CMU杨植麟等人再次瞄准softmax瓶颈,新方法Mixtape兼顾表达性和高效性
选自arxiv
作者:杨植麟、Thang Luong等
机器之心编译
参与:魔王、杜伟
2017 年,杨植麟等人提出一种解决 Softmax 瓶颈的简单有效的方法——Mixture of Softmaxes(MoS)。但该方法成本高昂,于是最近杨植麟等人再次瞄准 softmax 瓶颈问题,提出兼顾表达能力和高效性的新方法 Mixtape。

论文链接:https://papers.nips.cc/paper/9723-mixtape-breaking-the-softmax-bottleneck-efficiently.pdf
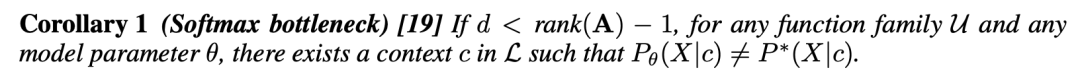
 。
但是,正如论文 [19] 所述,该公式会导致低秩表示,因为它仍然使用公式 (1) 中的矩阵分解。
。
但是,正如论文 [19] 所述,该公式会导致低秩表示,因为它仍然使用公式 (1) 中的矩阵分解。
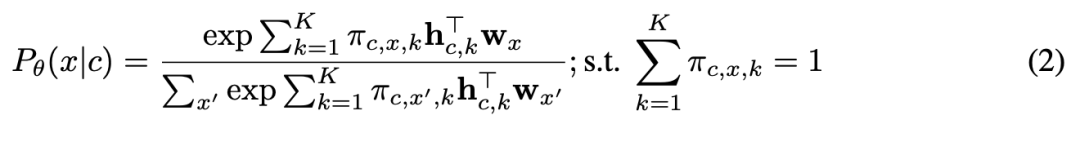
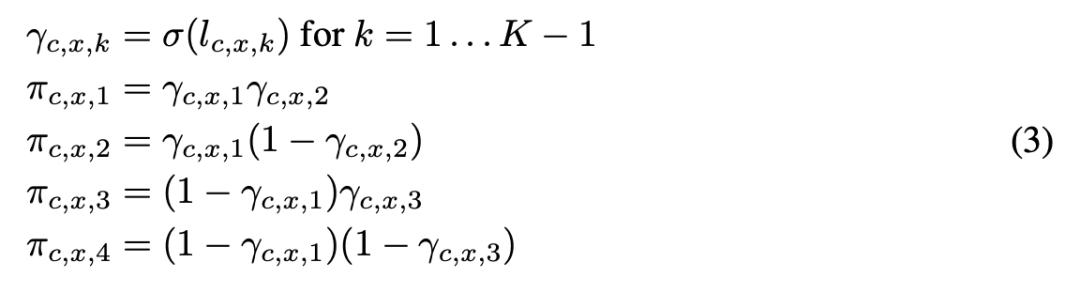
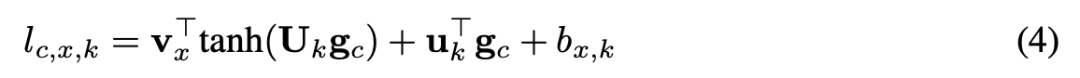


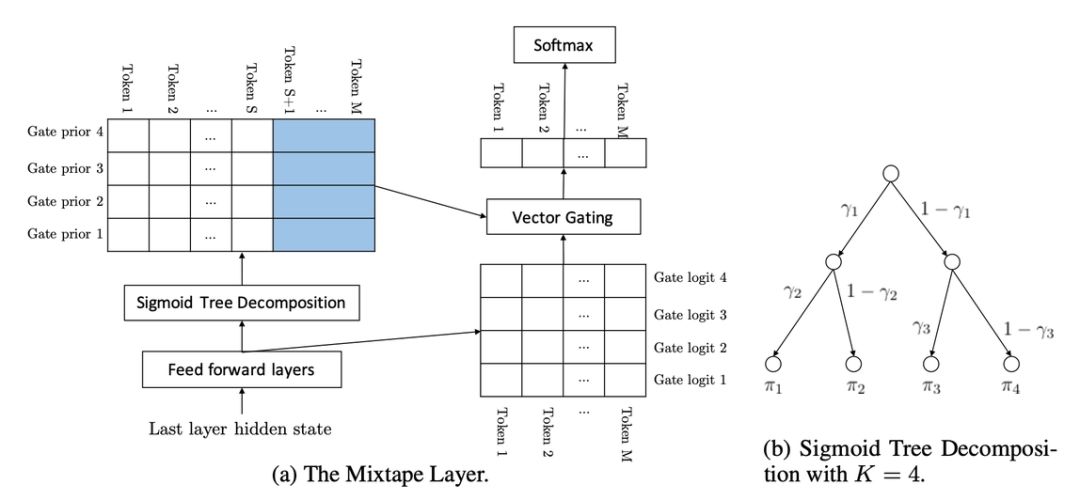
给出最后一层的隐藏状态 g_c,使用公式 (5) 计算语境嵌入 h_c,k;
对每个高频 token x,使用公式 (4) 计算预激活门控先验 l_c,x,k;
对于所有低频 token,使用公式 (6) 计算预激活门控先验 l_c,x,k;
使用 sigmoid 树分解,计算公式 (3) 中的门控先验 π_c,x,k;
使用向量门控,利用公式 (2) 获得下一个 token 的概率。

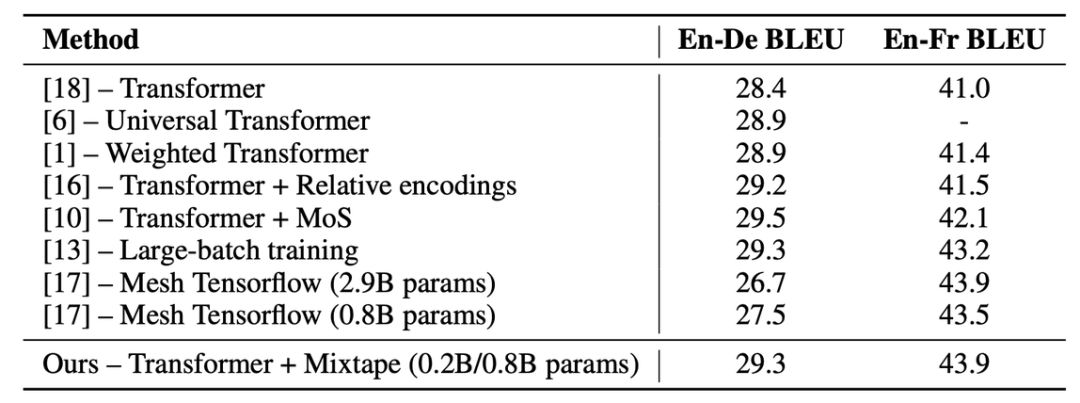
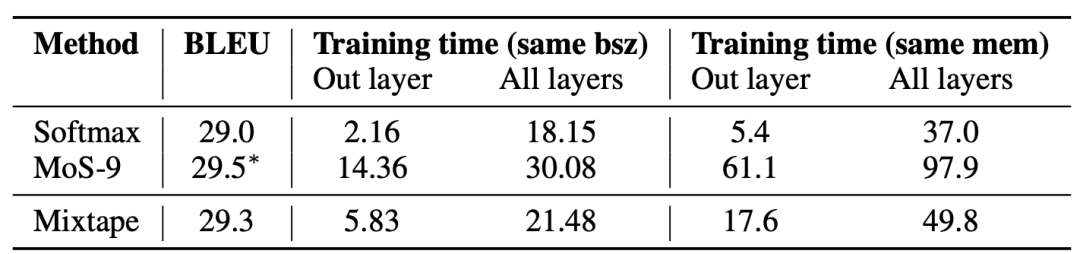
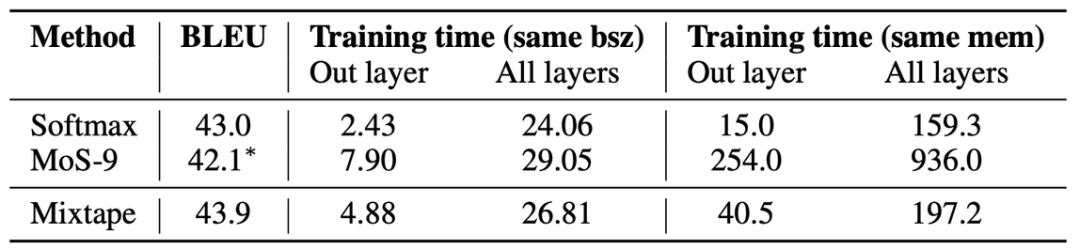
Mixtape 层打破 softmax 瓶颈,从而改进了当前最优的机器翻译系统;
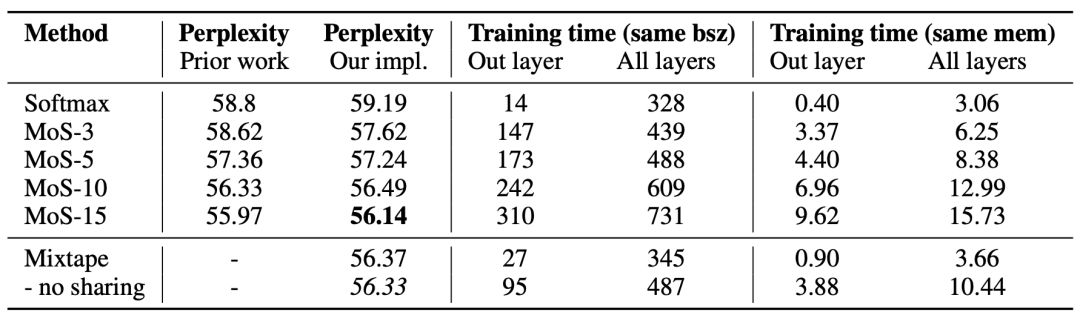
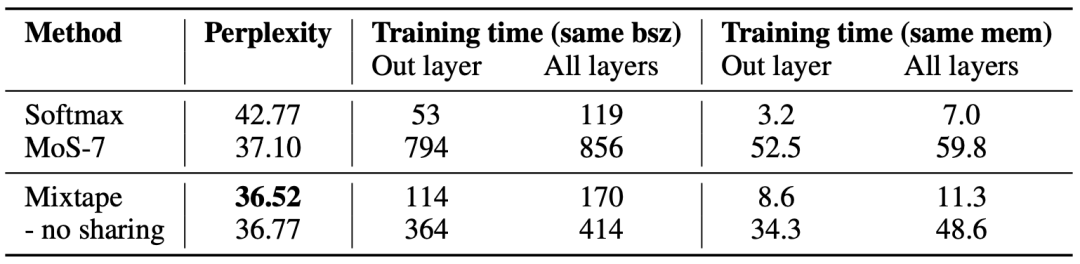
研究者对比了 Mixtape、MoS 和 softmax 的困惑度、翻译质量、速度和内存约束,证明 Mixtape 能够在效果和效率之间做好权衡;
控制变量实验证明了门控共享的优势。

登录查看更多
相关内容

专知会员服务
60+阅读 · 2020年6月28日



相关VIP内容
专知会员服务
60+阅读 · 2020年6月28日
相关资讯
相关论文