
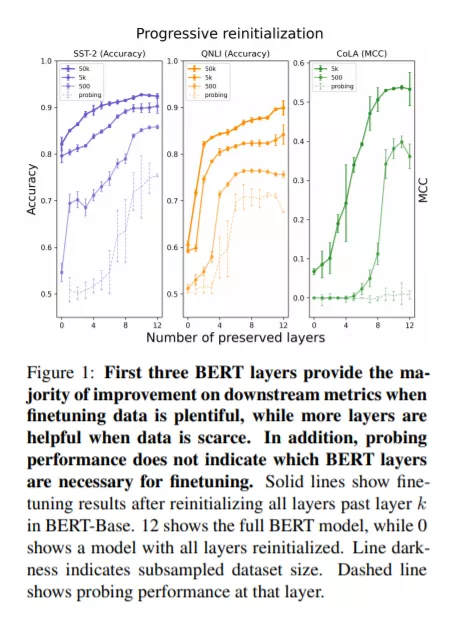
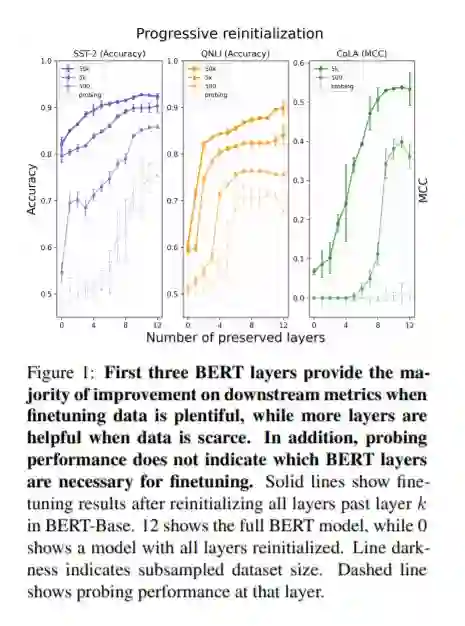
虽然探测是在预训练模型表示中识别知识的一种常见技术,但是尚不清楚这种技术是否能够解释像BERT这样在finetuning中端到端训练的模型的下游成功。为了解决这个问题,我们将探测与一种不同的可转移性度量进行比较:部分重新初始化的模型的微调性能的下降。该技术表明,在BERT中,对下游粘合任务具有高探测精度的层对这些任务的高精度来说既不是必要的,也不是充分的。此外,数据集的大小影响层的可移植性:一个人拥有的精细数据越少,BERT的中间层和后中间层就越重要。此外,BERT并没有简单地为各个层找到更好的初始化器;相反,层次之间的相互作用很重要,在细化之前重新排序BERT的层次会极大地损害评估指标。这些结果提供了一种理解参数在预训练语言模型中的可转移性的方法,揭示了这些模型中转移学习的流动性和复杂性。
成为VIP会员查看完整内容
相关内容

专知会员服务
36+阅读 · 2020年5月20日
Arxiv
20+阅读 · 2019年12月19日
Arxiv
3+阅读 · 2019年8月22日
相关VIP内容
专知会员服务
36+阅读 · 2020年5月20日
相关资讯
相关论文
Arxiv
20+阅读 · 2019年12月19日
Arxiv
3+阅读 · 2019年8月22日