Synonym Replace):从句子中随机选择非停用词,然后用这些选中词对应的同义词来替换它们;
• 随机插入(RI, Random Insert):随机的找出句中某个非停用词,随后使用其同义词插入句中的一个随机位置。这个操作可以重复n次;
• 随机交换(RS, Random Swap):随机的选择句子中的两个词语,然后交换这两个词语的位置。这个操作可以重复n次;
• 随机删除(RD, Random Delete):以固定概率随机删除句子中的词语。
除此之外,还有一种操作也可归为EDA的范畴,即:
句子位置随机替换:通过逗号、分号等分隔符切分句子,随后交换句子组合的顺序后重新组合成新句。
其中针对句子位置随机替换,本质上是在表达这样一种先验信念,即对于所处理的文本,其句子出现的先后顺序并不影响其全局语义的表达。
下面给出这五种操作的具体示例:
示例文本:想咨询下,我老公婚前买了一个房子并且在结婚前把房子登记在了他的名下,离婚的话这个房子要怎么分
同义词替换/SR:想咨询下,我老公婚前买了一个房子并且在结婚前把房子注册在了他的名下,离婚的话这个房子要怎么分 【‘登记’->‘注册’】
随机插入/RI:想咨询下,请教我老公婚前买了一个房子并且在结婚前把房子登记在了他的名下,离婚的话这个分割房子要怎么分 【操作2次,插入了‘请教’和‘分割’】
随机交换/RS:想咨询下,我老公买了一个房子婚前并且在结婚前把房子登记在了他的名下,离婚的话房子这个要怎么分【操作了两次,‘婚前’和‘买了’交换位置,‘这个’和‘房子’交换位置】
随机删除/RD:想咨询下,我老公婚前买了一个房子并且在结婚前把房子登记在了他的名下,离婚的话这个房子要怎么分【删除‘房子’】
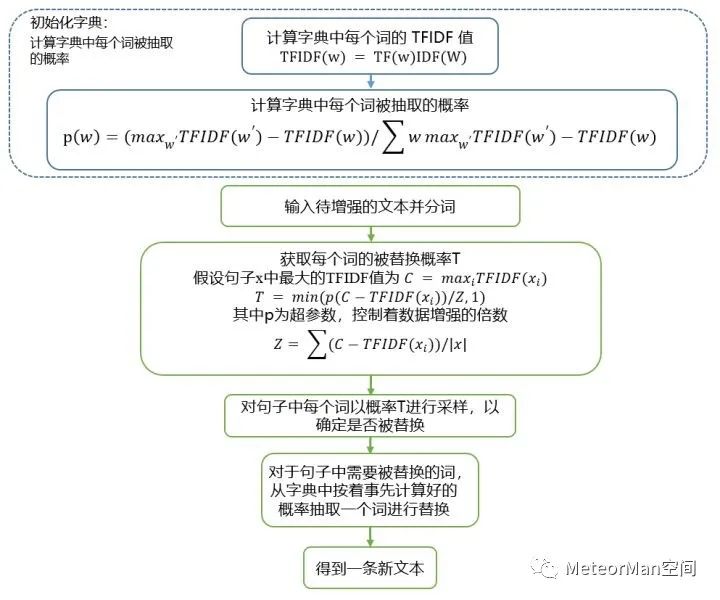
2.2 基于TF-IDF的非核心词替换
在通用EDA中要替换的词是随机选择的,但是如果一些重要词被随机替换掉的话,那么增强后文本的质量会降低,为了避免这个问题,引入了一种“基于非核心词替换的文本数据增强技术”。
而基于TF-IDF的非核心词替换方法同样来自于Google的UDA技术。首先计算出来每个词对应的TF-IDF,知道这个词对于一个文本的重要性,随后采用与TF-IDF负相关的概率去选取文中其他词,用来决定是否要替换,这样可以有效避免将文本中的一些关键词进行错误替换或删除。
下面列出UDA论文所提出的具体实现方式,如下图所示:
 2.3 回译
在文本数据增强领域基于回译(
back translation)的方法是一种质量高且无技术门槛的一种方法。
这种方法流程很简单,即:
假定文本A的语种为中文,若要对A进行回译增强,直接利用翻译模型将A的中文语种文本先翻译为语种1的表达,再基于语种1的表达
翻译
为语种2的表达,最后针对语种2的表达翻译回文本A的中文语种表达,最后得到的中文语种表达文本就是回译增强后的文本。
2.3 回译
在文本数据增强领域基于回译(
back translation)的方法是一种质量高且无技术门槛的一种方法。
这种方法流程很简单,即:
假定文本A的语种为中文,若要对A进行回译增强,直接利用翻译模型将A的中文语种文本先翻译为语种1的表达,再基于语种1的表达
翻译
为语种2的表达,最后针对语种2的表达翻译回文本A的中文语种表达,最后得到的中文语种表达文本就是回译增强后的文本。
当然,目前工业界大多都是调用谷歌翻译或者百度翻译的api接口来搭建回译组件,甚至有下游任务语料积累的同学也针对性的构建出一个机器翻译模型,进而生成回译组件。
2.4 上下文文本生成
基于上下文信息的文本数据增强主要是利用一个训练好的语言模型(LM),对于需要增强的原始文本,随机去掉文中的一个词或字(这取决于语言模型支持字还是词)。接下来,将文本的剩余部分输入语言模型,选择语言模型所预测的 top k 个词去替换原文中被去掉的词,以形成 k 条新的文本。在这里,可以将BERT的MLM机制很好的融合进去。
另一个方法就是利用语言生成模型进行文本增强。比较典型的技术是IBM研究团队提出的基于GPT架构的LAMBDA(language-model-based data augmentation)技术。
LAMBADA首先在大量文本上进行了预训练,使模型能够捕获语言的结构,从而能产生连贯的句子。然后在不同任务的少量数据集上对模型进行微调,并使用微调后的模型生成新的句子。最后在相同的小型数据集上训练分类器,并进行过滤,保证现有的小型数据集和新生成数据集有相近的分布。
3.总结与展望
本文针对文本数据增强进行了理论介绍,并列出了如今学术界和工业界的典型技术方案。文中提到的技术手段都可以独立运用,也可以结合实际业务联合运用。此外,文本数据增强技术之所以有效,主要是在于:
• 正则化方法使得模型能够在假设空间中有效的收敛,实现较好的泛化误差;
• 较好的引入了迁移学习的知识,提高了整体数据的信息容量,进而更好地指导当前模型的学习。
针对未来的技术探索,可以结合图像风格迁移研发出应用在NLP领域的语言风格迁移算法,进而促进文本数据增强技术的发展。

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



