【论文导读】2022年论文导读第八期


论文导读
2022年论文导读第八期(总第四十八期)
目 录
|
1 |
Few-Shot Multi-Agent Perception |
|
2 |
Cross-modality Discrepant Interaction Network for RGB-D Salient Object Detection |
|
3 |
ABPNet: Adaptive Background Modeling for Generalized Few Shot Segmentation |
|
4 |
Occlusion-aware Bi-directional Guided Network for Light Field Salient Object Detection |
|
5 |
R-GAN: Exploring Human-like Way for Reasonable Text-to-Image Synthesis via Generative Adversarial Networks |
01
Few-Shot Multi-Agent Perception
作者:范晨悠1,胡君杰1,黄建伟2
单位:1深圳市人工智能与机器人研究院,2香港中文大学(深圳)
邮箱:
fanchenyou@gmail.com,
hujunjie@cuhk.edu.cn,
jianweihuang@cuhk.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475315
代码:
https://github.com/fanchenyou/fs-map-project
视频demo:
https://www.bilibili.com/video/BV1sF411Y72b/
研究背景
设想在未来的校园中,校园送餐车或者警务车执行点到点的个体服务任务,首先需要在人群中识别目标个体再进行路径规划。我们设计一种高效的空地协同模式:1)利用多个无人机进行人脸识别,获取校园内人群动态信息;2)自动驾驶送餐车或者警务车通过发送目标人脸到多个无人机数据进行匹配,再返回相似度,从而确定目标任务的地理位置再进行路径规划。
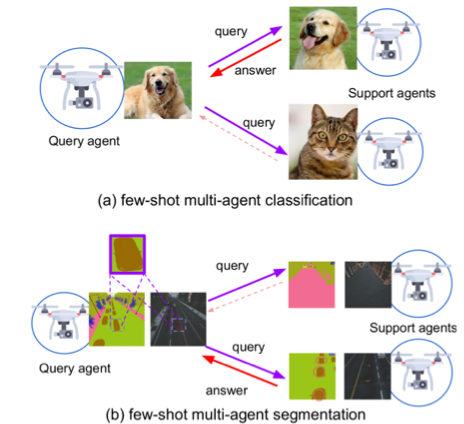
图1 多智能体协同感知示意图
我们研究这个过程中的多智能体协同感知过程。如上图所示,查询智能体(query agent,左)通过发送自己的少样本数据特征(如单张人脸图片)到多个支持智能体(support agent,右)。支持智能体自身可以不断更新自己的人脸数据库,通过不断地飞行持续感知地面情况,更新目标的坐标和外观特征。支持智能体接受查询智能体的查询,通过比对自身的数据,提供相似度计算结果并返回给查询智能体。查询智能体接收所有支持智能体的返回值进行排序和筛选,从而最终确定目标位置。
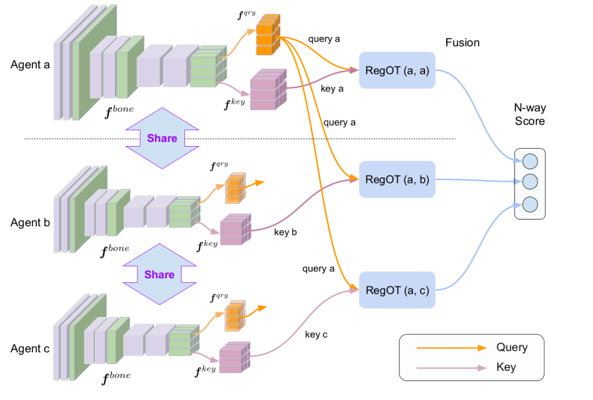
图2 分布式度量学习框架示意图
研究方法
通过上述多智能体感知的过程,我们需要解决如下两个难点。1)查询智能体如何提取感知数据的特征并发送给支持智能体;2)分布式支持智能体如何高效地计算查询-支持数据之间的相似度。
我们设计一种分布式特征提取与度量学习的架构,如图2所示。对于典型的感知数据,如图像、音频频谱,我们首先进行编码,即生成其深度特征。通过使用深度学习网络(如CNN),生成紧凑的查询数据的特征qu(用于发出广播查询), 以及在各个分布式智能体本地生成维度较大的支持数据特征kv,其维度大小可以根据任务精度进行选取,并且可以设置为非对称大小。我们通用余弦距离来计算查询特征与支持特征的相似度 :
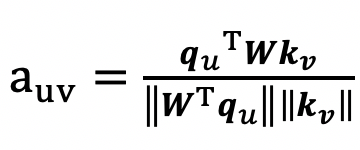
通过计算查询数据与所有分布式支持数据之间的相似度,得到最优匹配支持数据,从而赋予其相应的数据标签作为回答。
为了保证对图像数据的移动、视角和旋转等变换的鲁棒性,我们进一步将图像2D特征平面分成N-by-N个特征区域,利用最优传输(optimal transport) 优化目标得出查询-支持数据各个区域之间最佳匹配,通过加权平均匹配值获得查询-支持数据整体的最优匹配值,获得更加鲁棒的相似度度量。如上图所示,我们给出多项式时间的算法,结合深度学习网络进行训练。
研究结果
我们通过实验验证了所提方法,在图像分类、图像分割、人脸识别、音频频谱分析等人工智能目前的典型应用场景下,均大幅超越现有的方法。
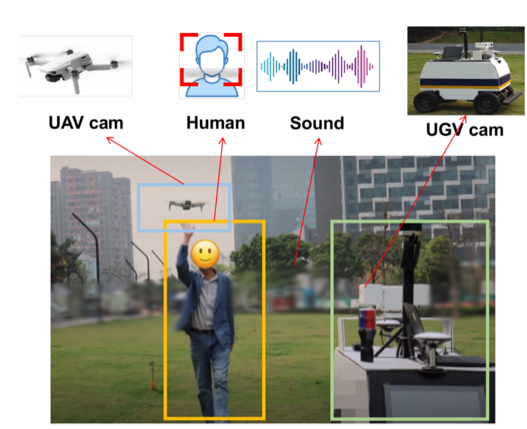
图3 多智能体视频、人脸图像、音频采集示意图。
在人脸识别方面,我们收集了“Celebrity of Airs”数据,验证了在小样本学习设定下(5-way 1-shot/5-shot)无人机和地面的人脸识别精度为 67%/70%,精度比原有方法[2,3]提高10-15%。在道路分割任务上,我们利用Airs-Sim无人机模拟数据,在道路的语义分割任务上进行验证, 在小样本学习设定下(3-way 1-shot/5-shot) 精度为72%/78%,比原有方法提高5%左右。同样的,在少样本图像分类和音频频谱风格分类任务上精度均有大幅度提高。
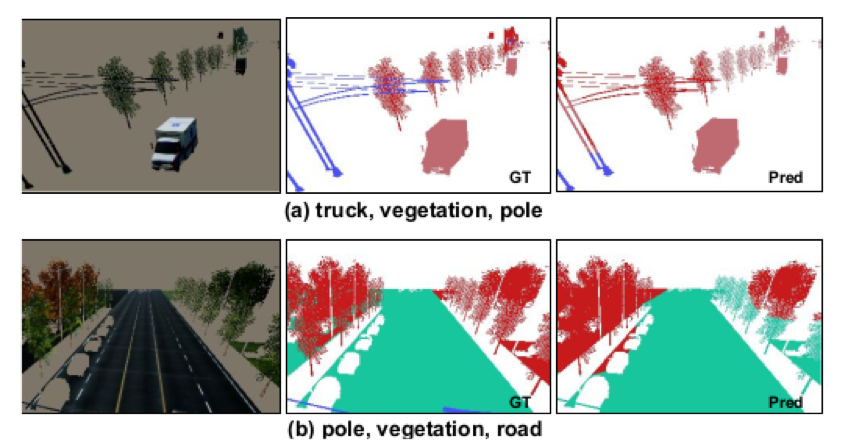
图4 Air-Sim 少样本道路分割结果
总结
我们提出了一种有效的分布式多智能体小样本感知的学习框架。该框架体现了多智能体数据收集的优势,即海量数据的协同收集;同时体现了多智能体协同感知的算力优势,即通过分布式执行的方式,实现数据处理的本地化;最后,体现了多智能体少样本学习的算法优势,即通过解耦分布式数据之间的关联,保证了分布式执行返回的结果为全局最优,而无需分布式节点之间的通信,节省了通信开销
参考文献
[1] Chenyou Fan, Junjie Hu, Jianwei Huang. "Few-Shot Multi-Agent Perception." 29th ACM International Conference on Multimedia 2021 (ACM MM'21)
[2] Abhishek Das, Théophile Gervet, Joshua Romoff, Dhruv Batra, Devi Parikh, Mike Rabbat, and Joelle Pineau. 2019. Tarmac: Targeted multi-agent communication.In ICML.
[3] Jake Snell, Kevin Swersky, and Richard Zemel. 2017. Prototypical networks for few-shot learning. In NIPS.

02
Cross-modality Discrepant Interaction Network for RGB-D Salient Object Detection
作者:Chen Zhang1, Runmin Cong*1, Qinwei Lin1, Lin Ma2, Feng Li1, Yao Zhao1, Sam Kwong3
单位:1北京交通大学信息科学研究所,2美团 ,3香港城市大学
邮箱:
chen.zhang@bjtu.edu.cn,
rmcong@bjtu.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475364
*通讯作者
深度图的普及和推广为显著目标检测带来了新的生机和活力,大量的RGB-D显著性目标检测算法被提出,主要集中在如何更好地融合RGB图像和深度图像的跨模态特征上。然而,对于跨模态特征的交互方式,现有方法要么不加区别地对待RGB和深度模态,要么只是习惯性地利用深度特征作为RGB分支的辅助信息。与之不同,本章节重新考虑了两种模态在跨模态交互中的角色问题,并提出了一个跨模态差异交互网络(Cross-modality Discrepant Interaction Network,CDINet),它可以根据不同卷积层的特征表示的不同对两种模态的依赖关系进行差异化建模。
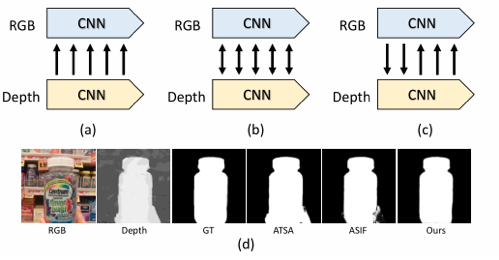
图1 不同交互模式示例
具体来说,本方法设计了两个关键组件来实现有效的跨模态交互:1)RGB引导的细节增强模块(RGB-induced Detail Enhancement,RDE)利用RGB模态在低级编码阶段的细节特征增强深度特征;2)深度引导的语义增强(Depth-induced Semantic Enhancement,DSE)模块将深度特征所表达的目标位置信息和内部一致性传递到高级编码器阶段的RGB分支。通过上述两个模块便可在编码阶段完成充分的跨模态特征交互,解码阶段则重点关注于使用得到的多级编码特征进行分辨率的恢复以生成高分辨率的显著图,为此本工作设计了一种密集解码重构结构(Dense Decoding Reconstruction,DDR),该结构通过结合多级编码特征构建语义块,对传统跳跃连接结构进行了改进。
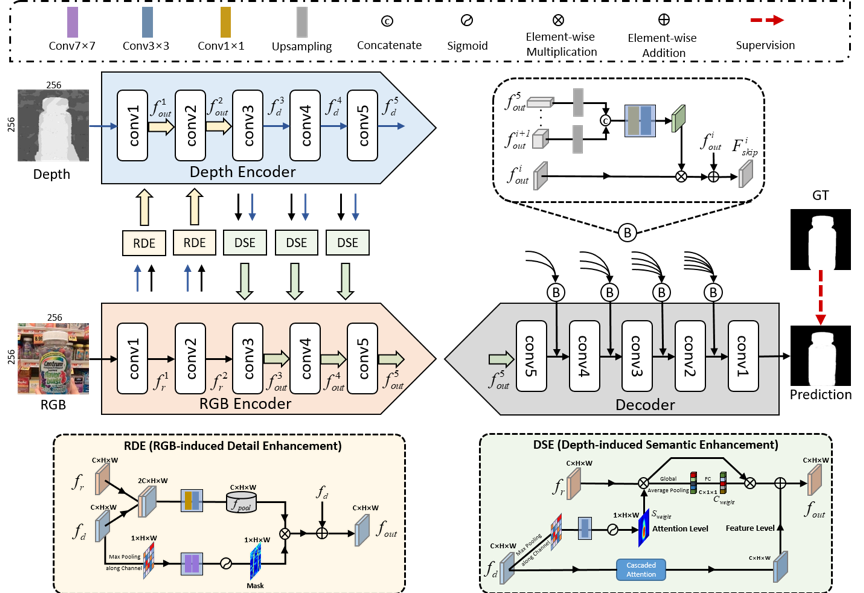
图2 网络框架图
本方法在五个基准数据集上进行了实验验证。表1展示了本文提出的方法与一些近期工作的定量比较结果,可以看出我们的方法在所有数据集上都取得了有竞争力的结果。图3展示了一些可视化的比较结果,可以看出本文所提出的方法在许多有挑战性的场景下,都取得了比较理想的检测效果。在显著性目标与某些非显著性物体具有相似的深度值的情况下(如第一幅图像和第四幅图像),我们的方法也能准确地将显著性目标分离出来,并且具有更好的目标内部一致性,验证了所提出方法的有效性。
表1 与其它方法的定量比较结果
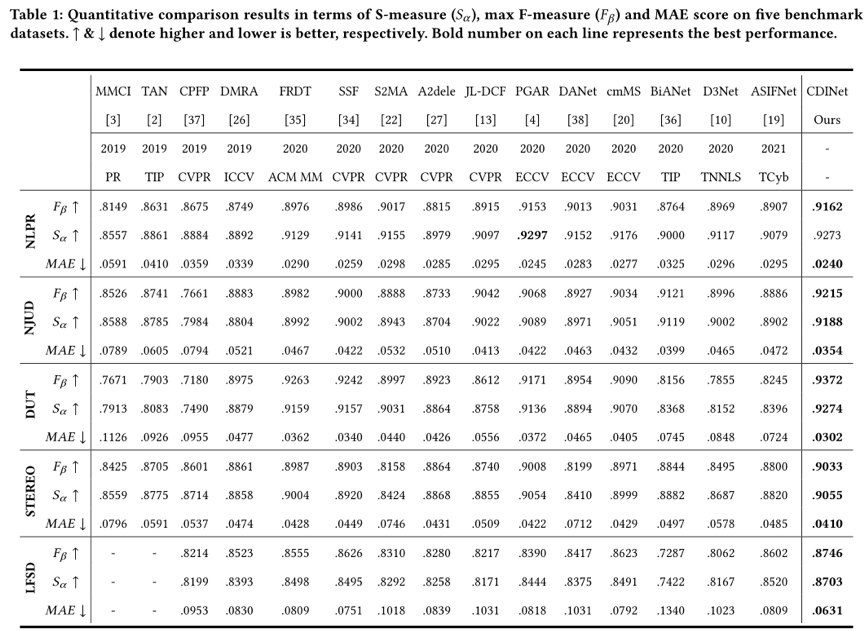

图3 与其它方法的可视化比较结果
03
ABPNet: Adaptive Background Modeling for Generalized Few Shot Segmentation
作者:董凯旗,杨威*,徐振博,黄刘生,余志冬
单位:中国科学技术大学计算机科学与技术学院
邮箱:
qubit@ustc.edu.cn (杨威)
论文:
https://dl.acm.org/doi/10.1145/3474085.3475389
代码:
https://github.com/AlexKaiqi/GFSS/
*通讯作者
引言
小样本语义分割任务要求模型在有充分标注数据的基类上进行训练,而在只有少量标注样本的新类上测试。现有的研究只要求支持样本与查询样本包含相同的类别,且只同时区分一个或者很少量的类别,这使得任务退化为显著目标分割,未能强调区分不同的类别。
本文研究的广义小样本语义分割任务在设定上更具一般性,不对查询样本中类别做任何限制,且测试时要求同时区分出已知类与新类。在全面的实验中,我们观测到广义小样本语义分割模型对新类的预测精度较差,且十分偏向于背景类,这引起了我们的好奇,并由此设计了ABPNet。
方法概述
ABPNet模型基于度量学习,首先计算每个类别的原型,然后通过余弦距离比较得出分类结果,其结构如图1所示。对于前景类,由一组可学习参数表示基类的特征,并从支持样本提取新类的特征。针对少量样本提取特征不准确的问题,本文使用了一个神经字典来学习先验知识,并增强前景类的分类特征。
由于背景类比较特殊,虽然广义小样本语义分割任务中训练数据不包括新类,但是图片有可能包含这些类,只是没有被标注出来。因此,训练过程中的背景类与测试时的背景类含义并不相同,将背景类当作一个恒定不变的已知类处理并不恰当。并且模型训练时的优化目标是缩小类内方差,这使得背景类的特征相互靠近,给测试阶段区分出其中的新类造成了困难。有鉴于此,本文提出了自适应背景类建模,将背景类表示为全集与前景类集合的差集并动态地计算。图2展示了两种背景类建模方法的区别,差集由一个集合函数实现,并通过一组参数表示全集。
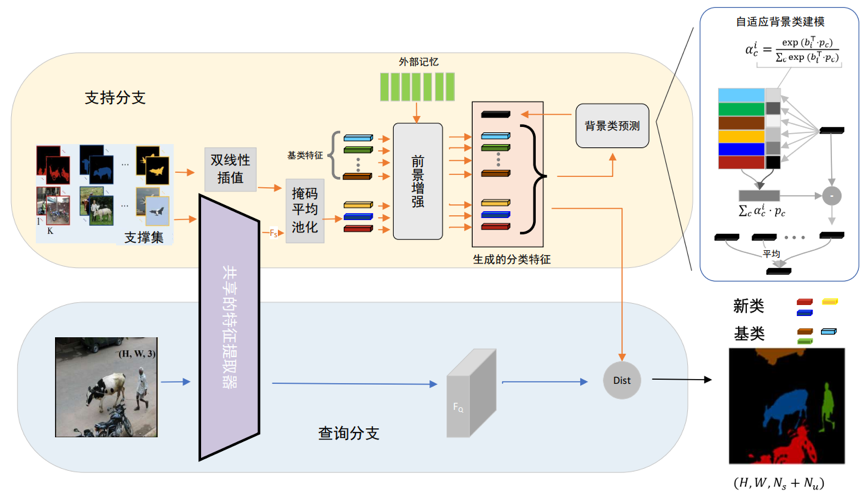
图1 ABPNet模型结构
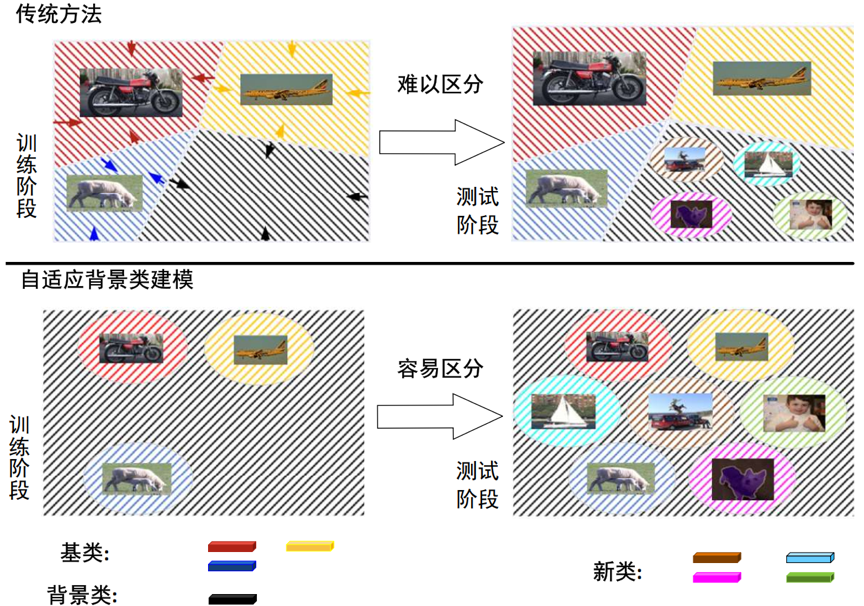
图2 自适应背景类建模与传统方法的区别示意
实验结果
实验结果表明,本文提出的自适应背景类建模在测试阶段能够根据基类和新类计算出合适的背景类,并保留了更多区分新类的信息。本文提出的方法在PASCAL和COCO数据集上取得了不错的提升,尤其是新类。本文还在小样本语义分割任务上做了对比,同样取得了优秀的表现。下面是相关的实验数据:
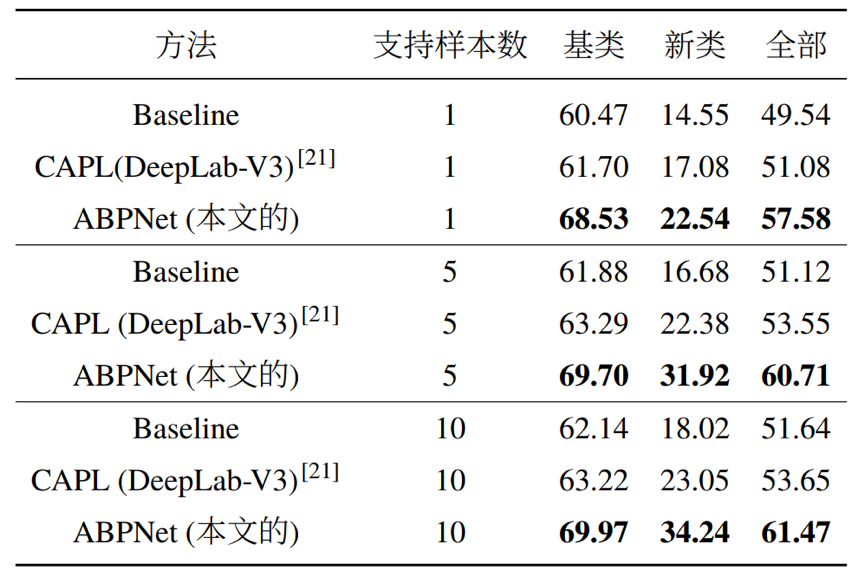
PASCAL实验结果
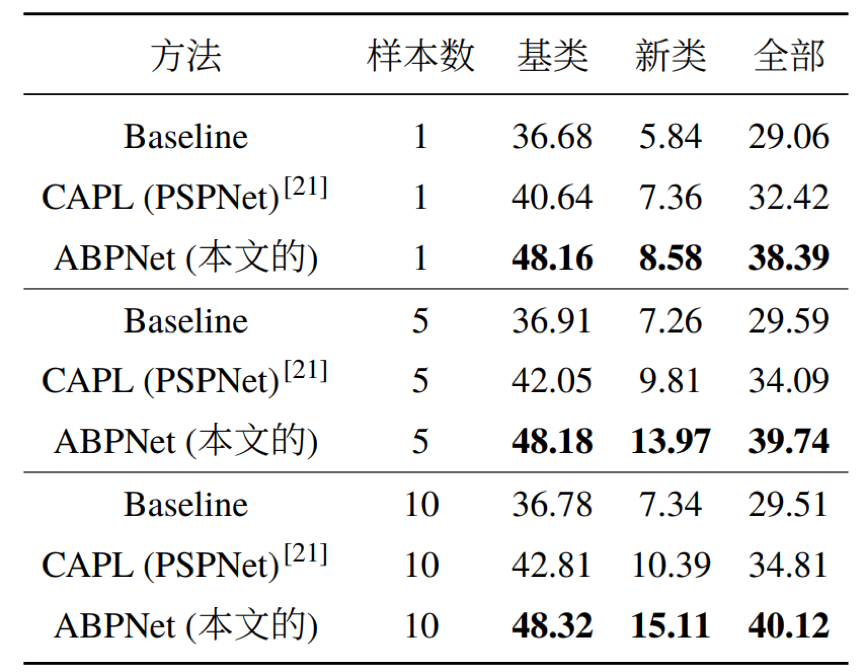
COCO实验结果
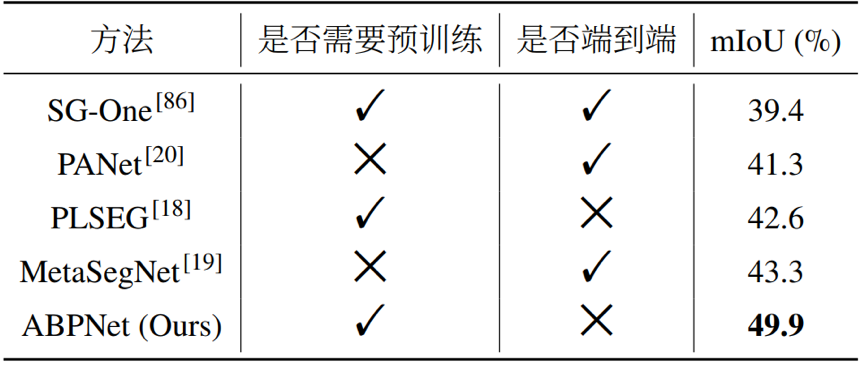
小样本语义分割任务实验结果
04
Occlusion-aware Bi-directional Guided Network for Light Field Salient Object Detection
面向光场显著性物体检测的遮挡感知双向指导网络
作者:荆栋、张硕、丛润民、林友芳
单位:北京交通大学 计算机与信息技术学院 交通数据分析与挖掘北京市重点实验室
邮箱:
20120370@bjtu.edu.cn;
zhangshuo@bjtu.edu.cn;
rmcong@bjtu.edu.cn;
yflin@bjtu.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475312
代码:
https://github.com/Timsty1/OBGNet
光场是在相机平面上密集等间隔地对一个场景采样得到的多视角图,且像素在不同视角间的视差体现了场景的深度信息。光场显著性检测是指在像素层面上将光场中心视角中最引人注目的物体标注出来。光场显著性检测任务的难点在于如何从光场中提取场景的深度信息,并利用它来更好地处理显著性检测任务
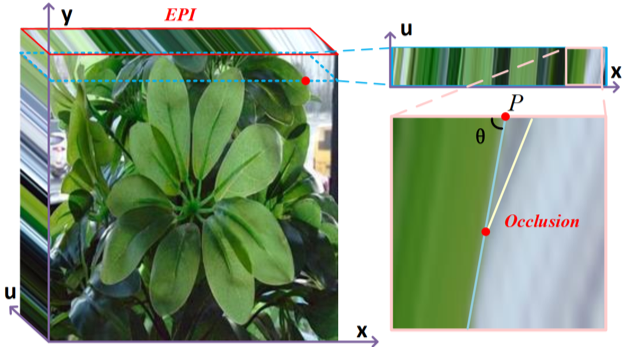
图1 光场对极平面图像中点的深度信息和遮挡信息的图解。
现存的大多数光场显著性检测算法基于光场重聚焦得到的聚焦序列来实现。然而,由于聚焦切片内部存在模糊区域,且聚焦切片间会互相干扰,聚焦序列难以提供清晰准确地深度信息。相比之下,如图1所示,光场对极平面图像将像素映射为一条斜线,且像素斜线的斜率代表了该像素的深度,斜线相交代表此处发生了遮挡,清晰地体现了场景的深度和遮挡信息。因此,我们选择从光场对极平面图像中提取场景的深度遮挡信息。
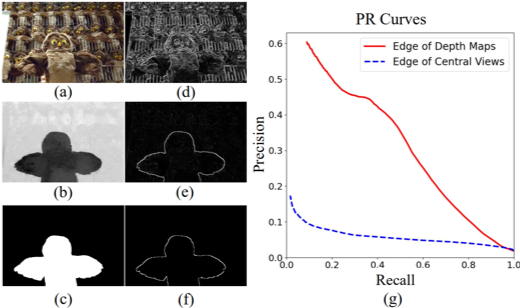
图2 颜色边缘、遮挡边缘及显著物体边缘样例。(a)(b)(c)分别是中心视角、深度图、显著物体检测真值图,(d)(e)(f)是与之一一对应的梯度图。(g)是遮挡边缘以及颜色边缘相较显著边缘的PR曲线。
为了探索场景深度遮挡信息与显著性检测的联系,我们在现有数据集上进行了统计分析。如图2中的样例所示,由于一个物体的深度往往是连续的或者几乎相同的,遮挡边缘,即深度不连续的区域,可以用来检测完整物体。此外,如图2中的PR曲线所示,在大多数场景下,相比于传统图像边缘,遮挡边缘与显著物体边缘的重合度更高。
因此,本文提出了一个遮挡边缘检测与显著物体检测双向指导的卷积神经网络来处理光场显著性检测问题。如图3所示,我们的模型主要包含三部分:基于对极平面图像的遮挡提取模块、基于中心视角的骨干网络、双向指导流。在遮挡提取模块,我们设计了一个基础残差编码模块,可以交替地在对极空间和图像空间维度提取深度遮挡特征。遮挡提取模块的输出是显著性物体的边缘图预测。骨干网络从中心视角进行高层特征提取,并经过一个解码器生成初始显著性物体预测。双向指导流用来将显著边缘预测和显著物体预测两个任务结合起来:初始显著性物体预测可以帮助深度遮挡特征抑制与显著物体无关的背景区域;显著边缘预测图可以增强显著物体预测编码过程中对显著边缘区域的关注,从而生成拥有精细边缘的预测。最后,高层特征被再次编解码得到了最终的显著物体预测结果。
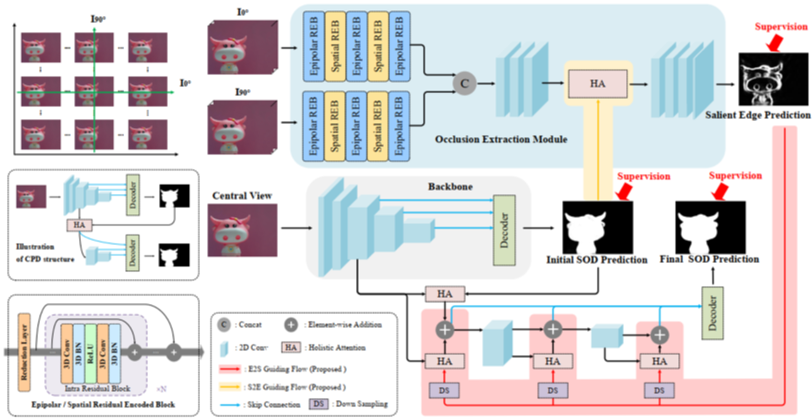
图3 本文所提出的模型
如表1所示,在现存最大的光场显著性检测数据集DUTLFv2上的实验结果表明,所提出的方法在多项指标上都优于其他最先进的方法。从图4的可视化结果可以看出,所提出的模型产生的结果不仅划分准确,且拥有清晰的边缘。
表1 在DUTLFv2数据集上的横向对比结果
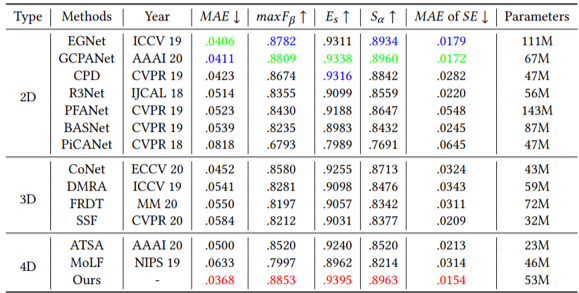

图4 在多类场景下的可视化对比结果
05
R-GAN: Exploring Human-like Way for Reasonable Text-to-Image Synthesis via Generative Adversarial Networks
作者:乔滟媛1,陈奇1,邓超睿1,丁宁2,齐元凯1,谭明奎2,任新成3,吴琦1*
单位:1阿德莱德大学,2华南理工大学,3延安大学
邮箱:
yanyuan.qiao@adelaide.edu.au
qi.chen04@adelaide.edu.au
chaorui.deng@adelaide.edu.au
seningding@mail.scut.edu.cn
qykshr@gmail.com
mingkuitan@scut.edu.cn
xchren@yau.edu.cn
qi.wu01@adelaide.edu.au
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475363
一、引言
文本生成图像任务旨在对给定的文本描述生成相应的图像。随着生成对抗网络的兴起,文本生成图像任务已经取得了一定的进展。然而,这一任务依旧具有极大的挑战,这是由于文本描述中包含了丰富的语义信息,例如场景图像较为复杂,一个场景中涵盖多种物体,物体间有着不同的空间位置关系,即使是同类物体在外观上也会有一定的差异。因此,如何生成更加合理又逼真的图像成为一个重要问题。为了解决这些挑战,本文提出了一种模拟人类绘图的方式来文本生成图像的生成对抗网络R-GAN,正如人类画图时一样,他们首先会构建一个草图,大致确定要画的物体大小和位置,接着逐步细化内容如物体的形状,最后上色进行细节的刻画。
二、方法概述
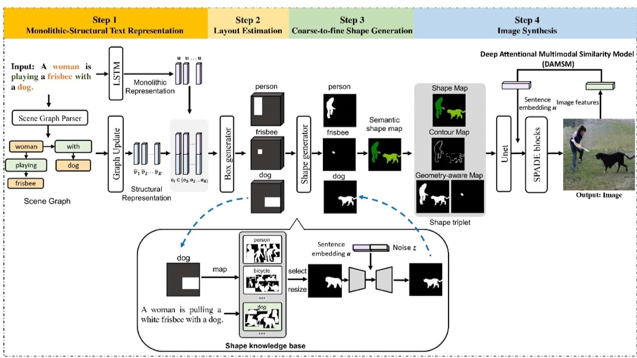
图1 本文所提出的R-GAN框架图
本文提出的R-GAN框架图如图1所示,主要由四个部分组成:文本表示、布局估计、从粗到精的形状生成和图像生成。首先,我们设计了一种整体-结构的文本表示方法,通过构建场景图将整个句子的整体特征和结构特征结合起来,捕获文本信息中包含的物体大小和空间位置关系。接着,在绘制草图时我们利用边界框生成一个包含各个物体大小和位置信息的粗略而合理的布局,然后根据边界框的类别和文本语义信息为不同的框勾勒出不同的形状。为了生成更加精细的形状,我们基于预先构建的形状知识库设计了一个从粗到精的形状生成器。此外,我们使用了形状边界梯度敏感的损失函数,重点关注物体形状的轮廓,从而生成边界更清晰完整的形状。最后,我们提出了一种多模态几何感知空间自适应生成器来生成目标图像,该生成器能够很好地保存给定形状的语义信息,生成真实合理的图像。
三、实验结果
本文提出的方法在MSCOCO数据集上的结果如表1所示,R-GAN相较于其他先进方法取得了更好的测评结果。图2展示了与其他先进方法的生成图对比。实验结果表明,R-GAN在定量和定性度量上都是有效的,可以在复杂描述的基础上生成逼真、合理的图像。
表1 实验结果
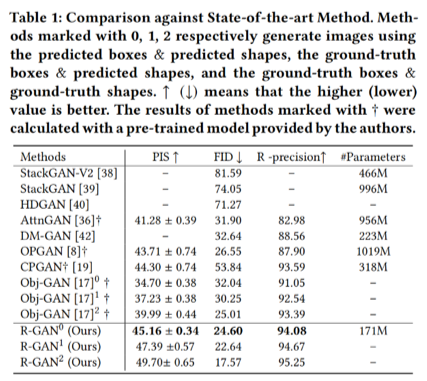

图2 生成图像对比图

编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜


