深度 | 结合Logistic回归构建最大熵马尔科夫模型
选自davidsbatista
作者:David S. Batista
机器之心编译
参与:乾树、刘晓坤
这是应用于 NLP 的连续监督学习系列博文的第二篇。它可以看作是上一篇文章的续作(参见:深度 | 从朴素贝叶斯到维特比算法:详解隐马尔科夫模型),在上一篇博客中,作者试着解释了隐马尔科夫模型(HMM)和朴素贝叶斯(Naive Bayes)之间的关系。在这篇博客中,作者将尝试解释如何构建一个基于 Logistic 回归分类器的序列分类器,即,使用一种有区别性的方法。
判定模型 vs 生成模型
上一篇博文中,我讨论了朴素贝叶斯模型,以及它与隐马尔可夫模型之间的联系。它们都属于生成模型,但本文要讲的 Logistic 回归模型是一个判定模型,全文以讨论这种差异开始。
通常,机器学习分类器通过从所有可能的 y_i 中选择有最大的 P(y | x) 的那个,来决定将哪个输出标签 y 分配给输入 x。
朴素贝叶斯分类器通过应用贝叶斯定理间接估计 p(y | x),然后计算类的条件分布/概率 P(x | y) 和先验概率 P(y)。
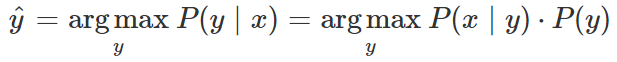
这种间接性使得朴素贝叶斯成为一种生成模型,一种通过训练从类 y 生成数据 x 的模型。p(x | y) 的意义是给定一个类 y,然后预测对应的输入 x 中包含哪些特征。相比之下,判定模型通过直接判定类别 y 的不同可能值来计算 p(y | x),而不是计算概率。Logistic 回归分类器正是这种分类器。
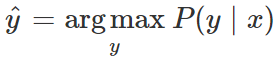
Logistic 回归
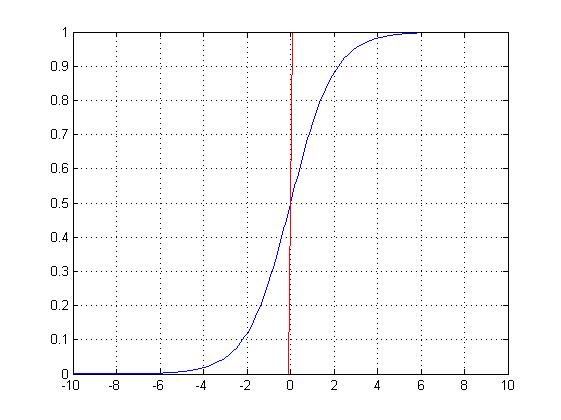
Logistic 回归是用于分类的一种监督学习算法,它的本质是线性回归。
当用于解决 NLP 任务时,它通过从输入文本中提取特征并线性组合它们来估计 p(y | x),即,将每个特征乘以一个权重,然后将它们相加,然后将指数函数应用于该线性组合:
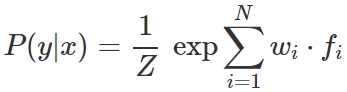
其中 f_i 是一个特征,w_i 是与该特征相关的权重。对于权重和特征点积进行的 exp(即,指数函数)确保所有值都是正值,并且需要除以分母 Z 以得到(所有概率值的总和为 1)有效概率。
提取到的是二值特征,即只取值 0 和 1,通常称为指标函数。其中每一个特征都是通过输入 x 和类 y 的函数来计算的。每个指标函数表示为 f_i(y , x),对于类 y 的特征 i,给定观测值 x:
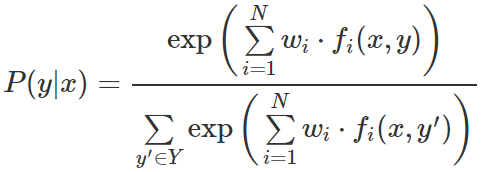
训练
我们想通过训练 logistic 回归来获得每一个特征的理想权重(使训练样本和属于的类拟合得最好的权重)。
Logistic 回归用条件极大似然估计进行训练。这意味着我们将选择参数 w,使对给定输入值 x 在训练数据中 y 标签的概率最大化:
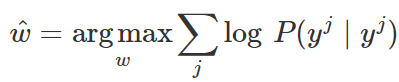
需要最大化的目标函数是:
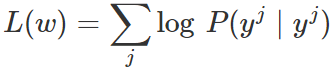
通过用前面展示的扩展形式替换,并应用对数除法规则,得到以下形式:
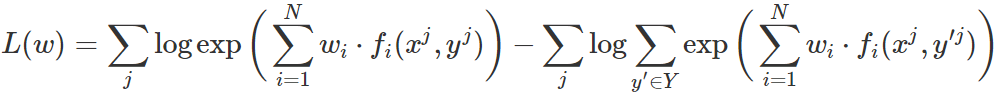
通常可以运用随机梯度下降法、L-BFGS 或共轭梯度法来求此函数的最大值,即找到最优权重。
分类
在分类任务中,logistic 回归通过计算给定观察的属于每个可能类别的概率,然后选择产生最大概率的类别。
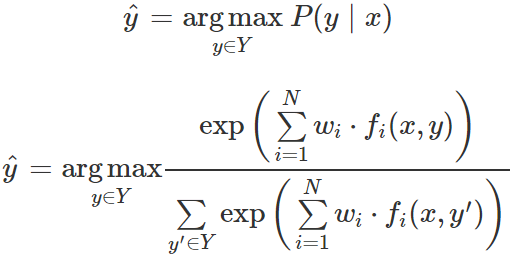
最大熵马尔可夫模型
最大熵马尔可夫模型(Maximum Entropy Markov Model,MEMM)的思想是利用 HMM 框架预测给定输入序列的序列标签,同时结合多项 Logistic 回归(又名最大熵,其给出了可以从输入序列中提取特征的类型和数量上的自由度)。
HMM 基于两种概率:
P(tag | tag) 状态转换,从一个状态到另一个状态的概率。
P(word | tag) 输出概率,从一个状态输出一个字的概率。
在现实问题中,我们要预测一个给定词/输入的标签/状态。但是,由于贝叶斯定理(即生成方法),在 HMM 中不可能进行编码,而模型估计的是产生某个确定单词的状态的概率。
MEMM 因包含丰富的输入特征而备受推崇:
除了传统的单词识别之外,还有描述输入的多种重叠特征的表示,例如大写字母、单词结尾、词类、格式、页面上的位置以及 WordNet 中的节点成员等。
也可以用一个判定方法来解决预测问题:
传统的方法通过设置 HMM 参数以最大化输入序列的概率; 然而,在大多数文本应用中,其任务是根据输入序列来预测状态序列。换句话说,传统方法不恰当地使用生成联合模型来解决给定输入的条件问题。
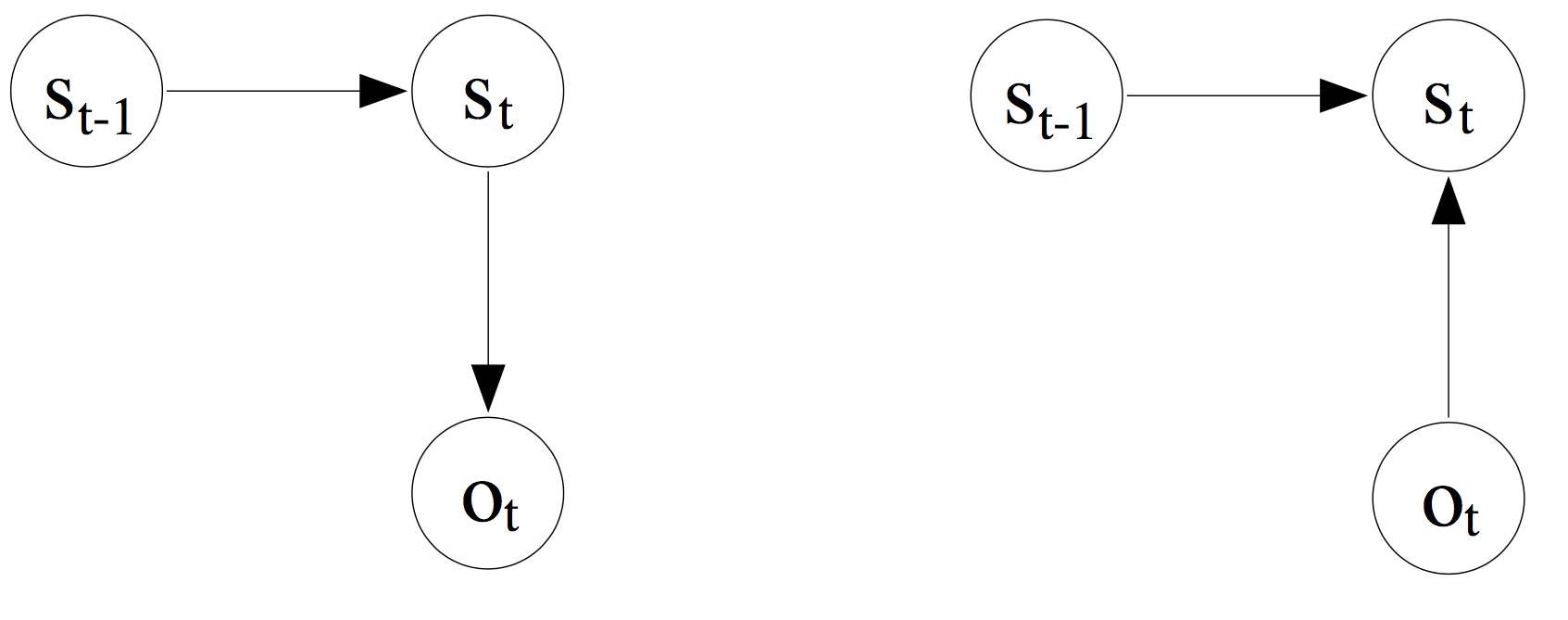
(左)传统 HMM 的依赖关系图。(右)最大熵马尔可夫模型的依赖关系图(选自 A. McCallum et al. 2000)。
在最大熵马尔可夫模型中,转换函数和输入函数(即上一篇博客的 HMM 矩阵 A 和 B)被单个函数代替:
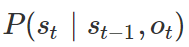
给定前一个状态 s_t-1 和当前的输入值 o_t,得到当前状态的概率 s_t。下图展示了计算状态/标签/标记转换的不同之处。
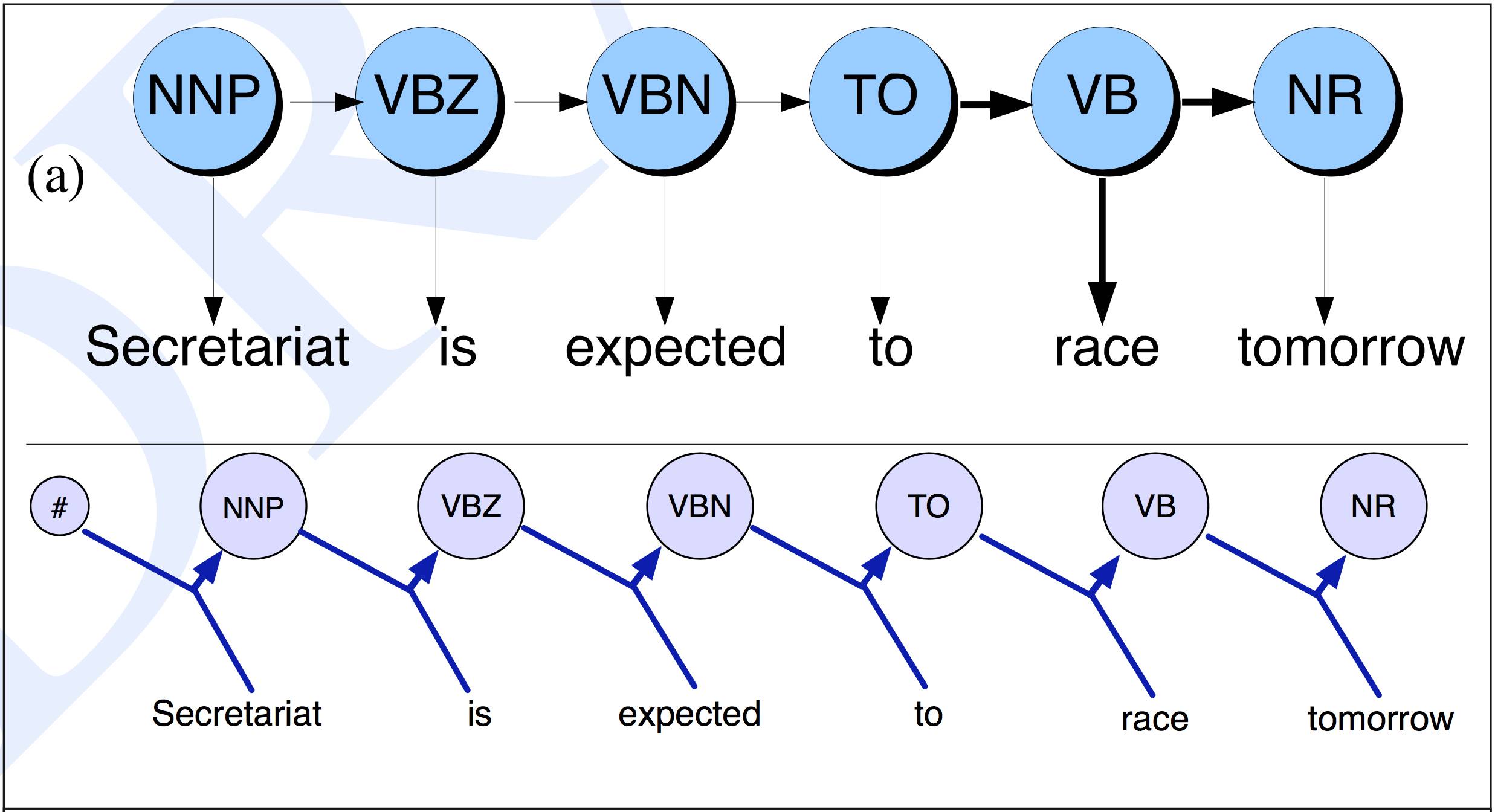
HMM 和 MEMM 之间状态转换估计的对比。(选自「Speech and Language Processing」,Daniel Jurafsky & James H. Martin)
与当前输入仅依赖于当前状态的 HMM 相比,MEMM 中的当前输入也可以取决于之前的状态。HMM 模型对于每个转换和输入都有确定的概率估计,而 MEMM 给出每个隐藏状态的一个概率估计,这是给定前一个标记和输入值情况下的下一个标记的概率。
在 MEMM 而不是转换和观测矩阵中,只有一个转换概率矩阵。该矩阵将训练数据中先前状态 S_t-1 和当前输入 O_t 对的所有组合封装到当前状态 S_t。
令 N 为独特状态的个数,M 为独特单词的个数,矩阵的形状为:(N⋅M)⋅N
特征函数
MEMM 可以对输入值的任何有用特征进行条件化。在 HMM 中这是不可能的,因为 HMM 是基于概率的,因此需要计算每个输入特征的概率。使用状态-输入转换函数,而不是像 HMM 那样的独立的转换和输入函数,使我们能够对输入的多个非独立特征进行建模。
这是通过多项 logistic 回归来实现的,给定先前标记(即,s'),输入词(即,o)和任意其它特征(即,fi(x,y’))来估计每个局部标记的概率:
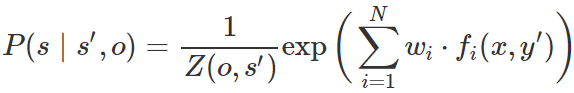
其中 w_i 是与每个特征 f_i(x,y) 相关联的需要学习的权重,Z 是使矩阵在每行上总和为 1 的归一化因子。
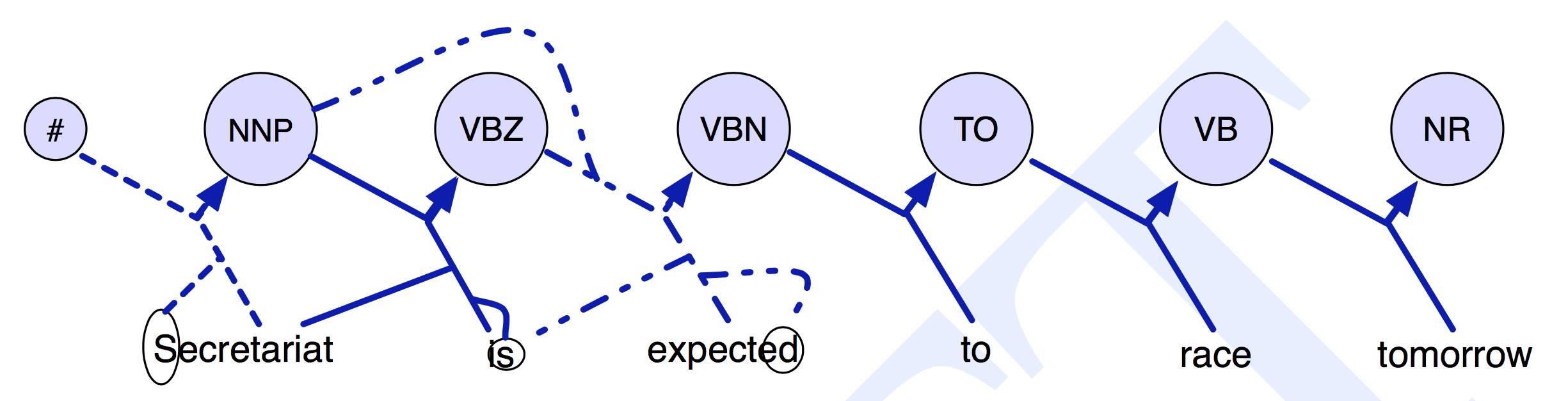
考虑整个观测序列的特征函数。(选自「Speech and Language Processing」,Daniel Jurafsky & James H. Martin)
训练与解码
最初发表于 2000 年的 MEMM 论文使用广义迭代缩放(GIS)算法来拟合多项 logistic 回归,即根据训练数据找到完美的权重。该算法在很大程度上被基于梯度的方法(如 L-BFGS)所超越。
使用与 HMM 中相同的 Viterbi 算法进行解码,尽管不是那么适合估计状态转换的新方法。
MEMM 的重要结论
相对于 HMM 的主要优势是使用特征向量,使得转换概率对输入序列中的任何词都敏感。
每个(状态,单词)对都有一个指数模型来计算下一个状态的条件概率。
指数模型允许 MEMM 支持整个观测序列与前一状态(而不是两个不同的概率分布)的长距离交互。
MEMM 还可以扩展为包含涉及额外过去状态(而不仅仅是前一个状态)的特征。
它也使用 Viterbi 算法(稍作改动)来执行解码。
它受到标签偏差问题的影响,我将在下一篇关于条件随机场的文章中详细介绍。
软件包
https://github.com/willxie/hmm-vs-memm:一个由 William Xie 负责的课程项目,在词性标注方面的任务上实现且比较了 HMM 与 MEMM。
https://github.com/yh1008/MEMM:由 Emily Hua 发布的名词短语拆分任务的实现。
https://github.com/recski/HunTag:由 GáborRecski 发布的序列句子标记的实现,并有详细文档。
参考文献
Chapter 7:「Logistic Regression」in Speech and Language Processing. Daniel Jurafsky & James H. Martin. Draft of August 7, 2017.(https://web.stanford.edu/~jurafsky/slp3/7.pdf)
Maximum Entropy Markov Models for Information Extraction and Segmentation(http://www.ai.mit.edu/courses/6.891-nlp/READINGS/maxent.pdf)
Chapter 6:「Hidden Markov and Maximum Entropy Models」in Speech and Language Processing. Daniel Jurafsky & James H. Martin. Draft of September 18, 2007(https://www.cs.jhu.edu/~jason/papers/jurafsky+martin.bookdraft07.ch6.pdf)
Hidden Markov Models vs. Maximum Entropy Markov Models for Part-of-speech tagging(https://github.com/willxie/hmm-vs-memm)

原文链接:http://www.davidsbatista.net/blog/2017/11/12/Maximum_Entropy_Markov_Model/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com