Fully-Convolutional Siamese Networks for Object Tracking论文笔记
SiamFC原文地址:https://arxiv.org/abs/1606.09549
project地址:http://www.robots.ox.ac.uk/~luca/siamese-fc.html
github:https://github.com/bertinetto/siamese-fc
一、主要贡献
第一个使用ILSVRC15数据集训练端到端网络进行视觉目标跟踪的算法;
真正提升了使用深度学习技术进行目标跟踪时的算法速度,并且在多个benchmark上达到了良好的效果;
在这篇论文的基础上,17、18年顶会上涌现了很多基于双胞胎网络做跟踪的文章,并且VOT17/VOT18的速度第一名都是基于Siam网络的方法,精度也在前列,证明了利用论文思想做跟踪的有效性;
二、算法成功原因分析
大量数据使得深度学习技术和相似性学习思想应用在跟踪变得可能:
传统跟踪方法,利用当前视频中的数据学习一个相对简单的tracker或者叫表观模型并在跟踪过程中在线更新,缺点显而易见,只使用了当前视频的数据,难以学习一个泛化能力强的tracker。
基于深度学习技术的跟踪虽然能学习很鲁棒的特征,将特征提取后与原方法结合或通过SGD方法微调预训练过的网络模型提取特征再与原方法结合,但它需要大量的有监督数据且速度一般都很慢,这两点阻碍了深度学习方法和传统跟踪方法结合。
SiamFC方法第一个使用ILSVRC15数据集中的视频数据训练了一个端到端的全卷积双胞胎网络进行跟踪,速度快、精度有竞争力,可以说是给出了一个范例,克服了上述两点阻碍。
(ILSVRC15即2015 ImageNet Large Scale Visual Recognition Challenge。ILSVRC15中为新引入的object detection from video challenge准备的video dataset,包含更大范围、更多场景的视频,且目标与现存的tracking benchmark不同,防止使用tracking的benchmark而产生有争论的过拟合的结果。此video dataset中包含4500个视频,作者筛选了其中的4417个视频进行网络的训练。要知道,现存的VOT、OTB等总共包含的视频都不到500个);
全卷积的网络结构:同一时期涌现了很多训练端到端网络进行跟踪的方法,比如GOTURN、SINT等等,但大都包含全连接层,使得接受输入尺寸受限,且全连接结构破坏了特征的空间结构,直接回归bounding-box坐标的方式,对网络训练要求更高,因为这样需要训练数据包含目标在图像上任意位置的情况。而采用全卷积情况会好很多,而且参数少、模型小、速度快;
三、网络结构及深度相似学习
所谓相似学习就是学习一个函数f(z,x)可以比较输入模板z和待测图像x的相似性,相似性高输出高响应,相似性低输出低响应。以往限制相似学习应用在跟踪领域的一个问题是,训练数据不够多。但ILSVRC15中的视频数据解决了这个问题。
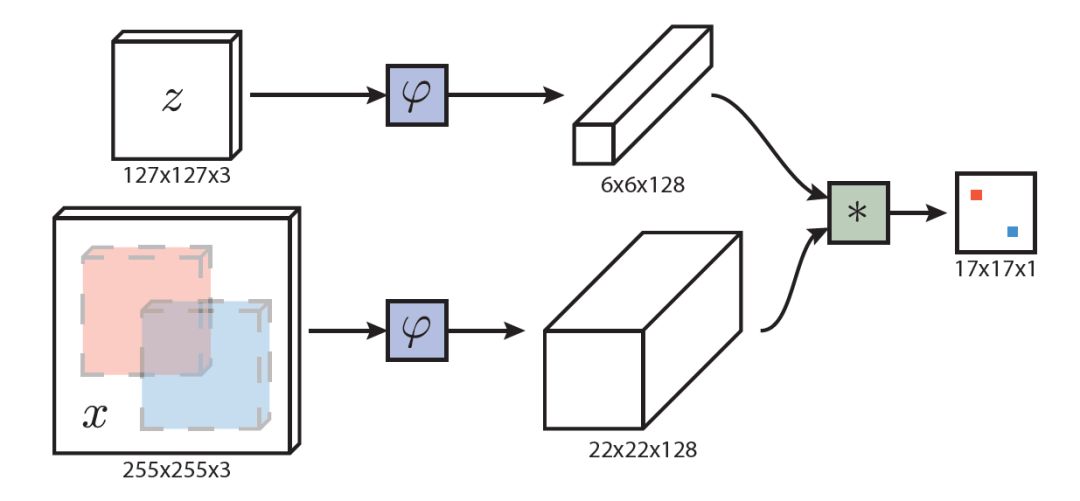
图1 SiamFC网络结构
SiamFC使用卷积神经网络实现这种思想,如图1所示,SiamFC分上下两路,上路输入模板z,下路输入待测图像x,ψ是两个一模一样的CNN网络,也可以理解为特征提取器。两路特征提取完毕后,将两路特征输入进一种相似性度量方法g中,计算相似性,找到待测图像x中模板z在什么位置。在SiamFC中:
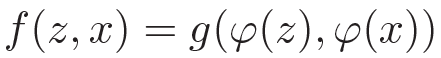
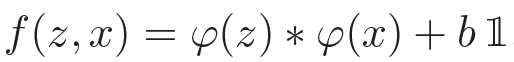
使用全卷积网络的好处是,可以扩大搜索区域x,使用ψ作用后的特征进行cross-correlation操作,类似于密集采样,但计算量小,速度快。
四、训练及其他细节
每个样本的损失用下式表示:
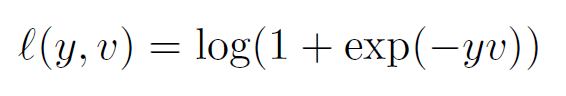
每一对数据,包含模板z和待测图像x,一个待测图像中包含多个样本,因此一对数据的损失表示为:
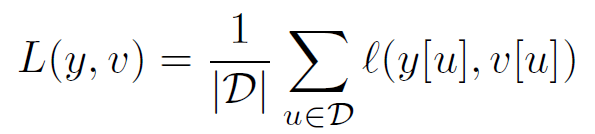
每对数据都来自同一个视频,但距离不超过T帧;理论上全卷积网络可以接受任意大小的图片输入,但作者为了训练的方便,固定了模板大小为127*127像素,待测图像大小为255*255像素。
训练时,假设bounding-box长宽为(w,h),获取sub_window时,先给各个边界补充一部分图像,p=(w+h)/4,取得面积为(w+2p)(h+2p)的patch,再引入尺度因子s,使得s(w+2p)×s(h+2p)=127*127,正常图像这样就结束了。但若patch超出图像边界,则使用图像RGB通道均值补充patch到127*127大小。

图2 训练图像对
对待测图像来说,标签符合下式:
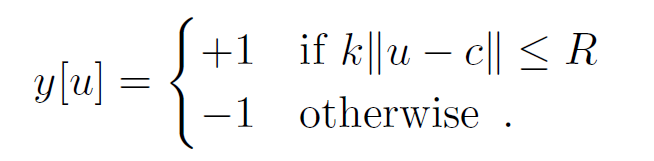
也就是说,距离中心R以内的样本都标记为正样本。待测图像以上帧位置为中心的好处是,难分样本很大的可能是分布在这周围的,有利于网络学习。ψ部分的CNN网络如图3所示:
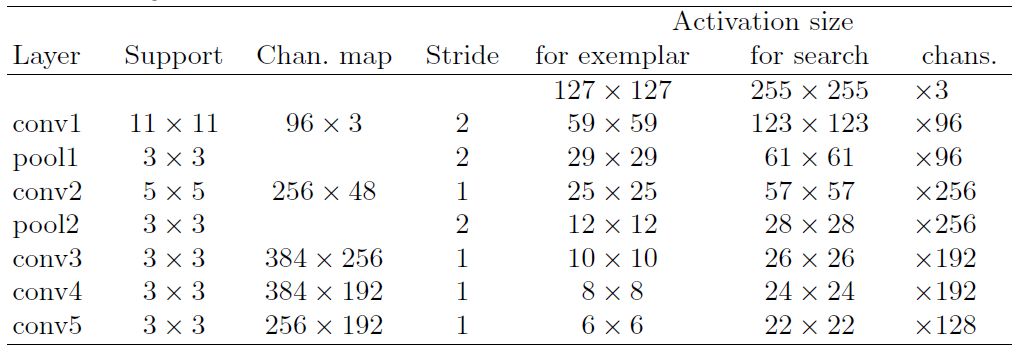
图3 CNN部分
四、实验
模板使用视频第一帧标注的且跟踪过程中模型不进行任何更新;
将最后17*17的结果进行双三次插值到272*272能更精确的定位目标;
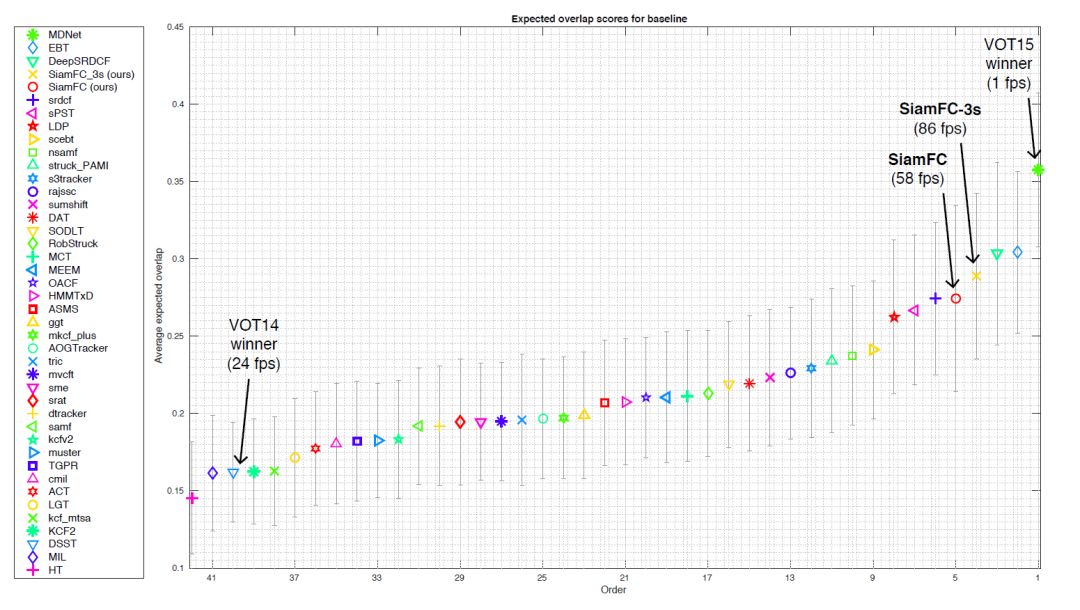
在3种尺度和5种尺度上寻找目标的速度为86FPS和58FPS;
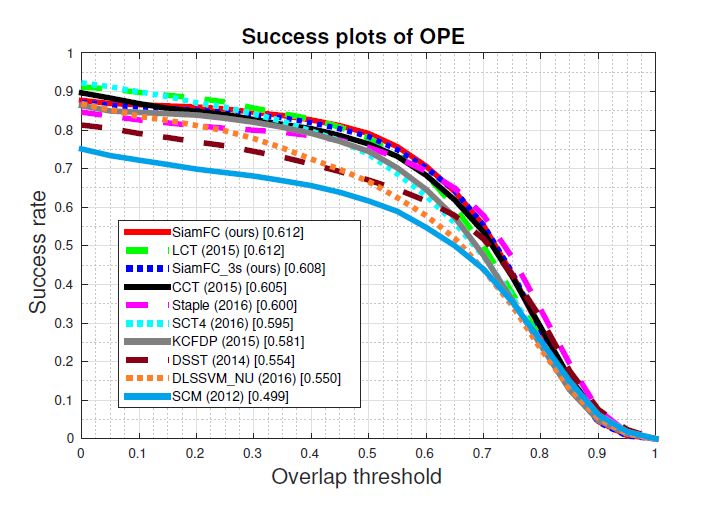
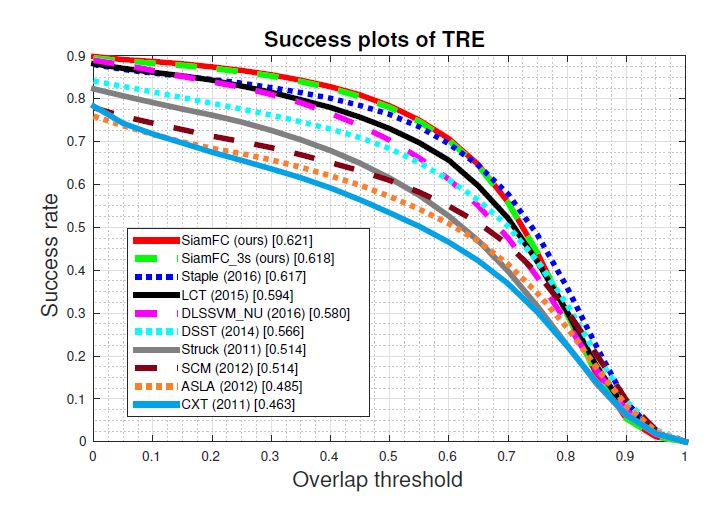
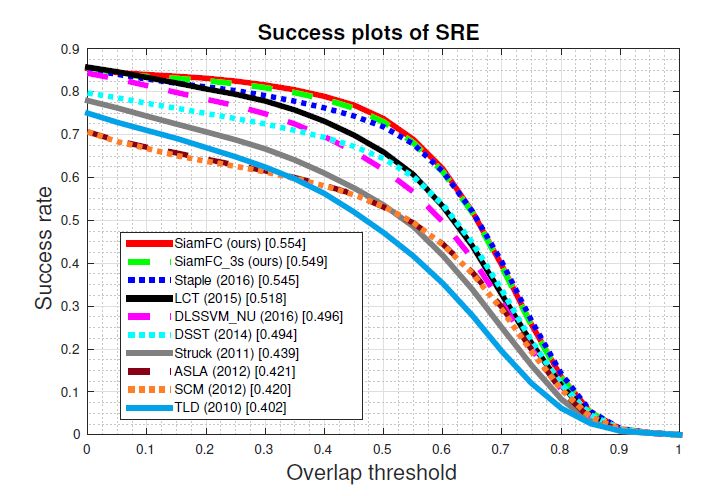
OTB2013
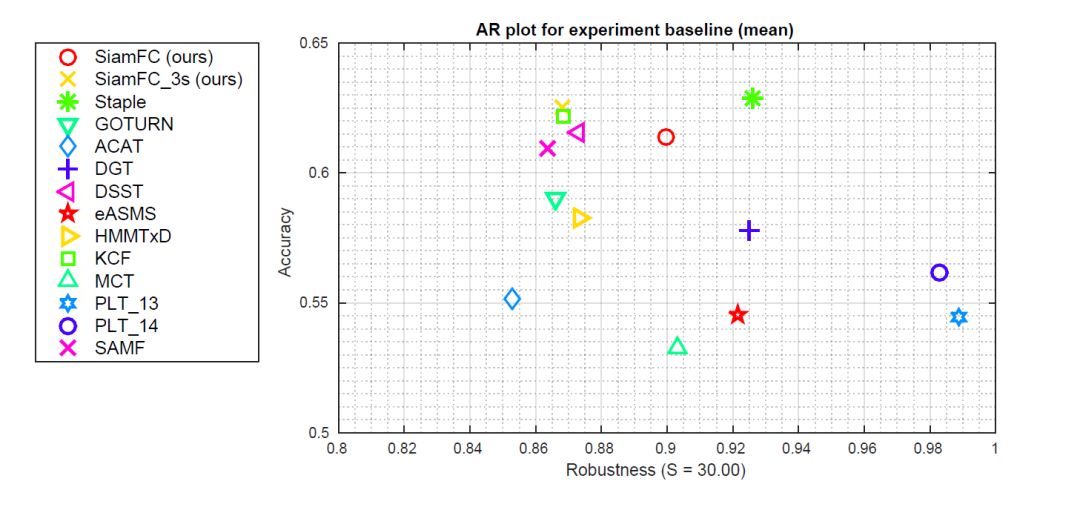
VOT2014
VOT2015