人类穿着数据集3DPeople发布,微软建立人工智能商学院 | AI一周学术

大数据文摘专栏作品
作者:Christopher Dossman
编译:Jiaxu、fuma、云舟
呜啦啦啦啦啦啦啦大家好,拖更的AI Scholar Weekly栏目又和大家见面啦!
AI Scholar Weekly是AI领域的学术专栏,致力于为你带来最新潮、最全面、最深度的AI学术概览,一网打尽每周AI学术的前沿资讯。
周一更新,做AI科研,每周从这一篇开始就够啦!
本周关键词: 3D模拟、视觉识别、聊天机器人
本周热门学术研究
Sim2Real联合加强转换
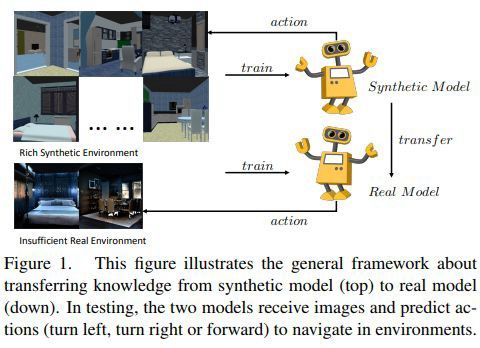
在现实世界中,为训练机器人进行有效的导航,大量训练数据是必不可少的。也就是说,为训练机器人而获取足够的现实数据是非常昂贵和劳动密集的。人工模拟的学习环境可以大大提升现实世界中导航训练的便捷性,但仍然无法与真实的环境相匹配。在强化模型中调整视觉表示和策略行为的映射,是解决这一难题的有效方法。
目前一种新的结合了调整视觉表现和策略行为以绘制环境和策略相互影响的方法已经发布。该方法实现了对抗特征的适应,从而实现了视觉表达的转换和对行为策略的模仿策略。在没有额外人工标注的情况下,该方法的性能将超过现有技术20%。
潜在应用及影响
室内机器人的导航问题是机器人现实应用的关键。这种新方法将使机器人替代人类的许多应用程序受益,例如巡逻,房屋清洁,包裹递送等。
原文:
https://arxiv.org/abs/1904.03895
从单一图像中对人类穿着进行3D几何模拟
最新研究引入了一种新的机制,用于对穿着衣物的人进行建模并从单个图像预测其几何形状。 研究贡献包括一个称之为3DPeople的新数据集,一个新的形状参数化模型和一个预测形状的端到端生成模型。
3DPeople数据集是一个大型综合数据集,其中包含了80个人物以不同穿着进行70种行为活动的250万个高精度图像。
数据集通过将脸谱、骨架、深度、普通图像和光线变化进行分割注释,使其适用于无数的任务。

为生成图像,研究人员提出了一种新的球形区域保持参数化算法,该算法是对现有球形图的改进,球星图倾向于收缩细长的身体部位,造成几何图像不完整的问题。
最后,生成网络被用于以端到端的方式生成有穿着的人的几何图像。该方法为原始图像和合成图像中的身体姿势和衣物形状的捕获提供了良好的解决方案。
潜在应用及影响
这项研究成果对优化深度学习构建穿戴衣物的人体模型重建有很大的潜在推进作用。 此外,它还提供了进一步可以扩展到视频、几何图像正则化方案、分割和3D重建集成的研究,因为这些领域都可以从3DPeople数据集中获益。
原文:
https://arxiv.org/abs/1904.04571
体现视觉识别
对于具体的代理来说,了解他们的环境,提高他们的视觉识别能力以及不同于最短路径的战略移动路径至关重要。体现视觉识别(EVR:Embodied Visual Recognition)即是一种新的方法,使体验者可以在3D环境中动态移动,以便对特定目标对象进行适当的视觉识别。
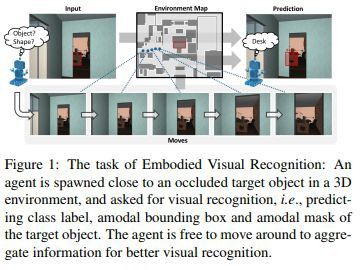
代理在靠近被遮挡目标对象的三维环境中实例化,并可在环境中自由移动以执行对象分类、对象定位和l对象分割。 为了实现这一切,研究人员开发了一种新的模型(Embodied Mask R-CNN),供学习者战略性地提高他们的视觉识别能力。
该模型已经在House3D环境下进行了评估,结果表明,体验者可以通过EVR实现更好的视觉识别性能。
潜在的应用及影响
对于场景理解和准确的导航任务而言,视觉体验是重要的。 而通过提出对象识别,模式感知,定位和分割三大子任务,EVR方法无疑具有推动下一代视觉系统的巨大潜力。
原文:
https://arxiv.org/abs/1904.04404
多混合机器人协作的增强三维映射
为了改善USAR环境,并在此情况下增强机器人系统,研究人员提出了一种在单目视觉点云(UAV)中基于平面定位激光点云(UGV)的新方法。
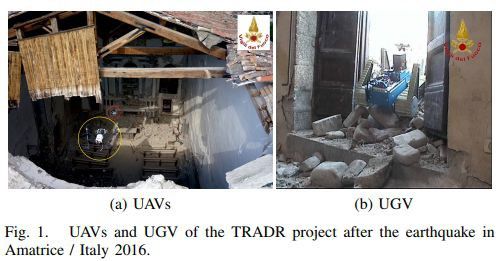
来自无人驾驶飞行器(UAV)和地面机器人(UGV)的传感器流融合在一个连续的地图中。然后使用UAV相机数据生成3D点云,其与由UGV处的滚动2D激光扫描仪产生的3D点云混合。配准方法基于从点云提取的相应平面段的匹配。
基于训练结果,全局优化的定位方法呈现出了优良的结果。如果可能,用户可以实施GPS坐标以支持本地化。
潜在用途和影响
这项研究可能使特定团队(机器人和人类)能够多次逐步了解特定的灾难地点,从而能够了解如何有效地改善团队合作。该方法还具有挽救生命的巨大潜力,同时会推动无人机、UGV导航、绘图和协作等领域的发展。
原文:
https://arxiv.org/abs/1904.04362
其他爆款论文
弱监督的白色和灰色3D物质分割脑超声。
https://arxiv.org/abs/1904.05191
自我中心RGB相机的原始图像序列中识别3D手和物体相互作用的框架。
https://arxiv.org/abs/1904.05349
使用卷积神经网络在杂乱环境中对局部对象进行三维物体实例识别和姿态估计。
https://arxiv.org/abs/1904.04854
多机器人系统的碰撞感知任务分配。
https://arxiv.org/abs/1904.04374
一种用于小目标运动检测的新型视觉系统模型(STMD +)
https://arxiv.org/abs/1904.04363
AI新闻
随着聊天机器人,机器人和头像的出现,人工智能开始使娱乐业成为一个万亿美元的经济体。
https://www.forbes.com/sites/cognitiveworld/2019/04/08/ai-plus-entertainment/#762971f35493
人工智能正在对保险行业进行重塑。
https://www.nytimes.com/2019/04/10/opinion/insurance-ai.html?rref=collection%2Ftimestopic%2FArtificial%20Intelligence
微软最近成立了一所专注于人工智能战略、文化和责任的商学院。
https://blogs.microsoft.com/ai/ai-business-school/
想知道PepsiCo使用人工智能和机器学习取得成功的诀窍吗?
https://www.forbes.com/sites/bernardmarr/2019/04/05/the-fascinating-ways-pepsico-uses-artificial-intelligence-and-machine-learning-to-deliver-success/#320ffeae311e

Christopher Dossman是Wonder Technologies的首席数据科学家,在北京生活5年。他是深度学习系统部署方面的专家,在开发新的AI产品方面拥有丰富的经验。除了卓越的工程经验,他还教授了1000名学生了解深度学习基础。
LinkedIn:
https://www.linkedin.com/in/christopherdossman/
志愿者介绍
后台回复“志愿者”加入我们